Aleksandrov A.I., Grakovski A.V., Kheifets E.M.
Latvia, Riga, Transport and Telecommunications Institute, e-mail: eugene@mail.eunet. lv
APPLICATION OF SIGNAL MORPHOLOGY IN INTELLIGENT
SISTEM OF INFORMATION PROCESSING
Abstract. A problem of reading of handwritten text is considered by intelligent system. The distinctive attributes of technology of reception graphic information are principle of holism (integrity of graphic image), synthesis of pattern and construction of stroke - code.
Александров А.И., Граковский А.В., Хейфец Е.М.
Латвия, Рига, Институт транспорта и связи, e-mail: eugene@mail.eunet.lv
ПРИМЕНЕНИЕ МЕТОДОВ МОРФОЛОГИИ СИГНАЛОВ В ИНТЕЛЛЕКТУАЛЬНЫХ СИСТЕМАХ ОБРАБОТКИ ИНФОРМАЦИИ
Аннотация. Рассматривается задача чтения рукописного текста интеллектуальной системой. Отличительные признаки технологии рецепции (восприятия) графической информации это принцип холизма (целостности графического образа ), синтез образца и построение штрих-кода.
Введение
Прикладная интеллектуальная система (ПИС) обработки информации проектируется под конкретные данные и объединяет различные алгоритмы обработки поступающих на ее вход данных. Обычно это устройство с памятью, на вход которого поступают конечные наборы двоичных символов. Методы рецепции (восприятия) последовательности нулей и единиц зависят от выбранной формы представления сигналов. В морфологии сигналов [1] под структурой подразумевается способ построения пространства и используется теоретико – категорное представление сигнала, суть которого заключается в том, что один математический объект определяется с помощью другого математического объекта. Структуре фрейма для представления данных, т.е. описанию устройства ''целого'' и взаимного расположения составных частей, посвящена, в частности, работа [2].
При разработке информационных технологий и проектировании ПИС используются различные алгоритмы. Это, прежде всего, классические алгоритмы цифровой обработки сигналов; WAVELET-методы; алгоритмы статистической обработки данных; комбинаторные алгоритмы; алгоритмы машинной графики и обработки изображений; алгоритмы вычислительной геометрии, включая применение фракталов; структурные (синтаксические) алгоритмы. Наибольшие надежды на успех в области искусственного интеллекта возлагаются на морфологические алгоритмы [3], генетические алгоритмы [4], алгоритмы клеточных автоматов, алгоритмы нечеткой логики и нейронные сети.
Все перечисленные алгоритмы имеют свои отличительные признаки, а соответствующее прилагательное в названии указывает на математическое представление сигналов, которое используется для обоснования обработки данных в ПИС.
Решение ''интеллектуальной задачи'' и обсуждение соответствующего алгоритма приводится на примере распознавания рукописного адреса на конверте. Здесь единицей обработки является кадр, например, изображение на экране дисплея. Задача ПИС узнать (или вычислить) изображенную на экране фигуру.
Технология обработки почтового конверта

Рис.1. Полутоновое изображение конверта и определение местоположения блока адреса (на рисунке выделен прямоугольником).


Рис.2. Выделение адреса (слева) и бинаризация (справа)

Рис.3. Структурный (синтаксический) анализ адреса
На рис. 1…3 приведена последовательность шагов цифровой обработки почтового конверта на этапе структурного анализа адреса. Аналогично обрабатываются и другие печатные материалы, например, избирательные бюллетени или опросные листы переписи населения. На этом этапе технологии определяется еще и тип текста: рукописный или машинописный. Это принципиальное разделение для систем искусственного интеллекта.
Независимо от типа текста для решения возникающих на каждом шаге задач результативно используются различные эвристические методы, а также морфологические алгоритмы на основе теории Серра-Матерона [3]. Если системы оптического распознавания образов (OCR) считывают (сличают) напечатанные адреса с достаточной надежностью, то чтение рукописных адресов является проблемной интеллектуальной задачей (и не только для машины). Более тридцати лет огромные усилия многих исследователей направлены на разработку устройств чтения рукописного текста. Подобные задачи можно считать своеобразной парадигмой в теории прикладных интеллектуальных систем (ПИС).
Задача узнавания и считывания рукописного текста
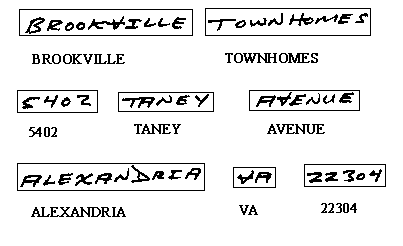
Рис.4. Распознавание адресата, номера дома и ее названия, названия города,
аббревиатуры штата и почтового индекса пункта доставки
На рисунке 4 образец адреса разделен на слова. Каждое слово записано в своем прямоугольнике и является представителем семантически значимой группы (т.е. элементом класса). У каждой группы есть название, например, ГОРОД, УЛИЦА, НОМЕР ДОМА и т.п. Число групп, как и число элементов в группе, конечно. На рис.4., например, выделены 8 групп. Решить задачу узнавания – это ответить на вопрос к какой группе относится текст в заданном прямоугольнике.
Следующая задача - это задача считывания. Считать (сравнить) рукописный текст с машинописным означает, что ''читая'' какой-либо программой графический образ внутри узнанного прямоугольника, требуется сличить его с элементом из выделенной группы и напечатать результат, например, шрифтом Times New Roman. Действительно, печать в заданном формате означает, что решена задача как узнавания, так и считывания.
Идея о цепном строении сигналов [2] порождает однозначный способ эволюции программ, где полный перебор всех вариантов не осуществим. Характерная форма кривой развертки определяет конфигурацию (взаимное расположение звеньев цепи) извилины. Эта пространственная кривая является посредником для построения ''штрих-кода'' геометрической информации, размещенной в кадре. Рецепция информации, т.е. узнавание объекта осуществляется с помощью штрих-кода, который является уникальным для графического образа и понятным для ПИС объектом. Для его построения целесообразно использовать идеи генетики и генетические алгоритмы [4]. Действительно, с помощью сконструированного фрейма каждому рукописному тексту в прямоугольнике ставится в соответствие конечный набор нулей и единиц. Различия в написании одного и того же текста приводят к различным наборам. Используя операторы отбора, мутации и кроссовера при обработке ''популяции'' можно строить генетический код для каждого элемента в классе. Этот код используется для указания файла, в котором хранится информация о распознаваемом объекте.
Заключение
Отличительные признаки рассматриваемой технологии следующие:
Объединение не работающих по отдельности идей и программная реализация технологии обработки данных приводит к результативной ПИС, способной решать конкретные интеллектуальные задачи.
Задача отбора и фильтрации данных, необходимых для результативной работы ПИС, и ее решение включается в качестве составной части в проблему ценности информации.
Литература
| Site of Information
Technologies Designed by inftech@webservis.ru. |
|