О РАЗРАБОТКЕ ЛИНГВИСТИЧЕСКОГО ПОДХОДА НА БАЗЕ ЛОГИКИ АНТОНИМОВ. СРАВНЕНИЕ С ЛИНГВИСТИЧЕСКИМ ПОДХОДОМ, ЛЕЖАЩИМ В ОСНОВЕ НЕЧЕТКОЙ ЛОГИКИ ЗАДЕ
Д.С. Фальков
ЦНИ Санкт-Петербургского государственного технического университета
Abstract - The principles of development of linguistic approach on the basis of antonyms logic which is continuous-valued logic maintaining all laws of classical logic are considered. The comparison of the presented linguistic approach with the one playing the central role in Zadeh fuzzy logic is carried out.
В своей статье [1] Л.А. Заде отмечает, что концепция лингвистической переменной (лингвистический подход) играет важную роль в приложениях нечеткой логики и отличает ее от других методологий, применяемых при решении задач в условиях нечеткости, неопределенности.
Как и нечеткая логика, логика антонимов (ЛА) относится к классу непрерывнозначных логик и, следовательно, есть основания думать, лучше, чем классическая логика подходит для описания окружающего мира. В отличие от классической логики, предлагающей грубую, черно-белую модель мира, ЛА отражает свойства “серого” мира, то есть учитывает, что реальный мир не черно-белый, а в какой-то степени черный, в какой-то белый.
Рассмотрим возможность построения лингвистического подхода (ЛП) на базе ЛА. В данной работе мы не будем приводить описание формального аппарата ЛА. Эту информацию, как и описание различных приложений можно найти, в частности, в следующих публикациях
[2, 3]. Одной из основных особенностей ЛА, как отмечено в работе [2], является тот факт, что в основе аппарата лежит понятие антонимической пары, понятие антонимов. В ЛА знакосочетание вида А, a А предлагается интерпретировать как пару противоположных свойств, например: здоровье-болезнь, горячее-холодное, черное-белое, и т.д. Очевидно, что можно давать оценку состояния объекта через оценку степени наличия (присутствия) у него противоположных свойств, например, оценивать степень здоровья, степень болезни человека. Знакосочетания вида Н[А], Н[a А] будем понимать как оценки степени наличия противоположных свойств у объекта изучения. Рассмотрим аксиому 3 ЛА, выражающую связь между Н[А], Н[a А]:Н[a А
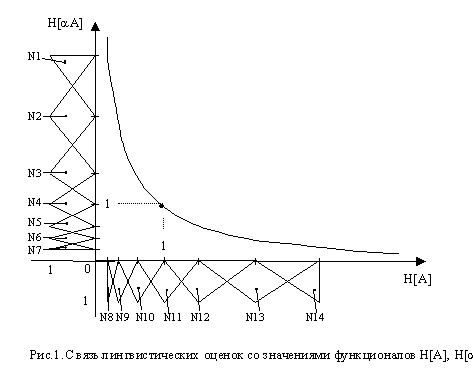
] = -log2(1-2H[A]). (1)Далее, упоминая Н[А] и Н[a А], всегда будем иметь ввиду, что они связаны формулой (1). Графически эта зависимость представлена на рис.1.
В основу построения ЛП положим следующие рассуждения. Для лингвистического выражения какого-либо свойства выберем соответствующую антонимическую пару, например: горячо-холодно,…,… Такие антонимические пары будут являться основой для построения лингвистических значений. Обратим внимание, что используемые антонимы носят качественный характер. Будем их также называть качественными лингвистическими оценками. Вообще далее будем отождествлять понятия лингвистическое значение и лингвистическая оценка. Для выражения количественной оценки степени наличия соответствующего свойства будем использовать количественные модификаторы типа: слегка, достаточно, очень, и т.д.
Лингвистические оценки, выражающие степень наличия у объекта того или иного свойства будем образовывать путем комбинации количественных модификаторов с элементами антонимической пары, например: очень горячий, слегка больной, достаточно сильный и т.д.
Обратимся к рис.1. На координатных осях, обозначенных Н[А], Н[a А] располагаются оценки степени наличия у объекта противоположных свойств
. Очевидно, что по смыслу А и a А - антонимы, а пара оценок Н[А], Н[a А], связанная уравнением (1) - синонимы. Можно также сказать, что Н[А], Н[a А] - координаты состояния объекта, а кривая (1) - кривая состояний объекта. Обратим также внимание на то, что оценки Н[А], Н[a А] являются координатами точки, делящей дугу (см. рис.1) на две части. Обозначим эти части дуги посредством А и a А соответственно. Видно, что числа Н[А], Н[a А] также отражают величины проекций дуг А и a А на соответствующие оси Н[А], Н[a А], а сами дуги А и a А - дополняют друг друга до всей кривой.особое внимание обратим на точку с координатами (1,1), которую естественно назвать точкой равновесия, так как она отражает состояние объекта, при котором оценки степени наличия противоположных свойств равны друг другу.
Теперь проанализируем, каким образом можно расположить различные лингвистические значения на координатных осях Н[А], Н[a А]. Рассмотрим какую-нибудь конкретную физическую величину, например, температуру объекта. В основу лингвистических оценок температуры положим антонимическую пару А– горячее, a А- холодное. Заметим, что оператору a можно поставить в соответствие отрицание НЕ. При этом отрицание НЕ, в отличие от его понимания в теории Заде, означает не “все остальное”, а переход к вполне определенному противоположному свойству (не горячее = холодное, и наоборот). Так как на оси Н[А] располагаются оценки степени наличия свойства “горячее”, то будем располагать на ней все лингвистические оценки, в которые входит термин “горячее” (аналогично для оси Н[a А]). Обратим внимание, что ось Н[А] можно разбить на две зоны и поставить им в соответствие два качественных понятия: для Н[А]I
[0, 1) - не горячее, для Н[А]I (1, ? ) - горячее. Аналогично для Н[a А]I [0, 1) - не холодное, для Н[a А]I (1, ? ) - холодное. Зоны с названиями “горячее” и “холодное” будем называть основными. При этом, например, если названия зон “не холодное” и “холодное” заменить соответственно на “горячее” и “не горячее”, то получим чередование качественных зон на осях с образованием замкнутого цикла.Теперь перейдем к процедуре расположения на осях лингвистических значений. Сформируем все возможные лингвистические значения (множество термов) с использованием качественных понятий - горячий, холодный; модификаторов - слегка, достаточно, очень; отрицания НЕ (еще раз обратим внимание на то, что здесь НЕ означает не “все остальное”, а переход к вполне определенному противоположному свойству). Сформированные лингвистические значения представлены в табл.1.
Таблица лингвистических значений
Таблица 1
А н т о н и м ы |
|||||
A |
a A |
||||
горячий |
холодный |
||||
H[A] |
очень горячий ( N1) |
H[a A] |
очень нехолодный ( N8) |
синонимы |
|
H[A] |
достаточно горячий ( N2) |
H[a A] |
достаточно не холодный ( N9) |
синонимы |
|
H[A] |
слегка горячий ( N3) |
H[a A] |
слегка не холодный ( N10) |
синонимы |
|
H[A] |
и не горячий и не холодный (нейтрал.) ( N4) |
H[a A] |
и не горячий и не холодный (нейтрал.) ( N11) |
синонимы |
|
H[A] |
слегка не горячий ( N5) |
H[a A] |
слегка холодный ( N12) |
синонимы |
|
H[A] |
достаточно не горячий ( N6) |
H[a A] |
достаточно холодный ( N13) |
синонимы |
|
H[A] |
очень не горячий ( N7) |
H[a A] |
очень холодный ( N14) |
синонимы |
|
Отметим, что на практике, характеризуя какое-либо свойство объекта, используется не пара, а лишь одно лингвистическое значение. Можно предполагать, что при этом в ряде случаев интуитивно выбирается то лингвистическое значение, которому соответствует большая оценка. В табл.1 такие лингвистические значения выделены курсивом
.Далее, следует выбрать одну из основных зон и расположить соответствующие ей лингвистические значения в порядке возрастания числовой оси. При этом порядок следования лингвистических значений определяется порядком следования используемых количественных модификаторов (слегка
<достаточно< <очень). В результате лингвистические значения связываются с определенными числами на оси. Расстояния между соседними лингвистическими значениями определяются субъективно и не обязательно должны быть равными. На второй оси, симметрично биссектрисе угла (начала координат) расположим лингвистические значения соответствующие другой основной зоне. Как уже отмечалось выше, лингвистические значения можно рассматривать как координаты состояния объекта, следовательно, в настоящий момент мы располагаем по одной координате для каждого состояния. Теперь с учетом зависимости (1), определим для каждого состояния вторую координату, используя соответствующие лингвистические значения (см. табл.1).Для связи дискретных по своей природе лингвистических значений с непрерывной числовой осью оценок, воспользуемся идеей фаззификации предложенной Л.А. Заде. При этом приходим к нечетким множествам с названиями соответствующих лингвистических оценок (рис.1). На рис.1 для экономии места лингвистические значения заменены своими номерами из таблицы 1.
Можно предложить несколько вариантов уточнения лингвистических оценок. например, можно использовать понятие степени принадлежности, но можно дополнительно ввести такие языковые конструкции, как - немного, гораздо,…, или на Х% “ближе к…, чем к…”.
Похожую модель “серого” мира можно найти в работе Д.А. Поспелова
[4], где он в качестве примера шкалы, отражающей представление о мире, приводит нечисловую оппозиционную шкалу. Отметим, что в отношении такой шкалы справедливы все рассуждения приведенные выше. Так в работе [4] А, O А - антонимы, а их оценки (А=30%, O А=70%) - по смыслу синонимы, координаты состояния объекта. Также в [4] есть точка равновесия (средняя точка - А=50%, O А=50%) и применима та же идея распределения лингвистических оценок (если данную шкалу соответствующим образом расположить в прямоугольной системе координат).Вернемся к логике антонимов. Свойства связок b
, g и a позволяют поставить им в соответствие логические “ИЛИ”, “И” и отрицание НЕ соответственно. В итоге, можно сказать, что разработанный ЛП на базе ЛА позволяет моделировать процесс рассуждений в 2 этапа: 1) построение модели рассуждений на грубом, качественном уровне с использованием качественных лингвистических оценок; 2) количественная лингвистическая оценка свойств, положенных в основу модели на 1-ом этапе. Кроме того, ЛП на базе ЛА позволяет лингвистически задать модель объекта (его свойств) и далее оценивать насколько исследуемый объект соответствует заданному. Результат решения задачи также представляется с использованием лингвистических значений.Проведем краткое сравнение ЛП на базе ЛА с ЛП Заде.
Общее. Как и в ЛП Заде, в основе ЛП на базе ЛА лежат идеи гранулирования информации и фаззификации, позволяющие формализовать процесс познания (описания) окружающего мира.
Отличия.
1) Имеется возможность преобразовывать (минимизировать) построенные модели вследствие того, что ЛА, в отличие от нечеткой логики Заде, обладает свойством булевости, т.е. в ней справедливы все законы классической логики.
2) В ЛА и в ЛП на базе ЛА выполняется принцип координат, т.е. пару оценок Н
[А], Н[a А] и соответствующие им лингвистические значения можно интерпретировать как координаты состояния исследуемого объекта. У Заде в общем случае этот принцип в отношении пары А, O А не выполняется.3) В рассмотренном ЛП значительно упрощена задача поиска лингвистического приближения, т.е. преобразования полученного числового результата в слова.
4) ЛП на базе ЛА дает возможность работать непосредственно с оценками восприятия, без использования промежуточных оценок истинности.
Вывод. ЛА и разработанный на ее основе ЛП могут служить базой для построения вычислительной теории восприятия. При этом, такая теория, возможно будет иметь некоторые преимущества над “вычислительной теорией восприятия базирующейся на вычислении со словами” Заде (
Computational Theory of Perceptions Based on Computing with Words).Литература
1. Lotfi A. Zadeh Toward a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic/ Fuzzy Sets and Systems, 90 (1997) 111-127.
2. Голота Я.Я. О формализации логики неполных знаний (логики антонимов) // Логика и развитие научного знания: Межвуз. сб. под ред. И.Н. Бродского, Я.А. Слинина. – СПб.: издат. С.-Петербургского универ., 1992.-С. 92-112.
3. Голота Я.Я. Непрерывнозначная логика. Л., 1982. Деп. В ВИНИТИ 14.10.82.
4. Поспелов Д.А. Знания и шкалы в модели мира
/ Модели мира: сб. под ред. Д.А. Поспелова. - М.: издат. Российская ассоциация искусственного интеллекта, 1997. - С. 69-87.| Site of Information
Technologies Designed by inftech@webservis.ru. |
|