Информационные структуры медицинских данных и многошаговый байесовСкий процесс принятия решений
А.А. Генкин
Научно-исследовательская фирма “Интеллектуальные Системы”, Санкт-Петербург
Abstract – It is describes methodology of introduction of a measure in n- space of clinical - laboratory attributes and algorithm basing on the Bayes formula is stated in which the absence of knowledge about prior probabilities is not essential.
The measure is construction with the help of formation of interval and binary structure - new objects of medical computer science, and the prior probabilities are consistently specified on the establishment of an experimental stuff.
Хорошо известны трудности применения формулы Байеса в задачах медицинской диагностики. Одна из них связана с оценкой вероятности P(
x/Dk ), где x – n-мерный вектор лабораторных и инструментальных признаков, а Dk (k = 1, 2, …, m) – клинические состояния. Обычно эта трудность преодолевается предположением о независимости признаков и применением формулы Байеса для каждого признака отдельно. Получаемые апостериорные вероятности затем складываются и решение принимается либо по средней арифметической этих вероятностей либо по их сумме [1].Другая принципиальная трудность обусловлена необходимостью знать априорные вероятности клинических состояний
Dk.В медицинских приложениях эти вероятности обычно очень ненадежны и зависят от многих факторов (например, априорные вероятности рака в специализированной и терапевтической клиниках могут отличаться на порядок).
Ниже излагается методология введения вероятностной меры в пространстве клинико-лабораторных признаков и алгоритм, опирающийся на формулу Байеса, в котором отсутствие знания об априорных вероятностях не существенно, а необходимая оценка
P(x/Dk) по эмпирическим данным обеспечивается наилучшим образом.1. Методологические предпосылки.
Пусть вектор х
= {x1, x2 ,…, xn} – набор из n значений количественных и качественных признаков, элемент n-мерного пространства. Векторы x1, x2, …, xN содержат информацию о состоянии N пациентов (или информацию о состоянии одного пациента в N моментов времени). Множество векторов {x}={x1, x2, …, xN}, обусловленных клинической ситуацией D, будем называть образом в пространстве признаков и обозначать {х}D.Пусть
Q(xi), i=1, 2, …, n – диапазон допустимых значений признака хi, совместимых с жизнью организма (для перечислимых признаков это не диапазон, а дискретное множество).С точки зрения системного подхода, {
x}D = {x1, x2, …, xN} в теоретическом, идеальном случае может быть представлено как подмножество прямого произведения Q(x1) ґ Q(x2) ґ … ґ Q(xn) [4 ].Если вместо оценки средних и коэффициентов корреляции (в случае медицинских данных приводящих к большим потерям информации) использовать вероятностные меры для всех Q
(хi) и для всех бинарных отношений Q(xi)ґ Q(xj), то принципиально расширяются возможности описания информации по сравнению с многомерной нормальной моделью.Другими словами, предполагается, что основная информация об {
x}D содержится в подмножестве S множества одномерных и двумерных элементов. Т.е. мы имеем отображение{x}D ® S (*)
Отображение (*) позволяет:
Введение вероятностной меры в
n-мерном пространстве досталось ценой значительного увеличения числа признаков, так как вместо одного n-мерного образа анализируются n одномерных и n(n – 1)/2 двумерных множеств. Но уже само введение вероятностной меры позволяет эффективно оценить значимость информации, заключенной в элементах множества (*), а затем значительно сократить их число [2,3]. Поэтому, на самом деле, наиболее важную информацию о клинической ситуации удается экономно представить в виде небольшого числа частотных распределений – интервальных и бинарных (матричных) структур.2.Построение интервальных и бинарных структур
Пусть
x = {х1, х2, …, хn} – описание одного пациента в n–мерном пространстве клинико-лабораторных признаков – точка в n-мерном абстрактном пространстве; {x}D1, {x}D2,, …, {x}Dm – множества векторов – образов, индуцируемых клиническими ситуациями D1,, D2,, ..., Dm, которые отражают цели, стоящие перед исследователем.Введем разбиение
d диапазона [a, b] на небольшое число (не больше четырех) отдельных диапазонов, длины которых заранее не предопределены. Обозначим через рs (x/Dk) частоту попадания значения признака х (х – любое значение признака х) в s-й диапазон.Для двух референтных условий
Dk и Dl в качестве наилучшего разбиения диапазона [а,b] выбирается разбиение, обеспечивающее функционалу Кульбака J(Dk:Dl, x) [2] значение, близкое к наибольшему, т.е такое разбиение d , при котором можно наилучшим образом использовать дифференциально-диагностические возможности признака х для пары референтных условий D k и D l.В общем случае максимизируется величина
![]() Интервалы, образующие разбиение,
вместе с вероятностями появления значения
признака в каждом из этих интервалов будем
называть интервальной структурой.
Интервалы, образующие разбиение,
вместе с вероятностями появления значения
признака в каждом из этих интервалов будем
называть интервальной структурой.
Фундаментальное отличие границ интервалов, входящих в интервальную структуру, от референтных нормальных величин заключается в том, что они заранее не определены. Это гибкие границы, обусловленные целью, стоящей перед пользователем, и каждый раз при решении конкретной задачи они подчеркивают наиболее значимую дифференциально-диагностическую информацию.
Для двух признаков x
i и xj , зная разбиения d 1 и d 2 для каждого из них, естественным образом строятся оценки р (xi,xj /Dk) – частоты попадания пары значений признаков хi и хj в соответствующие прямоугольники. Множество прямоугольников вместе с оценками p (xi,xj /Dk) предлагается называть бинарной (матричной) структурой, а соответствующую пару признаков – двумерным признаком.Интервальные и бинарные (матричные) структуры – новые объекты медицинской информатики. Они эффективно характеризуют вариабельность медико-биологических признаков и выявляют различия, когда другие методы не в состоянии этого сделать.
Интервальные и бинарные структуры
– удобные инструменты формализации медико-биологических знаний и источник информации для эффективных диагностических алгоритмов, использующих статистические стратегии распознавания образов.3. Сокращение числа признаков
![]() При построении интервальных и
бинарных структур появляется возможность
отбирать такие одномерные и двумерные признаки,
которые содержат информацию для решения
дифференциально-диагностических задач –
информативные признаки. На основании величины
функционала Кульбака и числа наблюдений,
участвующих в формировании интервальных и
бинарных структур, признаки упорядочиваются по
возрастанию уровня значимости различий P [2, 3]. Те из них, для которых P > 0.1,
исключаются из описания информационного образа
клинической ситуации. Так, при n = 100 формируется 5050 одномерных и
двумерных признаков. Если решается сложная
дифференциально-диагностическая задача, в
результате отбора обычно остается не более 50
информативных признаков.
При построении интервальных и
бинарных структур появляется возможность
отбирать такие одномерные и двумерные признаки,
которые содержат информацию для решения
дифференциально-диагностических задач –
информативные признаки. На основании величины
функционала Кульбака и числа наблюдений,
участвующих в формировании интервальных и
бинарных структур, признаки упорядочиваются по
возрастанию уровня значимости различий P [2, 3]. Те из них, для которых P > 0.1,
исключаются из описания информационного образа
клинической ситуации. Так, при n = 100 формируется 5050 одномерных и
двумерных признаков. Если решается сложная
дифференциально-диагностическая задача, в
результате отбора обычно остается не более 50
информативных признаков.
![]()
![]()
![]() При разработке решающего правила
нет необходимости использовать все
информативные признаки. Всегда существуют
подмножества информационно-ценных признаков
(вообще говоря, различные для разных стратегий
распознавания), которые обеспечивают более
высокие результаты. Алгоритм поиска таких
подмножеств будет рассмотрен в п.5.
При разработке решающего правила
нет необходимости использовать все
информативные признаки. Всегда существуют
подмножества информационно-ценных признаков
(вообще говоря, различные для разных стратегий
распознавания), которые обеспечивают более
высокие результаты. Алгоритм поиска таких
подмножеств будет рассмотрен в п.5.
4. Многошаговый байесовский процесс
В многошаговом байесовском алгоритме органически объединены многольтернативность формулы Байеса и продуктивная идея неоднородного последовательного анализа – упорядочение признаков в соответствии с их информативностью.
Суть метода заключается в том, что априорные вероятности последовательно уточняются на основании экспериментального материала.
Пусть х1, х2, …, хn – упорядоченные по убыванию информативности признаки, как одномерные, так и двумерные, отобранные для решения интересующей нас задачи. Для простоты изложения ограничимся тремя клиническими ситуациями D1, D2, D3.
2) На втором шаге полученные вероятности используются как априорные для признака x2.
3) На третьем шаге для признака х
3 в качестве априорных вероятностей используются полученные на втором шаге:Этот процесс продолжается до тех пор, пока не будут исчерпаны все признаки.
Решение принимается в пользу той гипотезы, для которой вероятность на последнем шаге оказывается наибольшей. Изложенный алгоритм предлагается называть многошаговым байесовским алгоритмом – Байес (S) [5 ].
5. Отбор подмножества информационно-ценных признаков
Среди информативных признаков, выявленных с помощью критерия Кульбака, много зависимых, что может приводить к значительному ухудшению результатов. Поиск подмножества информационно-ценных признаков реализован в двух вариантах. Суть более простого заключается в следующем.
1-й шаг. Из множества информативных выбирается признак, обеспечивающий на обучающей группе минимум суммы вероятностей ошибок классификации.
2 шаг. Из оставшихся информативных выбирается признак, который вместе с первым обеспечивает минимум суммы ошибок классификации на той же группе; при этом каждый признак, который вместе с первым ухудшал результат только первого, из дальнейшего рассмотрения исключается. Процесс продолжается до тех пор, пока сумма ошибок классификации уменьшается.
 Второй вариант – более трудоемкий –
отличается тем, что на каждом шаге при выборе
очередного признака просматриваются все
оставшиеся признаки, а не только те, которые на
предыдущем шаге улучшали результат. Этот вариант
поиска информационно-ценных признаков приводит
к подмножеству, дающему лучшие результаты. Число
информационно-ценных признаков значительно меньше числа
информативных.
Второй вариант – более трудоемкий –
отличается тем, что на каждом шаге при выборе
очередного признака просматриваются все
оставшиеся признаки, а не только те, которые на
предыдущем шаге улучшали результат. Этот вариант
поиска информационно-ценных признаков приводит
к подмножеству, дающему лучшие результаты. Число
информационно-ценных признаков значительно меньше числа
информативных.
6. Применение
 Последовательная байесовская
стратегия, наряду со стратегиями
Неймана-Пирсона, Вальда, классической
байесовской процедурой и др., используется при
разработке решающих правил в программном
комплексе ОМИС в различных областях медицины [5].
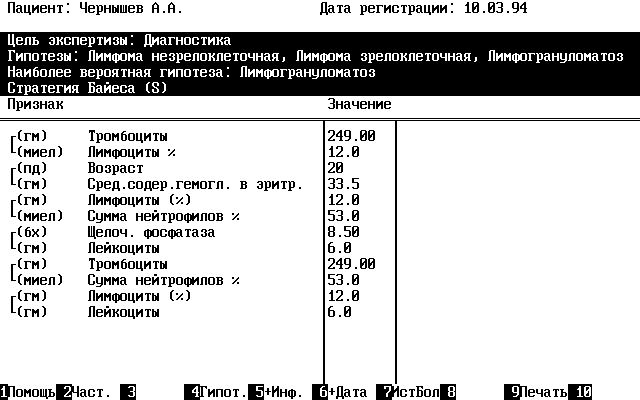
В качестве иллюстрации ниже приведен фрагмент
экрана экспертного модуля с вероятностями
гипотез на заключительном шаге
последовательного байесовского алгоритма при
распознавании лимфогранулематоза,
зрелоклеточной и незрелоклеточной лимфом, у
одного из пациентов без гистологической и
цитологической информации.
Последовательная байесовская
стратегия, наряду со стратегиями
Неймана-Пирсона, Вальда, классической
байесовской процедурой и др., используется при
разработке решающих правил в программном
комплексе ОМИС в различных областях медицины [5].
В качестве иллюстрации ниже приведен фрагмент
экрана экспертного модуля с вероятностями
гипотез на заключительном шаге
последовательного байесовского алгоритма при
распознавании лимфогранулематоза,
зрелоклеточной и незрелоклеточной лимфом, у
одного из пациентов без гистологической и
цитологической информации.
Надежное решение для конкретного пациента о наличии лимфогранулематоза при отсутствии морфологических данных было бы вообще невозможно для современного клинического мышления без информационной поддержки. При разработке решающего правила из 70 исходных количественных признаков программный комплекс ОМИС отобрал шесть двумерных информационно-ценных признаков, приводимых ниже (каждому из них соответствуют три бинарные структуры – матрицы 4 х 4, по одной для каждой клинической ситуация), которые е вместе с Байесом (S) оказались достаточными для решения важной клинической задачи.
Эксплуатация программного комплекса ОМИС в различных областях медицины показала, что изложенный алгоритм почти всегда приводит к более высоким результатам распознавания и может использоваться для повышения надежности клинических решений в здравоохранении [5].
Литература
[1]
Ластед Л. Введение в проблему принятия решений в медицине – М. Мир, 1971.[2]
Кульбак С. Теория информация и статистика – М. Наука, 1967.[3]
Колмогоров А.Н. Предисловие редактора перевода книги [2].[4]
Клир Дж. Системология. Автоматизация решения системных задач – М. Радио и связь, 1990.[5]
Генкин А.А. Новая информационная технология анализа медицинских данных – СПб. Политехника, 1999.| Site of Information
Technologies Designed by inftech@webservis.ru. |
|