[an error occurred while processing this directive]
Реляционные,
древовидные и объектно-ориентированные базы
данных
Артур Б. Смит
M Computing May/June 1996, v.4 n.2, стр.8
(Артур Смит (Art Smith) получил дипломы магистра
химии, информатики и информационных систем
Делавэрского Университета в 1985 году, где до
последнего времени и работал в области научного
и прикладного программирования. В настоящее
время он работает в Университете
Ветеринарно-Медицинского Учебного Госпиталя
штата Миссури и является консультантом по
вопросам новых технологий.)
В этой статье представлено неформальное
сравнение трех различных подходов к конструкции
(модели) базы данных. Особое внимание уделяется
сравнению достоинств и недостатков каждой из
технологий и характеристикам приложений,
которые наилучшим образом соответствуют каждой
из трех моделей. В начале необходимо отметить,
что любая из этих технологий может быть
использована для моделирования любой базы
данных; конвертация одной базы данных в другую
легко автоматизируется. Преимущество же лежит в
удобстве и простоте для разработчиков баз
данных, для персонала, их обслуживающего и для
пользователей. Преимущества проявляются в двух
видах: теоретические преимущества одной
технологии над другими и практические
преимущества, которые зачастую имеют скорее
рыночный, нежели программно-технический
характер. Будут изучены оба фактора.
Реляционная (или основанная на
таблицах) модель базы данных безусловно наиболее
часто используется сегодня и представлена как
большими коммерческими пакетами, как Oracle, Sybase,
Informix, Ingres и Gupta, так и маленькими как DBaseIV, Access, FoxPro,
Alpha4 и Paradox. Все они основаны на первой
теоретической работе Кодда и др. 1970 года. Из трех
моделей, реляционная модель имеет наиболее
хорошую математическую базу, включающую
реляционную алгебру и реляционное исчисление.
Последнее является основой языка запросов SQL и
расширения ODBC, которые широко применяются для
подключения пользовательского интерфейса в 2-х и
3-х слойных приложениях клиент/сервер.
Древовидная модель представлена
многочисленными ранними языками баз данных,
включая DL/1 фирмы IBM, M и Язык Описания Данных
КОДАСИЛ. Все эти системы представляют данные
непосредственно в виде дерева и могут
оперировать с сетевыми данными (которые могут
иметь связи "многие -ко-многим"). С
математической точки зрения эти базы данных
описываются математической теорией графов. Во
многих реализациях этих систем можно создать
(возможно ограниченное) отображение в
реляционную модель, которая позволяет
использовать SQL/ODBC в качестве интерфейса на
уровне запросов.
Объектно-ориентированные базы данных
относительно новы и по-прежнему достаточно
примитивны в некоторых отношениях. В большинстве
из современных систем, таких как Objectivity, Poet и Versant
ощущается недостаток удобства как для
пользователя, так и для программиста, и сама по
себе теория баз данных не имеет такой хорошей
математической основы как реляционные или
древовидные модели. Тем не менее это не должно
обязательно рассматриваться как признаки
слабости, присущие данной технологии
моделирования. Скорее это указывает на молодость
данной технологии. Серьезная работа ведется по
исправлению обоих этих недостатков, и обе
системы баз данных (и реляционная, и древовидная)
стремятся применить объектно-ориентированные
модели, как правило, поверх их собственных
неотъемлемых структур.
В этой статье будет сделана попытка показать
сравнительные преимущества каждой из этих
технологий и обозначить характеристики
приложений, которые позволяют эти преимущества
извлечь. Каждая из этих технологий имеет свое
место, и тщательный выбор модели базы данных -
первый важный шаг при разработки любого крупного
приложения, ориентированного на работу с БД .
Системы управления реляционными
базами данных. (СУРБД)
Теоретические вопросы
Все реляционные базы данных используют в
качестве модели хранения данных двумерные
таблицы. Эта модель выбрана потому что она в
основном знакома всем пользователям и
рассматривается как "естественный" путь
представления данных. Любая система данных, не
имеет значения какой сложности, может быть
сведена к набору таблиц (или "отношений" в
терминологии СУРБД) с некоторой избыточностью.
Избыточность контролируется путем приведения
отношений к канонической "нормальной"
форме, которая минимизирует ненужную
избыточность без уменьшения связей между
элементами данных.
- Каждое отношение (таблица) может быть
представлено в виде прямоугольного массива со
следующими свойствами:
- Каждая ячейка в таблице представляет точно один
элемент данных; нет повторяющихся групп.
- Каждая таблица имеет однородные столбцы; все
элементы в любом из столбцов одного и того же
вида.
- Каждому столбцу назначено определенное имя.
- Все строки различны; дублировать строки не
разрешается.
- И строки, и столбцы не зависят от
последовательности; просмотр в различной
последовательности не может изменить
информационное содержание отношения.
Каждая строка олицетворяет уникальный элемент
данных, который ею и описывается.
Столбцы представляют собой отдельные куски
информации (атрибуты данных), которые известны о
данном элементе. Строки обычно называют
записями, а столбцы - полями.
Кроме того, для обработки отношений разрешены
только следующие операции:
- Добавить и Удалить запись. (Редактирование
косвенно разрешено в виде конкатенации операций
"Добавить" и "Удалить")
- Соединение (при котором временное отношение
создается путем соединения информации двух
отношений, используя общие поля).
- Выборка (в которой выбирается подмножество
записей в отношении, основываясь на определенных
значениях или ряде значений в выбранных полях).
Другие операции с данными обычно не
поддерживаются в базах с реляционной структурой.
Добавление произвольных данных, которые,
например, не соответствуют ни одному полю в
описании данных, запрещено. Добавление поля для
произвольных данных потребовало бы перестройки
(реструктурирования) базы данных. А этот,
зачастую очень длительный, процесс может
выполняться только когда базой данных никто не
пользуется.
Вообще, лишь немногие реальные базы данных
могут быть описаны при помощи единственной
таблицы. Большинство приложений используют
множество таблиц, которые содержат столбцы (поля)
с одинаковым именем. Эти общие данные позволяют
объединяя две (или несколько) таблицы, строить
осмысленные ассоциации. Лучше всего это
иллюстрируется примером. Рассмотрим два
отношения "Служащий" и "Отдел",
показанные на рис.1.
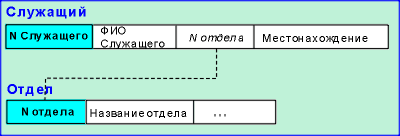 |
В этом примере поля Номер Служащего
и Номер Отдела выделены; это указывает на то,
что эти поля - первичные ключи. Это означает, что
элементы данных в этих полях единственным
образом определяют запись (т.е. никакие две
записи не имеют одинакового элемента данных в
ключевом поле). Более того, поле N отдела
обнаруживается в обеих таблицах. Это позволяет
объединить две таблицы таким образом, чтобы,
например, определять Название отдела
для любого заданного Служащего. |
| Рис.1 |
|
Во многих случаях это объединение не такое
простое. Предположим, нам требуется найти способ
для определения, кто является Руководителем
для любого Служащего. Мы могли бы создать
следующую структуру данных:
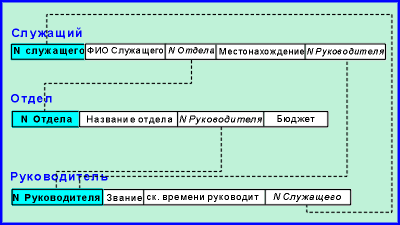 |
Эта на вид
интуитивная структура может вызвать проблемы
из-за избыточности связи отношения
"Руководитель", связанного с отношением
"Служащий" как напрямую, так и через
отношение "Отдел". Эта избыточность
позволяет руководителю служащего отличаться от
руководителя отдела служащего. Если это не
разрешено, то приведенная структура таблиц не
подходит. |
Рис.2 |
|
Вместо нее более подходящей была бы структура,
представленная на рис.3.
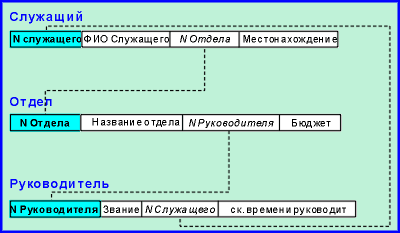 |
Эта структура удаляет
избыточность, которая позволяет Служащему
иметь Руководителя, отличного от Руководителя
его Отдела. Но делая это, она удаляет прямую
связь, которая может быть желательна с точки
зрения производительности больших баз данных.
Эта взаимосвязь между производительностью и
целостностью данных присутствует фактически во
всех моделях баз данных. |
| Рис.3 |
|
Простой реальный пример может потребовать еще
более сложной труктуры.
Пусть Служащий является членом более чем
одного Отдела. Правила соединения в
реляционных базах данных не разрешают связей
"многие-ко-многим" (которые можно обозначить
при помощи стрелки с двойным указателем на
каждом конце). Чтобы представить отношение с
такими связями (например, каждый Отдел имеет
многочисленных Служащих и каждый Служащий
может быть членом Многочисленных Отделов),
нам надо создать отдельное отношение, которое
является гибридом двух столбцов:
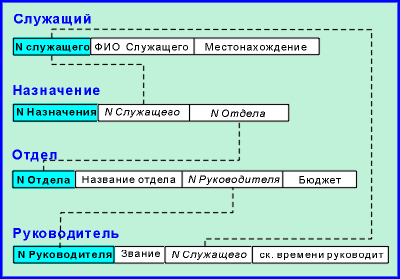 |
Здесь отношение "Назначение"
содержит запись для каждого отдела, сотрудником
которого является служащий. То есть, если Служащий
работает в Отделе, то соответствующие Номер
Служащего и Номер отдела обнаруживаются
точно в одной записи отношения "Назначение".
Поле Номер Назначения фактически не нужно,
так как Номер Служащего и Номер Отдела
могут вместе служить ключем. В большинстве (но не
во всех) СУРБД разрешены отношения с составными
ключами. Для тех из них, в которых ключ должен
быть представлен обязательно одним полем,
структура будет такой, как представлена выше. |
| рис.4 |
|
"Естественный подход" с использованием
таблиц может оказаться еще более "притянутым
за уши", когда данные - разреженные.
Разреженные данные означают, что не каждое поле в
каждой записи содержит данные. В некоторых
приложениях данные очень разреженные - только
несколько из большого числа столбцов,
определенных для данного отношения, могут
содержать данные в каком-либо заданном ряду. Если
в реальном приложении типично, что данные
разреженные, то обычно пользователь не
рассматривает их как табличные. Например,
представим отношение, описывающее посещение
пациентом врача. Оно может иметь поля, которые
содержат результаты обследования: радиограмма,
ультразвук, температура, вес и т.д. Большинство из
этих полей может быть пусто для какого-либо
пациента. Представить их в качестве полей
таблицы в лучшем случае противоестественно.
Более естественно представить эти данные в виде
списка элементов, чем в качестве полей таблицы.
Воплотить в жизнь эту точку зрения пользователя
в реляционной базе данных нелегко. Эти различные
элементы нельзя занести в одну таблицу, так как
они нарушают однородность столбца - данные,
хранящиеся в полях, не все одного типа, как это
требуется в реляционных таблицах.
Реляционные базы данных были бы совсем
непригодны, если бы эти разреженные данные
действительно хранились внутри прямоугольного
массива, так как для этих пустых элементов данных
надо было бы выделять пространство. В
действительности, большинство современных СУРБД
используют таблицы как "логические"
структуры, но в качестве внутренних
"физических" структур используют структуры,
которые могут хранить редкие данные более
эффективным способом, таким как В-дерево. Выбор
физической структуры иногда предоставляется
разработчику БД как возможность оптимизации
производительности.
В качестве второго примера рассмотрим
упрощенный вариант компьютеризованной
регистрации пациента (КРП). В этой базе данных
хранится информация о пациентах и процедурах,
которым они подвергались (этими процедурами
могут быть осмотры, лабораторные тесты и т.д.).
Пациенты также могут иметь ряд заболеваний,
которые были диагностированы, и любая процедура
может отождествляться с одним или несколькими из
этих заболеваний. Реляционная структура этой БД
показана на рис.5.
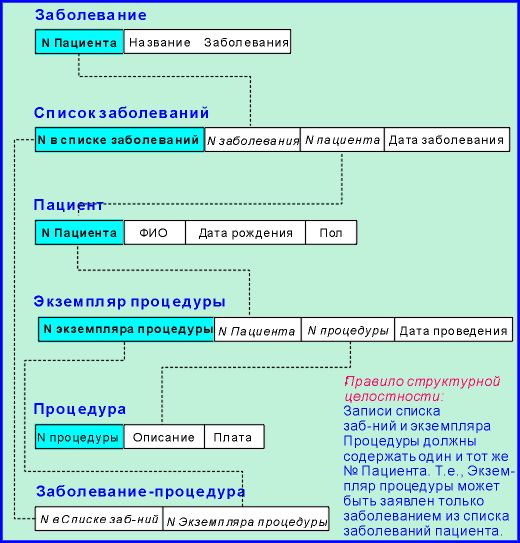
рис.5
Рис.5 ясно показывает, как может расти сложность
модели данных, когда реляционные ограничения
применяются к данным, которые по своей природе не
являются табличными. Концептуальное описание БД
включает только пациентов, процедуры и
заболевания. Из-за большого количества связей
между этими объектами необходимо было ввести
отношения 2-го (Список заболеваний и Экземпляр
процедуры) и 3-го уровня (Соответствие
заболевания и процедуры). Необходимо
также принять правило структурной целостности
для того, чтобы избежать появления бессмысленных
данных. (Назначение процедуры одному пациенту,
вызванной заболеванием другого пациента).
Для представления подобных данных могут
использоваться другие реляционные структуры, но
их можно упростить только либо за счет
ограничения гибкости БД (например, за счет
невозможности введения заболевания без
процедуры, связанной с данным заболеванием), либо
за счет нарушения принятых правил нормализации
реляционных БД (Третья Нормализованная Форма).
Аргументация в пользу интуитивно ясных РБД,
приведенные Коддом и другими, кажется
неподходящей в ситуациях, подобных этой. Это не
значит, что эта аргументация обманчива, просто
она не одинаково хорошо подходит для всех
наборов данных.
Практические вопросы
В настоящее время модель реляционной базы
данных - лидирующая в компьютерной индустрии и
занимает эту позицию уже приблизительно 20 лет. Но
по иронии судьбы эта позиция силы может
превратиться в позицию слабости. Несмотря на то,
что РБД стали доминирующими в индустрии баз
данных за последние 20 лет, многие эксперты
почувствовали, что РБД приближаются к концу
своей "карьеры" доминирующего игрока и
будут вытесняться более современными и гибкими
моделями, в первую очередь моделью
объектно-ориентированной базы данных.
Существуют некоторые сомнения относительно
того, смогут ли такие гиганты как Oracle, Informix, Sybase,
Gupta и т.д. произвести изменения своевременно, имея
так много клиентов. Требование поддерживать
обратную совместимость может резко
препятствовать их возможности идти в ногу с
прогрессом технологии БД. С другой стороны,
прекрасное финансирование этим огромным
количеством клиентов упрощает разработки. Все
продавцы больших реляционных баз данных
добавляют объектно-ориентированные средства,
помещая их поверх нижележащей реляционной
структуры. Эти средства полезны при разработке
базы данных, но по-видимому бесполезны во время
выполнения, так как лежащая в основе реляционная
модель сохраняется. Если вы ищете вполне
развитый, хорошо документированный, хорошо
изученный, хорошо поддерживаемый продукт на
сегодня, то СУРБД действительно лидеры. Если же
вы хотите, чтобы все эти свойства были и 10 лет
спустя, то они могут быть, а могут и не быть.
Многие эксперты ожидают серьезного изменения
основополагающих принципов технологии БД.
Конечно, легко предсказать, что кто-нибудь
станет следующим Oracle; предсказание же того, какая
именно фирма станет следующим Oracle достойно
оракула другого сорта...
Системы управления базами данных с
древовидной структурой (например, M)
Теоретические вопросы
Структура этих СУБД базируется на деревьях и на
ориентированных графах в большей степени, чем на
таблицах. В этих БД с древовидной структурой
данные представлены в виде набора узлов. Каждый
узел дерева может хранить данные и может иметь
некоторое количество (ориентированных) связей с
узлами-потомками. Обычно не требуется, чтобы
узлы-потомки и/или узлы, имеющие один узел-предок
были одного типа. Обычно допускается, что узел
содержит открытый список связей с
многочисленными узлами того же типа, разрешая
прямое представление связей
"многие-ко-многим".
В БД с сетевой структурой, требование
древовидности (каждый узел должен иметь точно
одного предка, кроме корня, который вообще не
имеет предков) смягчено. Связи могут быть
ограничены созданием ориентированного
нециклического графа (ОНГ) (никакая
последовательность связей, идущих от узла, не
может вернуться обратно к узлу), или может быть
разрешен любой ориентированный граф (набор узлов
и ориентированных связей между парами узлов без
каких-либо других ограничений).
В М воплощена концепция БД с древовидной
структурой (дочерние узлы являются компонентами
родительского узла) и разрешает внешние связи
(единичные или в массиве) с любыми другими узлами.
Пример, который мы использовали для реляционной
базы данных, может быть реализован на М при
помощи структуры, представленной на рис.6
(предполагаем, что каждый служащий - сотрудник
только одного отдела).
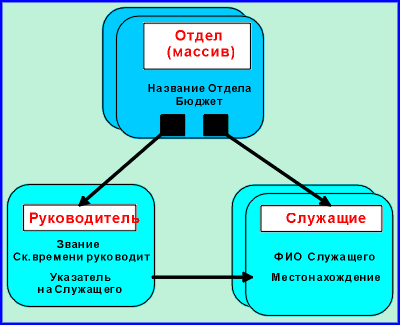 |
На этой диаграмме - родительским
узлом является Отдел. Каждый отдел имеет
единственного потомка Руководитель и
массив потомков Служащие. Отметим, что Руководитель
- это просто Служащий, который определяется
узлом Руководитель, указывающего на этого
особенного служащего при помощи Указателя на
Служащего. Для этого указателя не требуется
обратного направления - Руководителя
Служащего можно определить, посмотрев на узел Руководитель,
порожденный родительским для Служащего
узлом (Отдел). Отметим, что структура данных
в значительной степени отражена в структуре БД,
нам не потребовалось создавать и отдельно
описывать связи. |
Рис.6 |
|
Эта структура, однако, не подходит, если
предположение, что служащий числится только в
одном отделе, неверно. Она также плохо работает,
если служащий меняет отдел, даже если он при этом
является членом хотя бы одного отдела. Это
происходит из-за того, что вместо простой
корректировки указателя (фактически одного
числа) целый набор данных (служащий) должен быть
перемещен из одного элемента данных (отдел) в
другой. Несмотря на то, что это обычно не требует
фактических перемещений данных, хранящихся в
компьютере, это почти всегда сложнее, чем
корректировка указателя.
Более подходящая структура показана на рис.7.
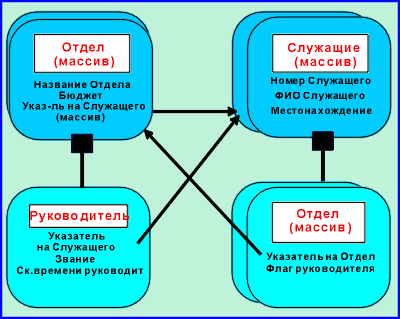 |
Она содержит два вида вершин верхнего
уровня, Отдел и Служащий, оба - массивы
(то есть может быть множество различных
экземпляров каждого). Каждый Отдел имеет
определенного Руководителя, который
содержит указатель на экземпляр Служащий
(Служащий, который является руководителем
отдела). Каждый узел Отдел также имеет
массив указателей на экземпляры объекта Служащий,
представляющий всех служащих отдела, включая Руководителя
(при этом назначение нового руководителя не
выкидывает автоматически снятого руководителя
из отдела). Аналогично, каждый Служащий
имеет массив определенных узлов Отдел,
каждый из которых состоит из указателя на узел Отдел
и флаг для индикации, является ли данный служащий
руководителем этого отдела. Служащие могут быть
членами (и даже руководителями) многочисленных
отделов, просто имея многочисленные экземпляры
узла Отдел, определенные для Служащего.
|
Рис.7 |
|
Эта модель данных содержит все те же связи, что
и реляционный пример, который был дан выше. Хотя
отдельные компоненты имеют более сложную
структуру, чем отдельные таблицы реляционной
модели, модель данных в целом в этом
представлении может быть более интуитивно
понятной.
Давайте теперь обратимся ко второму примеру -
упрощенная регистрация пациента. Используя БД с
древовидной структурой, мы можем создать
следующую модель данных для этой БД (см. рисунок
8).
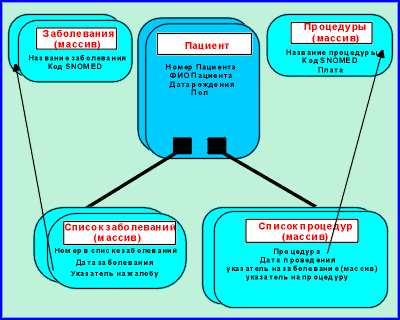
Рис.8
Эта модель данных имеет всю ту же информацию о
структуре, что и реляционная модель,
рассмотренная нами ранее (включая ограничение,
что процедура может быть объявлена только
жалобой из списка жалоб пациента, что требовало
введения в реляционной модели правила
структурной целостности). Опять же, структура
отдельных компонент намного сложнее, чем
таблицы, используемые в реляционной модели, но
общая структура намного более ясная, особенно
потому, что структурная целостность
гарантирована без применения внешних правил.
Практические вопросы
Структуры, определенные выше, базируются на
языке М, включающем элементы управления базой
данных. М - это имеющий ANSI стандарт язык
программирования, употребляемый уже более 20 лет,
который подвергся целому ряду существенных
преобразований (последний раз - в 1995 году. Доля
рынка, занимаемая М, никогда не была большой и
относительно сокращалась (при абсолютном росте)
в течение нескольких лет. М используется в
основном в здравоохранении и банковском деле,
кроме того - в ряде вертикальных приложений,
таких как выпуск "желтых страниц". М часто
объявляли мертвым, но тем не менее он продолжает
жить.
Слабое место большинства М приложений - это
пользовательский интерфейс, до недавнего
времени вынужденно отвечавший модели
"roll-and-scroll" семидесятых, созданную для тупых
или умеренно интеллектуальных терминалов. За
последние 2 года большинство крупных продавцов М
выпустили средства, открывшие возможность
реализации современных пользовательских
интерфейсов c помощью инструментов третьих фирм.
М еще ждет полнофункциональных средств
разработки интерфейса, имеющихся во многих
реляционных базах данных.[Прим. редактора
перевода: Статья была написана до появления
MSM-Workstation for Windows. ]
Относительно небольшое присутствие на рынке (а
значит, ограниченность средств) замедляет
развитие М-систем их разработчиками и делает
рынок непривлекательным для большинства крупных
третьих фирм. Роста популярности открытых
стандартов делают средства разработки сторонних
фирм все более доступными и для М.
Большинство сегодняшних М систем можно
свободно связывать с реляционными БД при помощи
SQL и ODBC. М может служить как внешним, так и
внутренним интерфейсом в этих "совместных
предприятиях". Однако для того, чтобы
использовать этот мост, администратор БД должен
создать отображение структуры М данных в
реляционную модель, так как SQL и ODBC предполагают
именно эту модель.
В комитете развития М прикладываются
значительные усилия для расширения языка в таких
направлениях, как поддержка
объектно-ориентированного программирования,
создание объектно-ориентированных БД и
управление ими. Гибкость структур данных и
позднее связывание типов данных в М позволяет
воплотить "настоящий"
объектно-ориентированный подход (возможно,
исключая инкапсуляцию) в противовес методу
"наслаивания", когда
объектно-ориентированные средства реализуются
как надстройка над реляционной БД.
Если М станет объектно-ориентированной СУБД и
продавцы снабдят его средствами разработки
интерфейса, то он может стать ведущим игроком в
индустрии баз данных. Без этого ему, возможно,
уготованы лишь вторые роли, за исключением тех
вертикальных "ниш", где он имеет верных
приверженцев.
Системы управления
объектно-ориентированными базами данных (СУООБД)
Теоретические вопросы
Объектно-ориентированные БД - относительно
новая концепция и, как таковая, не имеет четкого
определения. Требования, которым должна отвечать
"объектно-ориентированная" БД, целиком и
полностью лежат на совести их авторов. Свойства,
представляющиеся общими для большинства
реализаций, таковы:
1. Абстракция: Каждая реальная
"вещь", которая хранится в БД, является
членом какого-либо класса. Класс определяется
как совокупность свойств (properties), методов (methods),
общедоступных (public) и частных (private) структур
данных, а также программы, применимых к объектам
(экземплярам) данного класса. Классы
представляют собой ни что иное, как абстрактные
типы данных. Методы - это процедуры, которые
вызывается для того, чтобы произвести какие-либо
действия с объектом (например, напечатать себя
или скопировать себя). Свойства - это значения
данных, связанные с каждым объектом класса,
характеризующие его тем или иным образом
(например, цвет, возраст). Свойства присутствуют
не во всех реализациях, по сути дела, они являются
краткой записью методов без аргументов (таких
как "сообщите свой цвет", "сообщите свой
возраст").
2. Инкапсуляция: Внутреннее
представление данных и деталей реализации
общедоступных и частных методов (программ)
является частью определения класса и известно
только внутри этого класса. Доступ к объектам
класса разрешен только через свойства и методы
этого класса или его родителей (см. ниже
"наследование"), а не путем использования
знания подробностей внутренней реализации.
3. Наследование (одиночное или
множественное): Классы определены как часть
иерархии классов. Определение каждого класса
более низкого уровня наследует свойства и методы
его родителя, если они только они явно не
объявлены ненаследуемыми или изменены новым
определением. При одиночном наследовании класс
может иметь только один родительский класс (т.е.
классовая иерархия имеет древовидную структуру).
При множественном наследовании класс может
происходить от многочисленных родителей (т.е.
иерархия классов имеет структуру
ориентированного нециклического графа, не
обязательно древовидную). Не все
объектно-ориентированные СУБД поддерживают
множественное наследование.
4. Полиморфизм: Несколько классов
могут иметь совпадающие имена методов и свойств,
даже если они считаются различными. Это
позволяет писать методы доступа, которые будут
правильно работать с объектами совершенно
различных классов, лишь бы соответствующие
методы и свойства были в этих классах определены.
Например, метод Print может быть определен во
многих классах, но работать по-разному, в
зависимости от класса объекта, к которому он
применяется.
5. Сообщения: Взаимодействие c
объектами осуществляется путем посылки
сообщений с возможностью получения ответов. Это
отличается от традиционного для других моделей
вызова процедур. Для того, чтобы применить метод
к объекту, надо послать ему сообщение типа
"примени к себе данный метод" (например,
"напечатай себя"). Парадигма пересылки
сообщений не всегда используется в
объектно-ориентированных базах данных, однако
типична для "истинно" ОО-реализаций.
Каждый объект, информация о котором хранится в
ООБД, считается принадлежащим какому-либо
классу, а связи между классами устанавливаются
при помощи свойств и методов классов. Чтобы
почувствовать, как это происходит, давайте вновь
обратимся к нашим простые примеры. В первом
примере определим два класса верхнего уровня:
"Отдел" и "Служащий". Мы также определим
класс Руководитель, который является подклассом
класса Служащий. Унаследованные свойства и
методы показаны курсивом.
| Служащий |
| Свойство |
Тип |
Имя Служащего
Номер Служащего
Местонахождение
Список Отделов |
Текстовый
Цифровой
Текстовый
Список объект. ссылок: Отдел |
| Метод |
Возвращает |
| Выдвинуть (Отдел) |
Ссылка на (Руководитель) |
|
|
| Руководитель |
| (подкласс класса
Служащий) |
| Свойство |
Тип |
Имя Служащего
Номер Служащего
Местонахождение
Список Отделов
Ск. времени руководит
Звание |
Текстовый
Цифровой
Текстовый
Список ссылок на: Отдел
Целое
Текстовый |
| Метод |
Возвращает |
| <Повысить> |
Явно не унаследованный |
|
| Рис.9 |
|
Рис.10 |
Объекты (экземпляры класса) могут быть созданы
путем применения метода "Создать
экземпляр", который является общим для всех
классов. Объект класса "Служащий", однажды
созданный, связывается с отделом при помощи
метода "Нанять" класса "Отдел" (со
ссылкой на объект "Служащий" в качестве
аргумента).
| Отдел |
| Свойство |
Тип |
| Название Отдела |
Текстовый |
| Бюджет Список Служащих
Руководитель Отдела |
Список ссылок на: Служащий
Ссылка на: Руководитель |
| Метод |
Возвращает |
| Нанять(Служащий) |
<ничего> |
|
| |
| Рис.11 |
Для того, чтобы сделать служащего
руководителем, надо применить метод
"Повысить" к служащему (аргумент - ссылка на
"Отдел"). Этот метод создает новый объект
класса "Руководитель" с дубликатами
наследуемых свойств, и затем уничтожает
существующий экземпляр "Служащего"
(используя метод "Уничтожить", также общий
для всех классов). Возвращается ссылка на новый
объект (дескриптор объекта). Отметим, что метод
также должен скорректировать свойство "Список
служащих" каждого отдела, входящего в
"Список отделов", в которых работает
служащий. Это необходимо для сохранения
целостности БД. Поскольку "Руководитель"
является подклассом "Служащего", этот
"Список Служащих" не будет иметь никаких
конфликтов (ссылка на "Служащего", на самом
деле, может быть ссылкой на Руководителя, так как
он является подклассом служащего - обратное
неверно).
Отметим также, что наследование метода
"Повысить" явно заблокировано в подклассе
Руководитель (это обычно достигается
определением на уровне класса Руководитель
метода "Повысить", который ничего не делает).
Это годится лишь когда служащий может быть
руководителем только одного отдела. Если же
отдельный служащий может руководить несколькими
отделами, метод "Повысить" должен быть
применим и к руководителям. В этом случае метод
"Повысить" обязан вносить коррективы в
свойство "Руководитель отдела" для
соответствующих отделов из "Список отделов"
объекта "Руководитель".
| Абстрактное
Заболевание |
| Свойство |
Тип |
Название заболевания
Код
|
Текстовый
Текстовый(фикс.длины) |
| Метод |
Что возвращает |
|
|
| Абстрактная
Процедура |
| Свойство |
Тип |
Название проц-ры
Код
Цена |
Текстовый
Текстовый(фикс.длины)
В долларах |
| Метод |
Что возвращает |
|
Рис.12 |
|
Рис.13 |
Объектно-ориентированная реализация второго
примера (упрощенная регистрация пациента, рис.5)
может быть построена двумя различными способами
в зависимости от допустимости структурированных
значений свойств. В любом случае появятся классы
абстрактных заболеваний и абстрактных процедур
(рис. 12, 13). Различия обнаружатся в конструкции
класса "Пациент" и дополнительных классов.
Если значение свойства может состоять из
нескольких отдельных частей, то списки
заболеваний и процедур, проведенных с пациентом,
возможно, лучше всего поместить в объект
"Пациент" в виде списков структурированных
значений, как это показано на рис. 14.
| Пациент |
| Свойство |
Тип |
ФИО Пациента
Номер Пациента
Дата рождения
Пол
Список заболеваний
Список процедур
Список процедур |
Текстовый
Цифровой
Формат Даты
М/Ж
Список:
№ в списке заболеваний
цифровой
Дата заболевания
дата
Заб-ние Ссылка на:
Абстр.забол-е
Список:
№ в списке процедур
цифровой
Дата проведения
дата
№ в списке заболевания
цифровой
Процедура Ссылка на:
Абстр.процедура |
| Метод |
Что возвращает |
Добавить заболевание (Название
заболевания)
Добавить прцедуру (Название процедуры)
Назначение
(№ списка процедур, № списка заболеваний) |
№ списка жалоб
№ списка процедур
<ничего> |
|
Рис.14 |
Не во всех объектно-ориентированных БД
разрешены такие структурированные свойства. Это
не влияет на классы "Абстрактное
Заболевание" и "Абстрактная Процедура",
однако свойство "Список Заболеваний" класса
"Пациент" (рис. 17) станет списком ссылок на
объекты нового класса "Экземпляр
Заболевания" (рис. 15), и, аналогично, свойство
"Список Процедур" - списком ссылок на
объекты еще одного нового класса "Экземпляр
Процедуры" (рис. 16). Эти новые классы не надо
путать с классами абстрактных объектов,
определенными выше.
| Экземпляр
Заболевания |
| Свойство |
Тип |
Название заболевания
Дата заболевания
|
Ссылка на:Абстр.з-ние
Дата
|
| Метод |
Что возвращает |
|
|
| Экземпляр
Процедуры |
| Свойство |
Тип |
Процедура
Дата проведения
Заболевание |
Ссылка на:Абстр.проц-ра
Формат даты
Список ссылок на:
абстрактное заболевание |
| Метод |
Что возвращает |
|
Рис.15 |
|
Рис.16 |
В некоторых ООБД, особенно тех, которые
построены на вершине реляционной модели,
свойства не могут быть списками. В этом случае не
удивительно, что определения классов будут очень
похожи на реляционную структуру для этой
проблемы, описанную ранее.
| Пациент |
| Свойство |
Тип |
Имя Пациента
Номер Пациента
Дата рождения
Пол
Список заболеваний
Процедурный Список |
Текстовый
Цифровой
Дата
М/Ж
Список ссылок на: экземпляр заболевания
Список ссылок на: экземпляр процедуры |
| Метод |
Что Возвращает |
Добавить заболевание (название
заб-ния)
Добавить процедуру (название проц-ры)
Назначение : (№ списка процедур,
№ списка заболеваний) |
№ списка жалоб
№ списка процедур
<Ничего> |
|
Рис.17 |
Успех объектно-ориентированного подхода лежит
в смещении акцента со структуры данных (в
особенности, от вида связей между данными) к
процессу, с помощью которого эти данные
создаются, изменяются и уничтожаются. Реальные
структуры данных - деталь реализации, лучше всего
относящаяся к внутренней работе каждого класса -
и разные классы для обеспечения наивысшей
эффективности могут быть реализованы совершенно
по-разному. Ведение базы данных выполняется как
раз за счет знания методов и свойств,
предоставляемых классами.
Практические вопросы
Модель ООБД находится на более высоком уровне
абстракции, чем реляционные или древовидные БД,
поэтому классы можно реализовать, опираясь либо
на одну из этих моделей, либо на какую-нибудь еще.
Поскольку в центре разработки оказываются не
структуры данных, а процедуры (методы), важно,
чтобы выбиралась базовая модель, которая
обеспечивает достаточную прочность, гибкость и
производительность обработки.
Реляционные БД с их строгим определением
структуры и ограниченным набором разрешенных
операций, бесспорно, не подходят в качестве
базовой платформы для ООБД. Система М-языка/БД с
ее более гибкой структурой данных и более
процедурным подходом к разработке
представляется особенно хорошо приспособленной
для использования в качестве базовой платформы
для СУООБД. По-видимому,
объектно-ориентированный подход на базе М может
превзойти соответствующие реляционные аналоги
по скорости доступа и обработки.
Существует целый ряд коммерческих предложений,
которые являются "чистыми"
объектно-ориентированными СУБД. Таковы Objectivity,
Poet, Versant. Вообще говоря, эти системы относительно
незрелые и нуждаются в средствах разработки и
обслуживания, которые необходимы для реализации
и сопровождения многомасштабных БД. Более того,
эти объектно-ориентированные системы
оказываются достаточно медленными при доступе к
большим БД, проигрывая в эффективности
реляционным и древовидным БД. По сравнению с
сегодняшними весьма большими и сложными базами
данных, основанными на реляционных и
иерархических системах, базы данных,
сконструированные с использованием ООБД
относительно малы и просты. Это часть
рассматривается как признак незрелости
технологии, но не как ограничение ее потенциала.
Резюме и рекомендации
Каждая из трех рассмотренных технологий
представления и обработки данных в БД имеет свои
преимущества и недостатки. Реляционная модель,
сегодня наиболее укоренившаяся и
поддерживаемая, вероятно останется такой по
крайней мере еще несколько лет. Она также
является парадигмой наиболее строгой структуры,
что работает как в ее пользу, так и против нее.
Функциональные требования СУБД фактически
диктуют структуру базы данных, что приводит к
большему единообразию стиля, который легче
поддерживать. С другой стороны, данные,
естественным образом не укладывающиеся в
табличную схему, требуют особенно сложных
структур, которые не назовешь интуитивно
прозрачными, а значит, усложняющих сопровождение
БД. Кроме того, реляционные базы почти полностью
определяются структурой, а не процедурами
(методами). Это упрощает документирование БД с
помощью утилит словаря данных и требует меньше
"внутреннего" программирования. С другой
стороны, если спецификации БД неустойчивы или
развиваются, то нужно произвести изменения на
уровне словарей данных, что обычно влечет за
собой временную недоступность данных и
пересмотр описания ее структуры.
БД с древовидной структурой (например, М) по
своей природе значительно менее
структурирована, чем эквивалентная реляционная
БД. Это допускает большую свободу в
конструировании БД, что в свою очередь позволяет
повысить эффективность и/или
"естественность" модели данных. Кроме того,
гибкость и процедурная природа этих БД облегчает
их адаптацию к изменениям функциональных
спецификаций, неизбежным по мере развития базы
данных. Дополнительные и незапланированные
элементы данных зачастую могут добавляться без
закрытия доступа к БД, а новые операции - без
структурного изменения данных.
С другой стороны, повышенная гибкость ведет к
дополнительному "утяжелению" документации
в виде "местных" стандартов на структуры
данных и программ. Неспособность адекватно
задокументировать процедурно-структурный
характер базы данных приводит к значительно
большим проблемам на стадии сопровождения, чем в
случае реляционных БД. Бремя документации может
оказаться чересчур тяжелым, если моделируемые
данные естественным образом укладываются в
двумерные таблицы.
Объектно-ориентированный подход к системам БД
широко разрекламирован как грядущая парадигма,
которая заменит реляционную модель через
несколько лет. Он действительно дает большую
гибкость по сравнению с реляционной моделью и
позволяет сосредоточить внимание при разработке
и документировании на описании отдельных типов
предметов, а не на общей структуре базы данных.
Это обещает быть особенно полезным при
построении сложных систем БД, которые имеют
различные типы данных, особенно, если часто
встречаются связи "многие-ко-многим",
которые по своей природе не годятся для таблиц.
К сожалению, объектно-ориентированный подход
пока не столь широко испытан и не настолько
"зрел", как остальные два подхода. Наиболее
доступный подход к объектно-ориентированной БД -
это наложить ее на реляционную или древовидную
модель. Так как ООП в большей степени связан с
процессом, чем со структурой, представляется, что
древовидная модель подходит лучше. Создавая ООБД
на основе реляционной структуры, приходится
жертвовать свободой, радовавшей на стадии
разработки, когда дело доходит до внедрения и
сопровождения.
Таким образом, выбор модели БД сводится к
тщательному изучению данных, которые должны быть
смоделированы, и доступных ресурсов. Базы данных,
которые стабильны, хорошо определены и легко
описываются в терминах двумерных таблиц, а также
нуждаются в широкомасштабной поддержке,
наилучшим образом строятся с использованием
реляционной СУБД, такой как Oracle или Sybase.
Развивающиеся и сложные БД, со множеством связей
"многие-ко-многим" и разреженными данными, и
которые определяются, главным образом,
процедурно, лучше подходят к древовидной модели
М. [Прим. ред. перевода: Достоин упоминания и
гибридный вариант, реализуемый путем
"натягивания" реляционной структуры на
древовидную (например, с помощью MSM-SQL). Это
позволяет совместить эксплуатацию
уникально-сложных приложений с внешним доступом
к данным из стандартных электронных таблиц и
генераторов отчетов, ориентированных на
реляционные базы (Excel, Access, ReportSmith и др.)]
Относительно маленькие БД, которые в
значительной степени определяются описываемыми
ими объектами и действиями, которые эти объекты
могут выполнять, наверное, лучше реализуются при
помощи объектно-ориентированного подхода.
Произойдет ли ожидаемый революционный переход к
ООБД путем наслаивания ООП поверх реляционной
модели или М, или же на основе чисто
объектно-ориентированной платформы, пока, к
сожалению, не известно.
Применяя изложенные соображения, справедливые
по отношению к новым проектам баз данных, при
модернизации существующих БД не следует
пренебрегать такими важными факторами, как тип
существующей системы и имеющиеся человеческие
ресурсы. Все три модели, ставшие предметом
обсуждения, способны отобразить одни и те же
данные. Сравнительные тесты различных систем
редки и часто противоречивы, но кажется
бесспорным, что проектировщик/разработчик,
знакомый с одной из этих технологий, может
создать более эффективную базу данных (с точки
зрения и времени, и пространства), используя те
средства, которые ему наиболее знакомы. Объем
ранее сделанных капиталовложений в программное
обеспечение и в подготовку кадров может легко
перевесить любые другие факторы в определении
лучшей платформы для создания БД.
