5.1.2. Физическая структура системы qWORD
Как часть М-системы Cache, qWORD (далее qW) представляет собой совокупность глобалов и программ. Как созданный сам на себе и являющийся частью самого себя собственно qW и написанные на нем приложения представляют собой совокупность базовых классов, которые, в свою очередь, представляют собой совокупность объектов (методов и свойств).
Физически qW реализован на языке СУБД Cache’ и поэтому данные хранит в виде глобальных разряженных деревьев с символьной упорядоченностью узлов. Представление данных объекта qWORD можно упрощенно описать в виде деревьев: ^Словарь и ^Таблица№. Знак “^” в именованной метке дерева означает в СУБД Cache’, что это дерево должно хранится в БД. Деревья имеют следующие структуры: ^Таблица№ (‘Код Записи’, ‘Название Атрибута’) = ‘Значение Атрибута’ и ^Словарь(‘Название Атрибута’, ‘Значение Атрибута’, ‘Номер Таблицы’, Код Записи)
= "". Один экземпляр такого объекта представляет собой, обычно, совокупность нескольких деревьев ^Таблица№ (их названия отличаются №) и части дерева ^Словарь, которая определяется совокупностью названий атрибутов, включенных в этот экземпляр объекта. Каждое дерево ^Таблица№ определяет массив данных, который можно рассматривать как таблицу со столбцами, именованными названиями имеющихся в этой таблице атрибутов, и строками, именованными кодом записи. Значения дерева ^Таблица№ являются полями этой таблицы и именуются как значения атрибутов (табл. 5.1).Таблица 5.1
Название Атрибута 1 |
Название Атрибута 2 |
… |
Название Атрибута m |
|
Код Записи 1 |
Значение атр. 11 |
Значение атр. 12 |
… |
Значение атр. 1m |
Код Записи 2 |
Значение атр. 21 |
Значение атр. 22 |
… |
Значение атр. 2m |
… |
… |
… |
… |
… |
Код Записи n |
Значение атр. n1 |
Значение атр. n2 |
… |
Значение атр. nm |
В каждой таблице названия всех столбцов и строк разные. Для любых двух таблиц в пределах одной БД совпадение кодов записей никакой роли не играет, а совпадение части названий атрибутов, напротив, весьма существенна, так как обеспечивает связь между разными таблицами. Связь осуществляется через общие значения атрибутов с одинаковыми названиями. Иногда бывают связаны таблицы из разных экземпляров объектов, что свидетельствует, в этом случае, о связанности этих экземпляров между собой.
Связь между таблицами осуществляется с помощью дерева ^Словарь, при условии, что значениями атрибутов являются слова (строки алфавитно-цифровых символов без пробелов). В объекте qWORD существует одно дерево ^Словарь для всей совокупности имеющихся данных. Дерево ^Словарь определяет массив данных, который можно рассматривать как множество словарей атрибутов, по одному на каждое название атрибута. Словарь атрибута можно рассматривать как совокупность отсортированных в алфавитно-цифровом порядке слов (значений соответствующего атрибута), записанных вертикально в столбце. Справа от этих слов приписана одна или несколько пар номер таблицы/код записи. Каждая такая пара это тот "адрес", куда входит это слово
(табл. 5.2).Таблица 5.2
Значение Атрибута 1 |
(‘Номер Таблицы’, Код Записи) 11 (‘Номер Таблицы’, Код Записи) 12 … |
Значение Атрибута 2 |
(‘Номер Таблицы’, Код Записи) 21 (‘Номер Таблицы’, Код Записи) 22 … |
… |
… |
Значение Атрибута n |
(‘Номер Таблицы’, Код Записи) n1(‘Номер Таблицы’, Код Записи) n2 … |
У каждого слова таких "адресов" может быть один или несколько. Два или несколько разных значений одного атрибута будут связаны между собой, если к ним приписаны одинаковые "адреса".
Структура словарей атрибутов и структура таблиц самодостаточны - любой из них достаточно для физического представления данных. Такое построение деревьев в объекте qWORD создает ряд преимуществ, которые будут отмечены ниже. Здесь только заметим, что в реляционной модели часто используется
операции сортировки, при которой множество записей рассматривается в алфавитно-цифровом порядке значений одного из атрибутов, участвующего в каждой записи этого множества. Структура дерева ^Словарь такова, что на физическом уровне структуры данных сортировка существует изначально для каждого из атрибутов, что позволяет не только увеличить производительность, но и хранить данные в сжатом виде.qW содержит в себе четыре основных программных класса: класс доступа к базе данных %qget, класс доступа к оконному интерфейсу (%qfw для CHUI и %qgw для GUI) , класс –библиотека отработки методов по умолчанию (%qg999, %qfu, %qf999) и класс-транслятор (%qft). Трансляция спроектированного объекта в исполняемый код осуществляется транслятором исходя из строк описания этого объекта. Полученный класс (%qf_№фрейма или qf_№фрейма) содержит в себе базовый алгоритм, описание всех экранных форм спроектированного объекта и тексты всех переопределенных методов. При исполнении методов, класс проверяет наличие в себе переопределенных методов и в случае их отсутствия обращается к модулю – библиотеке методов по умолчанию. Взаимодействие класса с базой данных и оконным интерфейсом осуществляется через упомянутые модули.
Основным классом в qW является экранная форма. Он содержит в себе совокупность исполняемых элементов – методов. В общем случае, метод qW представляет собой алгоритм, состоящий из других методов qW более низкого уровня, связанных между собой М-кодом. Совокупность всех имеющихся методов qW образует некоторую сетевую структуру
, на нижнем уровне которой находятся М-функции работы с базой данных ($ORDER, SET и др.) и функции работы с оконным интерфейсом. Для Пользователя доступен весь набор методов, из которых он может составить интересующий его алгоритм и оформить его в виде отдельного метода.В qW составление функции возможно двумя различными способами. Традиционный для различных программных инструментов способ – записать свой метод в модуль – библиотеку в соответствии с принятыми в qW правилами оформления. Нетрадиционный способ – переопределить некоторый имеющийся в qW метод некоторым образом. Второй способ более быстр, компактен и прост. Наличие возможности переопределения является несомненным достоинством qW как CASE- средства, поскольку позволяет существенно снизить требования к уровню знаний системных вещей qW.
Базовая классификация методов qW связана с их использованием в проектировании приложений. Различают два типа методов – Пользовательские и Рабочие. Пользовательские методы являются методами более высокого уровня и составлены из Рабочих методов.
Имена Рабочих методов состоят из четырех букв (без цифр). Если Рабочий метод может быть переопределен, то первая буква в имени характеризует уровень его возможного переопределения:
Умолчания этих методов содержатся в классах %qfu, %qf999(CHUI) и %qg999(GUI).
Если Рабочий метод не может быть переопределен, то первая буква характеризует принадлежность к классификационной группе:
Пользовательские методы подразделяются на методы отработки событий и небольшое количество сервисных методов, относимых по характеру своего использования к Пользовательским. Если Пользовательский метод может быть переопределен, то первая буква его четырехсимвольного имени, также как и у Рабочих методов, характеризует уровень возможного переопределения. Непереопределяемые пользовательские методы обычно начинаются на “c”.Три последних символа в именах методов отработки событий являются цифрами, образующими номер ассоциированного с этими методами события.
Пользовательские методы, в отличие от Рабочих, в большинстве случаев не имеют формальных параметров.
Существует три способа вызова методов qW:
Вызов оформляется в виде:
Явно задаваемые параметры Параметр1…Параметр6 индивидуальны для каждого метода, их может быть любое количество в пределах шести и может не быть вообще. Параметры могут быть обязательными и необязательными. Обязательные параметры должны быть заданы, необязательные могут быть пропущены. В качестве параметров возможно использование системных переменных. Если пропускается параметр в конце, то просто его не пишут, если в середине, то оставляют запятые – разделители. Например:
D D(“Имя”,Параметр1,Параметр2,Параметр3,Параметр4,Параметр5) – опускаем Параметр2 и Параметр5, получаем D D(“Имя”,Параметр1,,Параметр3,Параметр4).
Схема исполнения любого метода qW с использованием $$F и D представлена на рис. 5.1. В конечном итоге вызов метода осуществляется по ее имени, состоящем из 4 символов. Первый символ в имени определяет путь поиска программного текста этого метода. Если метод может быть переопределен, то его поиск сначала осуществляется в исполняемом классе (qf_№фрейма), а затем в модуле – библиотеке. Если не может быть переопределен, то сразу в модуле – библиотеке.
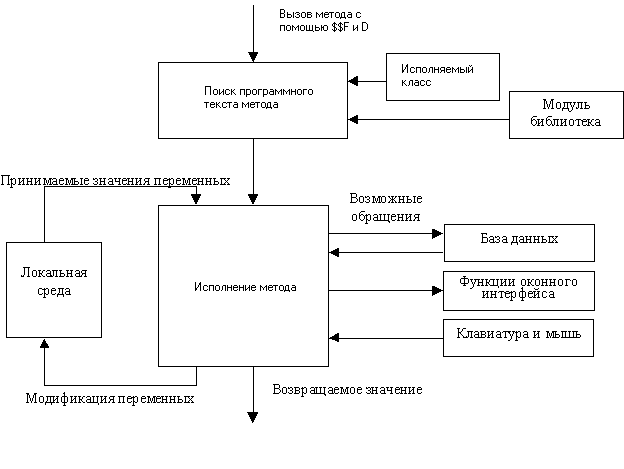
Рис. 5.1. Схема исполнения любого метода
qW с использованием $$F и DМетоды на z,у ищутся сначала на уровне текущего объекта класса экранной формы, потом на уровне текущей экранной формы, затем на уровне текущего объекта. Функции на s – начиная сразу с текущей экранной формы, на f только на уровне объекта.
В качестве входных параметров методов qW, в общем случае, использует явно задаваемые параметры и значения переменных, заимствованных из локальной среды qW (в локальную среду qW входят свойства системных объектов, служебные понятия и др.). В качестве выходных параметров метод возвращает в общем случае пустую или непустую строку и изменяет значения переменных локальной среды. В процессе исполнения некоторые из методов обращаются к базе данных, вызывают методы оконного интерфейса, ожидают событий от клавиатуры или мыши. Кроме того, как уже было сказано, метод может при помощи тех же $$F и D вызывать другие методы qW, схема исполнения которых будет точно такой же.
Подытожим сказанное. Как уже было сказано выше, все свойства и методы объектов хранятся в общей БД. Все методы реализованы как вызов некоторых М-функций. Имеется 4 основных класса, в которых записаны прототипы всех основных методов, разработчик имеет возможность переопределить фактически любой метод для любого объекта, причем действует принцип наследования - если метод не переопределен на уровне объекта, он ищется на уровень выше и т.д. до тех пор, пока будет не найден на том или ином уровне.
По описанию совокупности объектов (создаваемой дизайнером объектов) генерируется М-программа, их реализующая, в которую попадают все переопределенные точки входа. Выполнение этой программы обеспечивает функционирование совокупности определенных в ней объектов. Таким образом достигается настройка конкретных свойств и методов. Естественно, разработчику предоставляется дизайнер объектов, с помощью которого он определяет свойства и методы своих объектов. В настоящее время библиотека стандартных объектов весьма
обширна, что позволяет проектирование свести в основном к определению структуры БД, настройке экранных форм, переопределению функций представления информации в виде требуемых выходных форм.| Site of Information
Technologies Designed by inftech@webservis.ru. |
|