1.2. Этапы создания информационных
систем
Для успешной реализации проекта по созданию ИС объект проектирования (ИС) должен быть прежде всего адекватно описан, должны быть построены полные и непротиворечивые функциональные и информационные модели. Т.е. при разработке ИС должна быть
построена модель предметной области, произведено отображение этой модели в модель данных и по МД созданы физические структуры данных (рис.1.1).
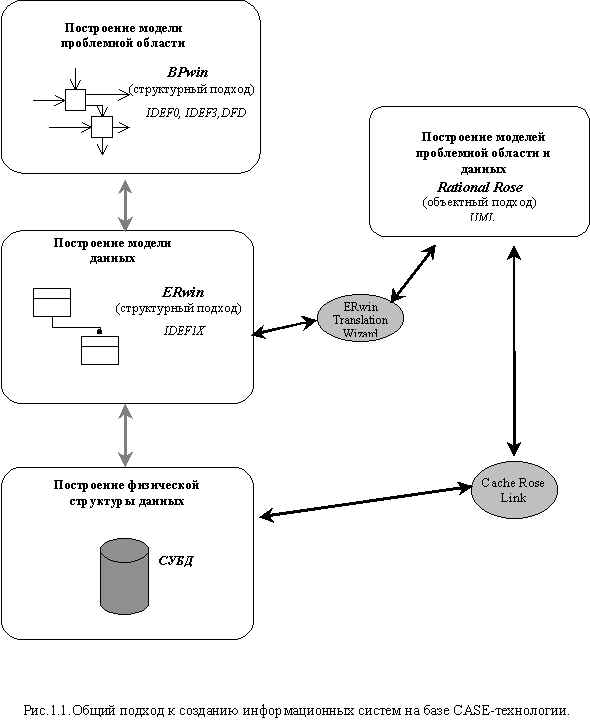
При проектировании сложной ИС ее разбивают на части, каждая из которых затем рассматривается отдельно. Возможны два различных способа такого разбиения ИС на подсистемы: структурное (или функциональное) разбиение и объектная (компонентная) декомпозиция.
Суть функционального разбиения хорошо отражена в известной формуле:
“Программа=Данные + Алгоритмы”.
При функциональной декомпозиции
программной системы ее структура может быть описана блок-схемами, узлы которых представляют собой “обрабатывающие центры” (функции), а связи между узлами описывают движение данных.Объектное разбиение в последнее время называют компонентным, что нашло отражение в специальном термине: "разработка, основанная на компонентах" (Component Based Development - CBD). При этом используется иной принцип декомпозиции - система разбивается на “активные сущности” – объекты или компоненты, которые взаимодействуют друг с другом, обмениваясь сообщениями и выступая друг к другу в отношении “клиент/сервер”. Сообщения, которые может принимать объект, определены в его интерфейсе. В этом смысле посылка сообщения "объекту-серверу" эквивалентна вызову соответствующего метода объекта. Большинство существующих CASE-средств опираются в основном на структурные методологии.
Примером системы, в которой осуществляется функциональное разбиение является BPwin (система моделирования потоков данных), поддерживающая методологии IDEF0 (функциональная модель) , IDEF3 (WorkFlow Diagram) и DFD (DataFlow Diagram) [2]. Функциональная модель предназначена для описания существующих бизнес-процессов на предприятии и идеального положения вещей – того, к чему нужно стремиться. Методология IDEF0 предписывает построение иерархической системы диаграмм – единичных описаний фрагментов системы. Сначала проводится описание системы в целом и ее взаимодействия с окружающим миром (контекстная диаграмма), после чего проводится функциональная декомпозиция – система разбивается на подсистемы и каждая подсистема описывается отдельно (диаграммы декомпозиции). Затем каждая подсистема разбивается на более мелкие и так далее до достижения нужной степени подробности. После каждого сеанса декомпозиции проводится сеанс экспертизы: каждая диаграмма проверяется экспертами предметной области, представителями заказчика, людьми, непосредственно участвующими в бизнес-процессе. Такая технология создания модели позволяет построить модель, адекватную предметной области на всех уровнях абстрагирования.
На основе модели процессов
BPwin с помощью другого CASE-средства - ERwin можно построить модель данных. Принято выделять два уровня представления модели данных – логический и физический.Цель моделирования данных на логическом уровне состоит в обеспечении разработчика ИС концептуальной схемой базы данных в форме одной модели или нескольких локальных моделей, которые относительно легко могут быть отображены в любую систему баз данных. Логический уровень
– это абстрактный взгляд на данные, на нем данные представляются так, как выглядят в реальном мире, и могут называться так, как они называются в реальном мире, например “Отдел”, “Фамилия сотрудника”. Объекты модели, представляемые на логическом уровне, называются сущностями и атрибутами. Логическая модель данных может быть построена на основе другой логической модели, например модели процессов. Такая модель данных является универсальной и никак не связана с конкретной реализацией СУБД (системы управления базой данных). Построение логической модели ИС до ее программной разработки или до начала проведения архитектурной реконструкции столь же необходимо, как наличие проектных чертежей перед строительством большого здания. Хорошие модели ИС позволяют наладить плодотворное взаимодействие между заказчиками, пользователями и командой разработчиков.На физическом уровне – данные, напротив, зависят от конкретной СУБД, фактически являясь отображением системного каталога. В физической модели содержится информация обо всех объектах БД. Поскольку стандартов на объекты БД не существует, физическая модель зависит от конкретной реализации СУБД. Следовательно, одной и той же логической модели могут соответствовать несколько разных физических моделей.
На логическом уровне проектирования строится так называемая визуальная модель объекта.
Визуальные модели обеспечивают ясность представления выбранных архитектурных решений и позволяют понять разрабатываемую систему во всей ее полноте. Построение визуальных моделей позволяет решить сразу несколько типичных проблем. Во-первых, и это главное, технология визуального моделирования, позволяет работать со сложными и очень сложными системами и проектами. И не важно, преобладает ли в проекте "техническая сложность" (статическая) или "динамическая сложность управления". Сложность программных систем возрастает по мере создания новых версий. И в какой-то момент наступает "эффект критической массы", когда дальнейшее развитие ИС становиться невозможным, поскольку уже никто не представляет в целом "что и почему происходит". Происходит потеря управлением проектом. Внешней причиной или толчком возникновения этого неприятного эффекта может послужить, например, увольнение ведущего программиста или системного аналитика.
Во-вторых, визуальные модели позволяют содержательно организовать общение между заказчиками и разработчиками. Шутка о том, что "заказчик что-то хочет, но точно не знает, чего именно", с завидным постоянством часто оказывается былью. А если на начальном этапе работы над проектом ИС заказчик думает, что точно знает, что хочет, то, как правило, и об этом свидетельствует богатый опыт, его требования изменяются ("плывут") в ходе выполнения проекта. С одной стороны, аппетит приходит во время еды, а с другой, высокая динамика бизнеса объективно заставляет менять требования к разрабатываемой (или поддерживаемой) ИС.
Визуальное моделирование не способно раз и навсегда решить все проблемы, однако его использование существенно облегчает достижения таких целей как:
Существует множество подходов к построению таких моделей: графовые модели, семантические сети, модель "сущность-связь" (ERD), UML и т.д.
Наиболее распространенным средством моделирования данных на настоящий момент являются диаграммы "сущность-связь" (используются в ERwin). С их помощью определяются важные для предметной области объекты (сущности), их свойства (атрибуты) и связи - отношения друг с другом (рис.1.2).
Каждая сущность является множеством подобных индивидуальных объектов, называемых экземплярами. Каждый экземпляр индивидуален и должен отличаться от всех остальных экземпляров. Атрибут выражает определенное свойство объекта. С точки зрения БД (физическая модель) сущности соответствует таблица, экземпляру сущности – строка в таблице, а атрибуту – колонка таблицы.
Построение модели данных предполагает определение сущностей и атрибутов, т.е. необходимо определить, какая информация будет храниться в конкретной сущности или атрибуте. Сущность можно определить как объект, событие или концепцию, информация о которых должна сохраняться.
Связь является логическим соотношением между сущностями. Каждая связь должна именоваться глаголом или глагольной фразой. Имя связи выражает некоторое ограничение или правило и облегчает чтение диаграммы.
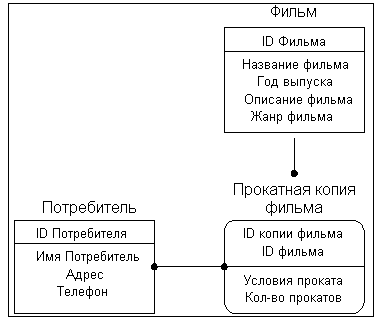
Рис.1.2. Пример ER-диаграммы.
Логическая модель данных должна быть отображена в компьютеро-ориентированную даталогическую модель, "понятную" СУБД. В процессе развития теории и практического использования баз данных, а также средств вычислительной техники создавались СУБД, поддерживающие различные даталогические модели.
Сначала стали использовать иерархические даталогические модели.
Иерархические БД состоят из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева.
Тип дерева состоит из одного “ корневого” типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждый из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи.
Пример типа дерева приведен на рис.1.3.
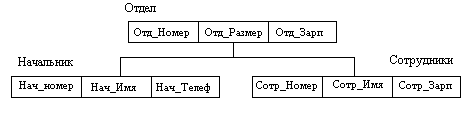
Рис.1.3. Иерархическая модель данных.
Здесь Отдел является предком для Начальника и Сотрудники, а Начальник и Сотрудники – потомки отдела. Между типами записи поддерживаются связи. Никакой потомок не может существовать без своего родителя, причем предок должен быть один.
Простота организации, наличие заранее заданных связей между сущностями, сходство с физическими моделями данных позволяли добиваться приемлемой производительности иерархических СУБД на медленных ЭВМ с весьма ограниченными объемами памяти. Но, если данные не имели древовидной структуры, то возникала масса сложностей при построении иерархической модели и желании добиться нужной производительности.
Сетевые модели также создавались для мало ресурсных ЭВМ.
Сетевой подход к организации данных является расширением иерархического. В этой модели потомок может иметь любое число предков.
Сетевая БД (рис.1.4) состоит из набора записей и набора связей между этими записями, а если говорить более точно, из наборов экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи. Тип связи определяется для двух типов записи: предка и потомка.
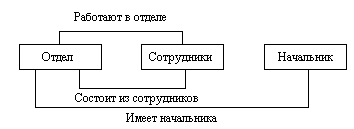
Рис.1.4. Сетевая модель данных.
При разработке сетевых моделей было выдумано множество "маленьких хитростей", позволяющих увеличить производительность СУБД, но существенно усложнивших последние. Прикладной программист должен знать массу терминов, изучить несколько внутренних языков СУБД, детально представлять логическую структуру базы данных для осуществления навигации среди различных экземпляров, наборов, записей и т.п. Один из разработчиков операционной системы UNIX сказал "Сетевая база – это самый верный способ потерять данные".
Сложность практического использования иерархических и сетевых СУБД заставляла искать иные способы представления данных. В конце 60-х годов появились СУБД на основе инвертированных файлов, отличающиеся простотой организации и наличием весьма удобных языков манипулирования данными. Однако такие СУБД обладают рядом ограничений на количество файлов для хранения данных, количество связей между ними, длину записи и количество ее полей.
Сегодня наиболее распространены реляционные
(основанные на двумерных таблицах) модели данных (рис.1.5). Любая система данных, не имеет значения какой сложности, может быть сведена к набору таблиц (или "отношений" в терминологии СУРБД). Каждое отношение (таблица) может быть представлено в виде прямоугольного массива со следующими свойствами:Строки обычно называют записями, а столбцы – полями.
Вообще, лишь немногие реальные базы данных могут быть описаны при помощи единственной таблицы. Большинство приложений используют множество таблиц, которые содержат столбцы (поля) с одинаковым именем. Эти общие данные позволяют объединяя две (или несколько) таблицы, строить осмысленные ассоциации.
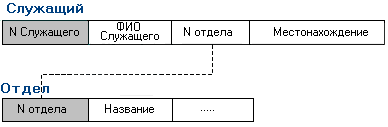
Рис.1.5. Реляционная модель данных.
К числу достоинств реляционного подхода можно отнести:
Реляционные системы далеко не сразу получили широкое распространение. В то время как основные теоретические результаты в этой области были получены еще в 70-х, и тогда же появились первые прототипы реляционных СУБД, долгое время считалось невозможным добиться эффективной реализации таких систем. Однако отмеченные выше преимущества и постепенное накопление методов и алгоритмов организации реляционных баз данных и управления ими привели к тому, что уже в середине 80-х годов реляционные системы практически вытеснили с мирового рынка ранние СУБД.
Несмотря на всю свою привлекательность и “привычность”, классические реляционные системы управления базами данных являются ограниченными. Они идеально походят для таких традиционных приложений, как системы резервирования билетов или мест в гостиницах, а также банковских систем, но их применение в системах автоматизации проектирования, интеллектуальных производственных системах и других системах, основанных на знаниях, часто является затруднительным. Это, прежде всего, связано с примитивностью структур данных, лежащих в основе реляционной модели данных. Плоские нормализованные отношения универсальны и теоретически достаточны для представления данных любой предметной области. Однако в нетрадиционных приложениях в базе данных появляются сотни, если не тысячи таблиц, над которыми постоянно выполняются дорогостоящие операции соединения, необходимые для воссоздания сложных структур данных, присущих предметной области.
Другим серьезным ограничением реляционных систем являются их относительно слабые возможности по части представления семантики приложения. Самое большее, что обеспечивают реляционные СУБД – это возможность формулирования и поддержки ограничений целостности данных. Осознавая эти ограничения и недостатки реляционных систем, исследователи в области баз данных выполняют многочисленные проекты, основанные на идеях, выходящих за пределы реляционной модели данных.
В качестве других недостатков реляционных СУБД отмечаются следующие:
Объектно-ориентированные базы данных относительно новы, теория баз данных не имеет такой хорошей математической основы как реляционные или древовидные модели. Тем не менее, это не должно обязательно рассматриваться как признаки слабости, присущие данной технологии моделирования. Свойства, представляющиеся общими для большинства реализаций БД, таковы:
1. Абстракция: Каждая реальная "вещь", которая хранится в БД, является членом какого-либо класса. Класс определяется как совокупность свойств, методов, общедоступных и частных структур данных, а также программы, применимых к объектам (экземплярам) данного класса. Классы представляют собой ни что иное, как абстрактные типы данных. Методы - это процедуры, которые вызываются для того, чтобы произвести какие-либо действия с объектом (например, напечатать себя или скопировать себя). Свойства - это значения данных, связанные с каждым объектом класса, характеризующие его тем или иным образом (например, цвет, возраст).
2. Инкапсуляция: Внутреннее представление данных и деталей реализации общедоступных и частных методов (программ) является частью определения класса и известно только внутри этого класса. Доступ к объектам класса разрешен только через свойства и методы этого класса или его родителей (см. ниже "наследование"), а не путем использования знания подробностей внутренней реализации.
3. Наследование (одиночное или множественное): Классы определены как часть иерархии классов. Определение каждого класса более низкого уровня наследует свойства и методы его родителя, если они только они явно не объявлены ненаследуемыми или изменены новым определением. При одиночном наследовании класс может иметь только один родительский класс (т.е. классовая иерархия имеет древовидную структуру). При множественном наследовании класс может происходить от многочисленных родителей (т.е. иерархия классов имеет структуру ориентированного нециклического графа, не обязательно древовидную).
4. Полиморфизм: Несколько классов могут иметь совпадающие имена методов и свойств, даже если они считаются различными. Это позволяет писать методы доступа, которые будут правильно работать с объектами совершенно различных классов, лишь бы соответствующие методы и свойства были в этих классах определены.
5. Сообщения: Взаимодействие с объектами осуществляется путем посылки сообщений с возможностью получения ответов.
Каждый объект, информация о котором хранится в ООБД, считается принадлежащим какому-либо классу, а связи между классами устанавливаются при помощи свойств и методов классов.
Модель ООБД находится на более высоком уровне абстракции, чем реляционные или древовидные БД, поэтому классы можно реализовать, опираясь либо на одну из этих моделей, либо на какую-нибудь еще. Поскольку в центре разработки оказываются не структуры данных, а процедуры (методы), важно, чтобы выбиралась базовая модель, которая обеспечивает достаточную прочность, гибкость и производительность обработки.
Реляционные БД с их строгим определением структуры и ограниченным набором разрешенных операций, бесспорно, не подходят в качестве базовой платформы для ООБД. Более приспособленной для использования в качестве базовой платформы для СУООБД представляется система М-языка с ее более гибкой структурой данных и более процедурным подходом к разработке. По-видимому, объектно-ориентированный подход на базе М может превзойти соответствующие реляционные аналоги по скорости доступа и обработки.
| Site of Information
Technologies Designed by inftech@webservis.ru. |
|