3. Разработка структуры данных “Обобщенный Документ”
Как правило реальные данные в проблемной области имеют иерархическую структуру, поэтому целесообразно использовать объекты БД имеющие идентичную структуру. В связи с этим на основе общих возможностей и компонент
CASE – средства qWORD5 разработана новая структура данных, названная “Обобщенный документ” (ОД).Новая структура данных - это просто реализация одного из возможных вариантов построения БД и интерфейсных элементов, разработанная с помощью общего метода переопределения свойств и методов
. Все стандартные методы, отличные от общих методов qWORD5-PRO, переопределены для фрейма № 25.В Обобщенном документе мы имеем дело с одним-единственным объектом данных, называемым - документ. Как структура данных, он представляет из себя совокупность записей с атрибутами. Документы одинаковой структуры группируются в папки. Документ состоит из шапки и документострок. Любая документострока в свою очередь может иметь подстроки и т.д. Любой документ однозначно характеризуется кодом экземпляра документа. Совокупность всех папок с содержащимися в них экземплярами документов образуют базу.
Структуру данных документа можно представить в виде некоторой иерархии уровней, где на первом уровне сгруппированы реквизиты, названные шапкой, на втором - документостроки, и так далее. Любой реквизит на любом уровне называется понятием. Структура документа приведена на рис.3.1. Для её описания достаточно определить следующие вещи для каждого уровня:
· список понятий, находящихся на этом уровне;
· правило порождения кода этого уровня .
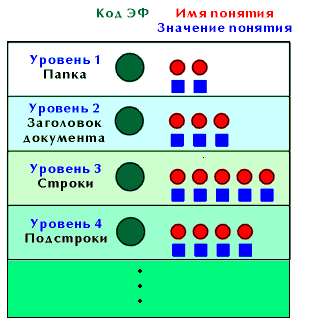
Рис.3.1. Структура Обобщенного документа
На уровне папки хранится описание данного вида документа, включающее в себя следующие системные понятия:
Для однозначной идентификации документа (вообще говоря, любых его реквизитов-понятий, находящихся на любом уровне иерархии) используется также как и для любого фрейма в
qW т.н. структурированный ключ.
Ключ=Папка#ключ1#ключ2#ключ3#...
В таком случае естественно говорить об уровнях:
Папка#ключ1)
,
Папка#ключ1#ключ2),
(Папка#ключ1#ключ2#ключ3)
и так далее. На каждом уровне могут быть привязаны понятия, скажем, на уровне 2 - номер_документа, дата_документа, на уровне 3 - наименование_товара, количество_по_накладной и т.п. При такой структуре кода, зная значение кода для экземпляра понятия третьего уровня, мы сразу знаем значения кодов экземпляров понятий этого экземпляра документа, лежащих на более высоких уровнях.
Это оказывается очень удобным при различных поисках, когда найдя, например, ссылки на все строки с определенным видом товара, мы автоматически найдем связанные с ними номера документов, или еще что-нибудь.
Для быстрых поисков по базе данных значения понятий могут иметь словарь значений понятий.
Словарь[Имя_понятия][Значение_понятия]=ключ
Связь между словарем данных и объектом данных устроена очень просто - каждое хранимое в словаре значение имеет ссылку на требуемый код экземпляра объекта данных (фрейм) (см. рис. 2.2).
| Site of Information
Technologies Designed by inftech@webservis.ru. |
|