Глава 8. Инженерия систем “интеллектуальной направленности”
8.1. Три основных подхода
8.2. Первый подход. Идеология
операционной системы
8.3. Второй подход. Идеология
инструментальной системы
8.3.1. Основная объектная триада и
динамически раскрываемый объект
8.3.2. Иерархии и процессы
8.3.3. Концепция открытой СУБД
8.3.4. Реализация раскрываемости
8.3.5. Унифицированное представление
объекта
8.3.6. Инструментальная концепция –
технология qWord
8.3.7. Куда делась семантика?
8.3.8. Проблемы саморазвивающиеся баз
8.3.9. Почему “в Cache’-технологии”
8.4. Третий подход. Специализированная
производственная операционная система
8.5. Самосовершенствование ИСУ
Глава 8. Инженерия систем “интеллектуальной направленности”
8.1. Три основных подхода
Какие же механизмы и практические решения в наибольшей степени соответствуют инженерии субъектно-объектного подхода? Те и только те, которые достаточно корректно обращаются со структурой данных соответствующей проблемной области – следуют за изменением структуры данных, но не навязывают информационному процессу заранее спроектированную структуру. В этом смысле проблему создания сложных информационных систем наиболее целесообразно рассматривать исходя из трех возможных подходов.
Во-первых, можно поставить задачу создания универсальной, для некоторой достаточно широкой области приложений, операционной системы – интегрированной среды с собственной базой постреляционной или объектной структуры. Такая среда может быть основана на чисто программистских интересах организации работы с динамическими информационными структурами и требовать минимальных дополнений для учета индивидуальных динамических структурных особенностей того или иного приложения.
Во-вторых, можно начать работу с создания программного инструмента, обеспечивающего решение проблемы восприятия, упаковки и обработки самой сложно организованной информации, поступающей на вход системы. В известной степени это путь сведения некоторой уже существующей операционной системы к первому подходу. Еще лучше, когда такой инструмент сопутствует операционной системе, выполненной как ориентированная операционная среда, т.е. дополняет первый подход.
В третьих, для особо сложных объектов целевого назначения полезно сразу создавать специализированную операционную систему, например, производственную, ориентированную на получение и поддержку структур данных в заранее определенном и достаточно широком диапазоне ее изменения. Если некоторый объект можно считать организационно (в своих внутренних организационных связях) постоянным в некоторых пределах, то это хотя и дорогое, но, возможно, лучшее из решений.
В известной степени это подходы объединены одной целью – созданием некоторой среды, требующей минимальных затрат на предварительную структуризацию (априорное проектирование структур представления) информации (в пределе вообще их не требующей), но имеющей для этого собственные внутренние инструментальные возможности при максимальной автоматизации такого рода работ.
Остальные подходы, связанные с проектированием сложной информационной системы на универсальном алгоритмическом языке того или иного уровня, мы рассматривать не будем, исходя из заведомой громоздкости получаемых решений, их “слишком явного” кибернетического уровня и известной проблемы невозможности сколько-нибудь эффективной коррекции структур информационных баз при проектировочном подходе, неизбежном для языков, непосредственно ориентированных на архитектуру фон Неймановского компьютера.
Перечисленные же выше подходы в той или иной степени позволяют создавать информационные системы, которые вполне можно рассматривать как “половинки” интеллектуальных баз, в некоторой степени пригодные для создания интеллектуальной системы в ее “инженерном” определении.
Для иллюстрации сказанного рассмотрим некоторые характерные особенности реализации указанных выше подходов на примере нескольких типичных систем, которые в задании на их проектирование не содержали требования какой-либо “интеллектуальности”. Эти системы были построены только исходя из удобства разработки и сопровождения приложений, эффективности в эксплуатации, т.е. строились исходя из “чистой” идеологии первых трех подходов, но, по фактическому результату, явились существенными шагами именно в сторону создания интеллектуальных систем.
8.2. Первый подход. Идеология операционной системы
В настоящее время идеологии первого подхода в наибольшей степени отвечают работы американской корпорации InterSystems.
В 1998 г. InterSystems выпустила на рынок новый продукт Cache’-технологию – интегрированную среду, постреляционную базу для эффективной разработки приложений. В соответствии с документацией по архитектуре Cache’ и некоторым практическим опытом можно сказать следующее.
Cache’-технология от InterSystems представляет собой полностью интегрированную высокопроизводительную систему управления базами данных и среду быстрой разработки современных приложений, ориентированных на обработку транзакций. Cache’ – это СУБД, основанная на Транзакционной Многомерной Модели Данных (ТММД). Она обеспечивает одновременную работу практически любого (речь идет уже о десятках тысяч) числа клиентов без потери производительности, при затратах несравнимо меньших, чем в любом другом решении.
Обратимся к архитектуре Cache’ (рис. 8.1). Поддержка ODBC обеспечивает совместимость с SQL-стандартом. Visual Cache предоставляет доступ к объектам Cache’ из Visual Basic и других средств разработки. Weblink поддерживает доступ из Web-приложений к базе данных Cache’. Cache’ ObjectScript – это объектно-ориентированный язык программирования. Кроме того, объекты Cache’ могут создаваться и изменяться с использованием Java и C++.
ODBC |
Visual Cache’ |
WebLink |
Cache’ ObjectScript/Java/C++ |
||
Прямой доступ |
SQL |
Объектный доступ |
Транзакционное ядро СУБД |
||
Протокол Распределеннного Кэша |
||
Рис. 8.1. Архитектура Cache’.
Три способа доступа к базе данных – прямой, реляционный и объектный, обеспечивают производительность, межсистемное взаимодействие и быструю разработку приложений. Транзакционное ядро обеспечивает высокую производительность и масштабируемость прикладных систем. Протокол Распределенного Кэша расширяет масштабируемость приложений “клиент-сервер” и обеспечивает “прозрачный” доступ к базе данных в сетях любого размера.
В отличие от так называемых “больших СУБД” реализация имеет ряд фундаментальных структурных особенностей:
Таким образом, выстраивается четкая иерархия “вложенных виртуальных машин” в отличие от предыдущих проектов, где господствовала тенденция “погружения” логической модели проблемной области непосредственно в физическую модель данных.
Другая особенность проекта – четкая ориентированность подхода на непрерывную разработку приложений в процессе эксплуатации – “обеспечение динамики существования динамических систем”.
Наконец, третий важный компонент – ТММД, предполагающая не набор заранее определенных реляций, но многомерную структуру априори неопределенной размерности. Тем самым обеспечивается создание, в сущности, универсальной структуры модели данных, инструмента для конструирования структур “по ходу дела”, в процессе создания и эксплуатации приложения.
Можно спросить, а где же здесь интересующая нас “интеллектуальность” или подходы к ней?
Если подразумевать под этим какой-то специфический прием или формализм, то такового здесь изначально вроде бы и нет. Но уже указанная иерархия вложенных виртуальных машин, собственная изначальная древовидная структура, явная направленность на обеспечение работы с динамическими связями данных говорят сами за себя. В подходе Cache’ то и замечательно, что система и технология, позволяющая реализовать в принципе любые наборы таких специфических средств и приемов, возникла из соображения чисто практического – создания универсального “коробочного” продукта.
Пожалуй, единственное, что представляется здесь проблемным – это наличие, даже акцентирование на ТММД – модели данных, реализованной как набор программ. Коль скоро она реализована в виде набора некоторых программ, то сама является формализмом. Разумеется, раз она транзакционная, более богатым возможностями, чем любые наборы реляционных таблиц, но все же не более чем формальной моделью, а, значит, необходимо имеющей свои внутренние ограничения.
Впрочем, с одной стороны сомнение это чисто (пока не показала практика эксплуатации) теоретическое, а с другой, что более важно, эти ограничения не должны проявляться при организации, на основе схемы субъектно-объектного взаимодействия, инженерных информационных (интеллектуальных) систем на базе Cache’-технологии, при некоторой минимальной аккуратности процесса их создания.
8.3. Второй подход. Идеология инструментальной системы
Не менее интересной и с практической, и с теоретической точки зрения представляется инструментальная система qWord{101. Автор и генеральный разработчик – А.Н.Долженков, организация СП.АРМ [30].} как реализация технологии открытых систем управления данными. Одно из главных положений qWord-технологии – полная интеграция инструментальной и прикладной систем в единое целое. При этом модель проблемной области совсем уходит из программной реализации как целостный логический объект, остается вовне, в проблемной области, т.е. там, где она и была изначально.
Текущая реализация отображения модели (или совокупности таковых), которая присутствует в прикладной системе по умолчанию, считается не более чем одномоментной реализацией того состояния объекта (проблемной области), которое на этот момент доступно и актуально для пользователя. То есть становится в точности тем, что она (эта реализация) и есть на самом деле, и никак не более того.
С другой стороны, благодаря полной интеграции инструментальных средств и свойству “самоописания” системы, появляется реальная возможность использования сколь угодно сложных априори неопределяемых “объектов”, количество которых в принципе конструктивно бесконечно.
Предлагаемое изложение qWord технологии и, если смотреть более широко, вообще новой технологии создания СУБД, СУБЗ, “хранилищ знания” и тому подобного, носит здесь в значительной мере обобщающий, методологический характер в соответствии с основной целью написания этого раздела. Более детальное описание просто скрыло бы крайне важные как теоретические, так и чисто практические аспекты во множестве частных подробностей.
Крайне интересным при рассмотрении qWord представляется ответ на вопросы:
Начнем с рассмотрения смысла понятия “адекватно устроенной” системы.
8.3.1. Основная объектная триада и динамически раскрываемый объект
Для начала напомним интуитивное понятие объекта в том виде, в котором оно стало более или менее общепринятым в объектном подходе к представлению информационных систем, например, в точно том же смысле, что и объекты Cache’.
Объект (проблемный, программный или абстрактный) это то, что некоторым “естественным” образом делится на декларативную и процедурную (“процессную”) части и, таким образом, может быть адекватно отображено в подходящие структуры данных и программы в компьютерной системе (КС), имея в виду под КС не аппаратный комплекс, но некоторую информационную, расчетную, вообще любую систему, реализованную в компьютерной среде.
Обратим внимание на то, что здесь речь фактически идет о трех существенно различных объектах. В общем случае мы не имеем права считать их разными реализациями одного и того же объекта, поскольку это (их единство) только цель создания системы, а не состоявшийся факт. Обычно и в теоретических публикациях, и в программной документации все ясно из контекста и путаницы не возникает, но здесь нам важно напомнить, что объекты проблемной среды, реализации объектов в абстрактной модели данных и программные реализации объектов различны по своему существу.
Создание КС обычно понимается как создание модели данных, декомпозиция проблемной среды на “естественные объекты” и отображение их в “объекты КС”. Обратим внимание на то, каждый из объектов КС в свою очередь должен содержать два компонента: представление объекта и отображение этого представления на адресное пространство.
Фактически конструируется не одна модель данных, но сразу и параллельно все вышеупомянутые три модели, а именно: модель проблемной среды и ее отображение в КС, которое, в свою очередь, автоматически декомпозируется в две модели – абстрактную модель данных, ту, что отображает на экране навигатор модели данных (например, ТММД в Cache’) и внутреннюю, скрытую от пользователя реализацию отображаемой абстрактной модели.
Отчасти подмена происходит из-за того, что модель проблемной среды является существенно внешней, находится целиком вне КС, однако это вовсе не означает, что “ее нет совсем”, это как раз та система умолчаний, которая складывается в восприятии пользователя, то самое, что подсказывает пользователю, как понимать абстрактную модель отображаемую навигатором.
Механическое сведение всего процесса к одной только абстрактной модели данных приводит к тому, что теряется и само понимание этого процесса, а именно понимание того, что вне зависимости от желания пользователя абстрактная модель “самостоятельно” раскрывается и внутрь и наружу. При этом теряется и свойство, и сам процесс динамической раскрываемости представления. Очевидно, что конструирование любой КС должно выполняться так, чтобы не произошла потеря этого свойства динамической раскрываемости, чтобы реализация представления (объекта) не препятствовала возможности осуществления очередного шага раскрытия в любой момент существования КС. Но это лишь одна “плоскость”, в которой проявляется свойство раскрываемости представления.
Здесь мы будем рассматривать подмножество КС – информационные системы, подразумевая под этим, там где это не вызовет разночтений, всю совокупность таковых от традиционных СУБД до “систем знания” и т.п. Мы должны констатировать, что раскрываемость представления может проявляться в самой широкой совокупности аспектов, поскольку раскрываемость не введена нами, но есть атрибутивное свойство любого представления.
Эта достаточно рядовая ситуация. Коллизии, возникающие при расширении реляционных таблиц – это утрата адекватной раскрываемости реляционного представления (абстрактной, реализованной внутри КС, модели данных), требующая пополнения или реорганизации каталогов. Необходимость реорганизации диска, когда уже не помогает навигатор в каталогах – это ситуация, когда утрачивается раскрываемость внешней модели, представления, лежащего вне КС.
Наконец, достаточно распространена ситуация, когда программист нарушает балансировку В*-деревьев, что приводит к катастрофической неэффективности работы базы данных. Сказанным мы хотим напомнить простую, но всегда полезную истину – если списать проявления какой-то проблемы, свойства природного явления на действия некоторого частного механизма, частной модели, то сама проблема от этого никуда не исчезнет, зато неприятности гарантированы, вплоть до полной утраты понимания сущности самого явления.
Следовательно, мы обязаны считать, что минимальной структурой, адекватной задаче создания информационной системы, является совокупность взаимосвязанных динамических объектов: проблемная среда (ПС) – информационная система (ИС) – пользователь (П). Назовем эту совокупность основной объектной триадой (ООТ).
ПС и ИС являются совокупностями взаимосвязанных объектов. Но такой же совокупностью объектов является и пользователь, если учесть, что мы обязаны рассматривать не отдельный его запрос или совокупность запросов, но всю историю его работы, то есть всю совокупность задач{102. Мы обязаны включить сюда и все ошибки пользователя, и все некорректные ситуации, вызванные неверной трактовкой им ПС или содержания и возможностей ИС.}, решаемых пользователем с помощью ИС.
Представляется очевидной соподчиненность, иерархия объектов и вовсе не очевидной предложенная расширенная трактовка задачи. Действительно, казалось бы, достаточно расширить стандартную трактовку объекта до его “расширения наружу” и “раскрытия внутрь”{103. Терминология так называемой “концепции расширяющегося объекта”.}, т.е. рассматривать только одну “обобщенную модель данных”, как это до сих пор и принято. Но это возможно и справедливо только до момента реструктуризации данных в ИС, а именно это и интересно, если мы собираемся говорить о случаях нетривиальных, тем более – о “самоструктурировании” или “интеллектуальности”.
В простейшем случае единичного пополнения или запроса, приводящего к реструктурированию, иерархия процессов опрокидывается, главным источником активности становятся структуры данных в ИС. Если же необходимость реструктуризации вызвана последовательностью пополнений и запросов, то необходимо порождение целых иерархий процессов, то есть комплексный “откат” непрогнозируемой глубины.
Важно то, что при начале акта реструктурирования иерархия процессов переворачивается, активность исходит от структур, реализующих абстрактную модель данных, затем пользователь с помощью навигатора абстрактной модели данных выясняет существо несовпадения текущей реализации этой модели и объекта проблемной среды. Только после этого пользователь принимает решение и задает конкретный вид реализации модели, т.е. производит собственно реструктуризацию. Процесс имеет именно такой вид даже в случае самой простейшей СУБД. Таким утверждением мы ничего не “открываем” и не “изобретаем” – просто честно констатируем реальную ситуацию.
Сказанное означает, что адекватное раскрытие объекта как “наружу”, так и “внутрь” в реальности достигается только в динамическом процессе взаимодействия объектов и процессов, составляющих ООТ.
Иначе говоря, объект, моделирующий ИС или ее часть (имеется в виду программная реализация объекта), является адекватным представлением ПО, если по умолчанию имеет свойство динамической раскрываемости. Успех любой ИС заключается в том, насколько эффективно это удалось реализовать{104. Интуитивно почти очевидно, вся история ИС к этому и шла. Вопрос лишь в том, как это положить в реализацию, в коды.}.
8.3.2. Иерархии и процессы
Чтобы реализовать динамическую раскрываемость объектов надо навести некоторый порядок в понимании, что есть иерархия и процессы и как они взаимодействуют. Написано по этому поводу много, поэтому ограничимся только констатацией некоторых важных фактов.
По ходу отладки СУБД и реструктуризации БД мы наблюдаем как начальные, стартовые иерархии объектов и процессов изменяются, более того фактически само это изменение и есть содержательная часть реструктуризации – порождение новых отношений и процессов.
Известная идеология Get Up (GU) и Check Up (CHU) интерфейсов обслуживает только два типа процессов, а именно:
Для обслуживания третьего, собственно и представляющего для нас интерес типа процессов, а именно, разрушающих глобальную среду, адекватного формализма нет, его просто до сих пор и не пытались создавать. Поэтому здесь мы берем труд и ответственность на себя и вводим третий тип процессов с идеологией Crash Restore (CRR).
Весьма полезно рассмотреть, как получилось, что самый важный тип процессов, ради которого собственно все и делается, просто не заметили.
Все проектируемые СУБД существуют по единой “схеме жизни”. Во-первых, конструируется модель ПО. Во-вторых, эта модель отображается в модель данных (МД) и уже по ней создаются физические структуры данных. Далее, на практике, при наступлении события, вызывающего реструктуризацию, работает следующая последовательность:
Заметим теперь, что то же самое мы наблюдаем на аппаратном уровне при обработке прерывания от сбоев шины памяти (или блока). Если аппаратура снабжена средствами резервирования и некоторым механизмом типа “межблочного кэша”, то она будет сопротивляться сбоям, обходясь частичными горячими перезагрузками, до тех пор, пока не будут исчерпаны возможности резервирования.
Возражение о непредсказуемости момента прерывания, тем более о его “месте” и “содержании, семантике” вполне правомочно и верно. Просто это не означает, что с глобальной средой можно и должно поступать так же, как и с локальной – иначе зачем их выделять хотя бы терминологически?
8.3.3. Концепция открытой СУБД
Для решения проблемы есть и такой путь – отделить логическую модель данных от модели организации физических записей, сделать их логически автономными. Но при этом, если соблюсти некоторые условия, нам ничто не помешает реализовать логическую модель в таких же структурах физических записей. Это крайне важно и методологически и практически.
Итак, структура СУБД “раскрывается зеркально относительно ПО”. Также как из ПО выделяется логическая модель (или модели), в СУБД возникает собственно структура БД и структура управления в виде динамически раскрываемого объекта.
Структура, реализующая БД, должна удовлетворять следующим требованиям:
Подходящей структурой является механизм В*-деревьев. Более того, нами доказано, что этот механизм является “глобально-минимаксным”{105. В В*-деревьях можно смоделировать любую структуру – это кажется уже не нуждается в пояснениях, как и тот факт, что разреженные массивы суть один из наиболее экономичных способов использования памяти. Доказательство сводится к следующему. Система В*-моделей всегда остается неполной, но эффективно пополняемой. За счет неполноты гарантирована непротиворечивость, т.е. эта модель не может сама породить коллизию, разрушающую глобальную среду. Напротив, любая “более богатая” логическая модель таковую породит неизбежно. Для каждого частного случая возможно подобрать представление, более экономичное, чем B*-деревья, но оно обязательно саморазрушится даже при простом пополнении данных на некотором шаге этого пополнения, т.е. БД физически разрушится даже без внешней причины (события), связанной с изменением логики модели данных. Отсюда получается ситуация минимакса – наиболее экономичное (в среднем по совокупности всех отображений) представление для потенциально бесконечного числа логических моделей.}. Раскрываемость управляющего объекта (структуры, управляющей БД), сводится к следующему.
Структура должна содержать компоненты:
Вообще говоря, это и не описания, а некоторое представление структуры, которая может быть, в том числе, и сама динамическим объектом со всеми его компонентами и свойствами.
Здесь мы должны сделать один из важнейших практических выводов. Если в такой структуре возникает событие, сигнализирующее о разрушении глобальной среды, это означает, что источник события можно однозначно локализовать либо во “внешней”, либо во “внутренней” части модели данных того объекта, который был в данный момент активен. Далее остается использовать соответствующие инструментальные средства и скорректировать модель данных, либо построить новую.
Физические структуры данных одномоментно и аварийно трогать нет необходимости – это можно сделать как фоновую работу в целях оптимизации ресурсопотребления.
Таким образом, реализация концепции открытости и есть тот самый инструмент для обработки процессов CRR типа. Собственно, никакого особого открытия здесь и нет – все по старому рецепту: чтобы расщепить аварийное и глобальное события надо адекватным образом устроить иерархию структур логической среды, т.е. расширить описание модели, определить некоторые имена, ключи и значения как зависящие от параметров, хотя при данном конкретном состоянии БД они являются просто декларативными значениями.
При таком подходе некая часть данных станет вычисляемой, причем в самом общем смысле (сборка-разборка по дереву и т.п. – тоже вычисления), а это неизбежно повлечет за собой затраты (память, быстродействие) возможно и очень большие.
Необходимо отметить следующее. Затраты неизбежны в любом случае, при любом способе расширения модели данных. Но в нашем случае их можно измерять, собирать статистику и контролировать (в Cache для этого есть встроенные средства). Эти затраты никогда не станут расти обвально, что неизбежно при априорном задании метаструктуры данных, либо при периодическом повторении процесса проектирования структуры БД. Фактически это эквивалентно обмену объема аппаратных затрат на затраты многократного возобновления проектирования.
8.3.4. Реализация раскрываемости
Выбор средства реализации раскрываемости подсказывает сама структура и способ раскрытия объекта. Внутрь, в сторону физических структур данных формализм уже есть, он определен алгеброй В*-деревьев, а также набором дополнительных правил, связанных с ограничениями, во-первых, языка реализации, а, во вторых, логической (операционной) среды и физической реализации (аппаратуры) в которой выполнен язык и продукт.
В каждой такой реализации существенно конечный набор правил можно считать “работающим по умолчанию”.
Далее естественно дополнить этот набор метаправилами отображения структуры объекта (модели данных) в правила языка реализации В*-моделей. Наконец, дополним набор гиперправилами отображения внешней логической модели в модель данных. В результате мы получим как бы “сдвоенную” W-грамматику, “склеенную один к одному” по набору метаправил.
Корректность работы “нижней” части сдвоенной W-грамматики сомнений не вызывает, если реализация выполнена правильно и с логической точки зрения, и с позиции программной среды.
Вопрос о том, будет ли корректной реализацией “верхняя” половина W-грамматики интересен только с теоретической точки зрения. Здесь мы ограничимся чисто практическими соображениями – это можно сделать, просто ограничивая конкретные реализации правил на том или ином уровне{106. Доказать это не сложно – это конечная индукция на конечном (на каждом шаге) носителе.}.
За дальнейшими подробностями можно обратиться к документации по qWord, так как возможные здесь один - два примера большей ясности не внесут, а места займут достаточно много.
То есть в качестве средства реализации CRR необходимо как и в В*-деревьях взять формальный аппарат W-грамматики. Это будет “специфическая реализация W-грамматики”, как отмечает автор – разработчик qWord. Да, конечно, все это представляется достаточно простым, но только тогда, когда все это уже сделано. Остается, конечно, вопрос адекватности реализации{107. Здесь, наконец, необходимо уточнить употребляемое здесь и выше понятие адекватности. Речь идет об адекватности в самом широком смысле, т.е. всей предметной области вместе с историей ее развития и всей совокупностью задач, которые когда-либо будут решаться. Соответственно, речь идет о “вечно зеленых системах” (системах, существующих только как процесс, а таковы все открытые системы), “адекватная” терминология которых фактически еще не сложилась за невостребованностью до настоящего времени.}, но это уже искусство конструктора – искусство выбора желаемого из многих равноправных альтернатив.
Представляется естественным использовать подход CRR для раскрытия системы и в других направлениях, используя при этом целиком стандартные средства, т.е. механизм “окон” в его стандартизованном в операционной среде виде, идеологию GU – CHU интерфейса и т.д. Хотя это не всегда экономно, но зато обеспечивает открытость продукта в сторону операционной системы и аппаратуры, что немаловажно, пока существует множество их существенно различных реализаций.
8.3.5. Унифицированное представление объекта
Да, речь идет именно об унифицированном представлении объектов, а не об универсальном, поскольку оно может изменять свой вид по мере изменения внешней среды – ПО и ее логических моделей, но никак не претендует на то, что априори содержит все логические модели. В качестве такового представления в qWord предлагается фрейм{108. Фактически, это существенная модификация понятия фрейма по М.Минскому. } - двойственная динамическая структура, которая может быть:
Внешнее, визуальное представление такого фрейма, выполнено в виде комплекта окон со стандартными атрибутами, а также атрибутами, обеспечивающими представление данных в реляционной или иерархической моделях (или их комбинации). Представление по мере надобности может быть изменено или дополнено. Структура хранения фрейма – стандартная, в В*-модели.
Раскрываемость фрейма достигается:
По этой же модели выполнены и представления интерфейсов, и других компонентов системы для тех случаев, когда возникает необходимость работы с ними. За дальнейшими подробностями уместно обратиться к документации по qWord.
8.3.6. Инструментальная концепция – технология qWord
Итак, инструментарий qWord позволяет нам строить СУБД на концепции открытости, концепции динамически раскрываемого объекта, причем выполнить это на базе единого формализма W-грамматик. Более того, и сама БД и все окружение (управление БД) реализованы в единой программной среде и на базе единого представления В*-моделей.
Достаточно логичным представляется и следующий шаг – дополнить комплект объектов, составляющих окружение собственно БД, т.е. фреймов, работающих по умолчанию и обеспечивающих работу БД, базовые (стартовые) логические модели данных, основные интерфейсы и т.п. комплектом инструментальных фреймов. Иначе говоря, снабдить саму систему функционально полным, а точнее – пополняемым комплектом средств самоописания, позволяющим модифицировать существующие и создавать новые компоненты.
Решающим здесь является то, что этот комплект фактически не дополнение, не отдельная подсистема, но неотъемлемая составляющая ядра qWord, доступная для использования из любой точки любого процесса{109. Насколько логично и просто это звучит, настолько же трудным был процесс осмысления инструментальной концепции, в особенности “естественность” его реализации.}. Что до подробностей реализации – то достаточно много полезного материала содержится все в той же документации по qWord. Отметим только, что это не компилятор, qWord породил систему и постоянно сопутствует ей – поддерживает процесс ее существования. Вообще CRR подход требует наличия интерпретатора, иначе получится все тот же объектный подход, неизбежно вытекающий из компиляции. qWord фактически является виртуальной машиной
Теперь обратим внимание – полностью меняется подход к созданию ИС.
На начальном этапе проектируются только логические (внешние) модели ПО, данных и интерфейсов, осуществляется подбор и модификация комплекта фреймов (возможно и из “подходящей” или “похожей” ИС – приложения). Далее, по мере загрузки БД и накопления статистики запросов, при необходимости проводится коррекция моделей данных или создание новых – благо инструмент для этого у нас уже есть. Более того, не только инструмент, но и вся история попыток манипуляции с моделями данных, если, конечно, об этом позаботиться.
Подчеркнем, для полноценной ИС нужна история реструктуризации, т.е. соответствующий фрейм или комплект фреймов, где всю ее можно хранить. Но и этого мало. ИС приобретает уже совершенно новую функцию – функцию активного инструмента для исследования ПО, что может быть полезно не только системщику, но и практическому пользователю. Роль системного аналитика в этом процессе сводится до минимума, точнее даже и не роль, а объем тривиальной с системной точки зрения работы. Он должен:
Характерно, что “сломать” структуру системы{110. Прикладной, конечно, о ядре и речи быть не может.} никакими действиями пользователя просто невозможно, правда можно добиться очень высокой степени ее неэффективности, да и это будет весьма трудно. Здесь мы получаем качественно другой инструмент для работы с информацией и другую технологию не только в разработке, но и в подходе к использованию ИС.
Разумеется, без проблем не бывает. Так при реализации, в особенности интерфейсов, очень мешают противоречивые, иногда и взаимоисключающие соглашения разработчиков программ и аппаратуры, но это проблема вечная. Наряду с привычными проблемами любого “нормального” программного продукта появились и новые, точнее не появились, а превратились, в связи с повышением собственного уровня ИС, из абстрактно-теоретических в самую что ни есть практику. Некоторые из них мы сейчас и рассмотрим.
8.3.7. Куда делась семантика?
При реализации ИС на основе Cache’-технологии с самого начала появилась проблема – в структурах БД остаются только литеры (литералы) и связи (т.е. “чистый синтаксис”), словарь системы также представляется как набор иероглифов и связей их с логической моделью в БД. Правда, к любому понятию можно применить как операцию обобщения, так и операцию декомпозиции – начиная от самой логической модели ПО и до литерала.
Можно применить эти операции в любой комбинации и по всей иерархии сразу, т.е. реализовать динамические связи многие-ко-многим, но после завершения процедуры все равно получится то же самое. Складывается впечатление, что семантика – досужая выдумка теоретиков, а в природе ее и нет вовсе.
На самом деле семантика никуда не пропала, просто адекватно реализованный аппарат “сдвоенной W-грамматики аккуратно и последовательно “разрезает” ее на две части – “константную”, которую укладывает в БД в виде литералов и связей и именует после этого иероглифом словаря, и “плывущую”, переменную, которая “остается в распоряжении” ПО и пользователя. Большая часть народов Земли успешно поступает также – пользуется иероглифами, к которым мы должны относить и всю терминологию профессиональных сленгов. Отсюда следуют два вывода.
Теоретический – семантика суть динамический объект со всеми вытекающими последствиями.
Практический – стоит ли использовать в реализации программных продуктов “функции семантических оценок” и т.п., ибо это не более чем частная статистика{111. Именно частная, сделанная конкретно и на конкретном материале и имеющая весьма косвенное отношение ко всем остальным случаям.}. Прок от нее сомнительный, зато неприятности – гарантированные.
Весьма интересным представляется вопрос о количестве и составе правил W-грамматики, составляющей конструкцию qWord и, в особенности, гиперправил. По умолчанию в qWord в качестве “верхних гиперправил” включены всего два – в терминологии документации D и F гиперфункции. Интуитивно представляется достаточно ясным – этого достаточно для конструирования отображения любой логической модели в структуры данных некоторой Cache’-машины, хотя и не всегда экономно.
Как показала практика создания первых же нетривиальных приложений на qWord, “дополнительные” к D и F функции несут на себе явный отпечаток проблемной области, очевидно являясь связанными с ее спецификой.
Этот интереснейший факт мы используем в следующей части, а здесь ограничимся только упоминанием аналогии, также достаточно очевидной. Напомним, что для конструирования универсальной машины фон Неймана достаточно всего одной логической функции. К тому времени, когда созрел, стал актуальным вопрос о выборе некоторой “оптимальной для вычислений” системы команд пришло понимание ситуации – собственно арифметические вычисления, т.е. решение систем алгебраических уравнений суть очень малая часть задач универсального компьютера. На самом деле необходима машина для обработки данных в гораздо более общем смысле.
Не наводит ли это на мысль – и здесь мы имеем дело с такой же ситуацией, ситуацией дополнительности, несущей в себе, как постепенно выясняется, все больше и больше “системообразующих” черт?
8.3.8. Проблемы саморазвивающихся баз
С появлением первых прикладных продуктов инструментальной технологии появился и соблазн “обучить систему естественному языку человека”, используя тот же инструментарий и технологию. А затраты, и очевидно – немалые, окупятся эффективностью работы приложений. Однако здесь все и кончилось “не начавшись”.
Кроме всего прочего, оказался исключительно важным достаточно неожиданный, но всеобщий факт. Начиная с некоторого и весьма небольшого уровня “полной автоматизированности” и “естественности интерфейса” пользователь перестает думать не только о логике данных, но и о логике ПС, т.е. внешней логической модели и о логике своей собственной работы{112. Это реальный факт, который мы наблюдаем много лет на сотнях пользователей – “хочу одну кнопку”, “если она интеллектуальная – пусть поймет, что я имею ввиду”. И чем выше должностное положение, тем серьезнее это произносится. Особенно резко эффект срабатывает там, где ПО действительно сложна и высока динамика процессов.}.
Получается, что проще и гораздо эффективнее все же заставить пользователя усвоить необходимый минимум системной грамоты для блага его собственного, а наипаче – его деятельности.
Вопрос эффективности лежит во всей основной объектной триаде (ПО – ИС – П), в согласованности ее частей, а не в одном компоненте, например ИС.
Весьма интересным сюжетом разворачивается попытка сделать прикладную систему вместе с qWord (или с любой другой инструментальной системой, обладающей возможностями qWord, если такая найдется) “живой”, способной самостоятельно структурировать данные из входных потоков, а затем и самостоятельно выходить на другие предметные области. Тем более что технология и механизмы qWord эту задачу потенциально способны “поднять”, а механизм саморазвития – “структурный резонанс” нам уже известен [11] и, кроме того, более подробно рассмотрен в части III настоящей книги.
Первые же прикидки дают результат, вполне адекватный размаху постановки:
В этом смысле представляется целесообразным пока вообще не затрагивать в таких случаях понятие интеллекта, но ограничиться исследованиями прикладных систем, помня об особенностях представления в них семантики. В принципе, это можно назвать “неживым интеллектом” информационных систем. Этот термин, вне зависимости от его последующей распространенности, обозначает вполне реальное и важное явление.
8.3.9. Почему “в Cache’-технологии”?
На самом деле первая реализация qWord появилась более двадцати лет назад, но имела с Cache’ общих “прапредков” и “общую среду обитания” – идеи, методологии, средства программной реализации и приложения.
Не праздным представляется вопрос, почему qWord реализуется в Cache’-технологии, а не в какой-либо другой.
Ответ крайне поучительный с практической точки зрения.
Не потому, что в программной реализации Cache’-технологии было нечто, а потому, что не было ничего лишнего! Только один, но тщательно разработанный механизм В*-деревьев и один тип данных – символьная строка, а все до единого ограничения как логические, так и реализационные поставлены явно и однозначно.
Конечно, к этому топору пришлось добавить и искусство и интуицию Конструктора – и варево, наконец, получилось.
Сейчас, когда в основном и теория завершена, и опыт накоплен, мы можем утверждать: все что можно в Cache’-технологии возможно и в других технологиях, но только если Конструктор Системы сумеет преодолеть все капканы и ловушки, построение которых являются неотъемлемой частью более “богатых языков”.
Если у кого-то есть желание преодолевать трудности – преодолевайте. Получится (при успехе такой борьбы) может быть и лучше в каких-то аспектах, а, в общем, то же самое, но очень и очень даже не дешево. Теперь, возвращаясь к первому подходу, можно ответить на вопрос, чем Cache’-технология лучше какой-либо другой для работы с открытыми (т.е. реальными) системами? Вот этим самым отсутствием необходимости преодолевать трудности и лучше. В том числе.
Понятие основной объединенной триады, динамически раскрываемого объекта и сам ход реализации полностью открытых систем типа qWord однозначно ведут к пониманию – системы этого класса по своей сущности мультиобъектные и мультипроцессные, да еще, вдобавок, и с “плавающими иерархиями”. Значит, и строить их надо соответствующими средствами.
“Раскрытие” инструментальной сущности ИС позволяет строить системы, способные “выжить” и успешно функционировать в весьма динамичной проблемной области. Есть смысл распространить этот подход и дальше – в сторону структуры операционных систем и команд. Или еще дальше – в область аппаратных средств, что приведет нас к концепции “Вертикальной машины” (см. гл.14), немного похожей на то, что предлагают “нейрокомпьютерщики”, но существенно отличающейся тем, что ее реально можно построить доступными средствами.
8.4. Третий подход. Специализированная производственная операционная система
В конце 70-х начале 80-х годов на той же основе и “в одной школе” с qWord была начата разработка прикладной системы Текрам [6,7] из разряда “очень больших систем”{114. Разработка основывалась на использовании мало известной тогда ОС MUMPS – предшественницы нынешней Cache’-технологии. С точки зрения реализации это был рискованный, но положительно завершившийся эксперимент – проектирование крупной информационной системы на базе тогда еще не сформировавшейся “теории открытых систем” в условиях формирования самой этой теории в процессе создания системы.}. Это утверждение справедливо, если взять в расчет уникальную динамику предметной области – конструкторско-технологическая подготовка производства крупнейшего предприятия, производящего единичные экземпляры продукции высшего уровня сложности и технологии.
Можно представить себе, как изменяются такие объекты (собственные структуры предприятий и организации работ в них), но технологию самой ИС Текрам менять не потребовалось никогда. Несколько раз сменилась аппаратная база, новые архитектуры (типы) компьютеров подключались даже без остановки системы.
Все это привело к неожиданному эффекту – система оказалась настолько открытой, что без каких-либо усилий всасывала в себя любые CAD-CAM комплексы, что изначально не предусматривалось и, казалось бы, для таких систем “не положено”. Даже одна живучесть и приспособляемость этого подхода должна и сейчас наводить на интересные размышления.
Текрам (рис.8.2) в прикладной постановке был ориентирован на решение задачи обеспечения инженерного варианта интеллектуального управления предприятием, как сложной системой высокого уровня. В соответствии с теорией, прежде всего для поддержки и переработки информационных потоков был выделен стартовый комплекс взаимосвязанных подсистем, практически реализующий собой минимаксный критерий их выбора.
Тем самым были выделены основные потоки информации, подлежащие первоочередному переводу под контроль компьютера с учетом сетевой структуры их взаимодействия (взаимного информационного обеспечения):
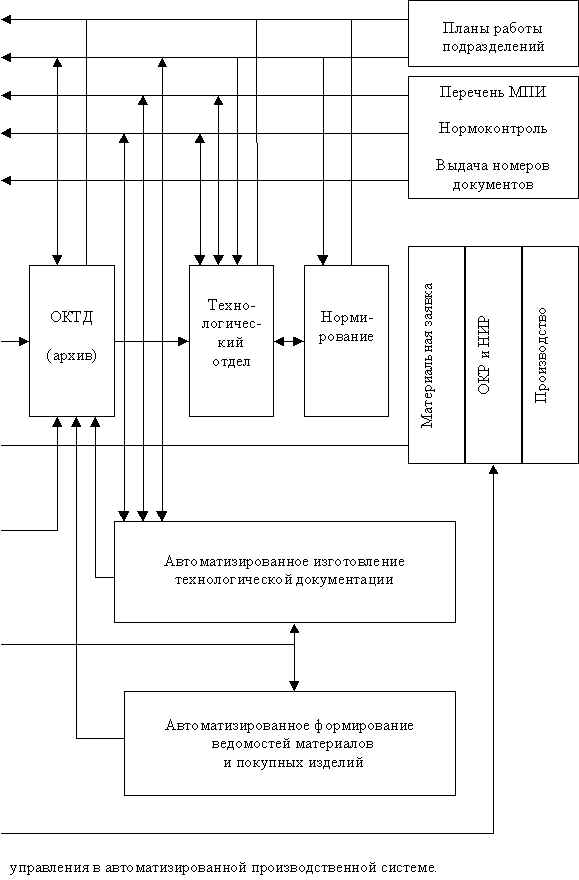
Информационно - вспомогательные документы (в том числе – чертежи) были вынесены во вторую очередь автоматизации. Ясно, что это произошло потому, что организационно - первичная информация (спецификации, технологические маршрутные карты) и производные из нее сведения (вторичные, сводные документы) являются существенно более важными для организации первого этапа комплексной автоматизации работ в открытой системе.
Текрам проектировался адаптивным к любым возможным вариантам конкретной организации взаимодействия рабочих мест комплекса, к изменению их количественного и качественного состава.
Положительный результат мог быть достигнут только при реализации всех необходимых подсистем информационной основы интегрирования в постановке, позволяющей проектировать комплекс инвариантным к конкретной структуре объекта автоматизации.
Как следует из теории, необходимым условием решения этой задачи является такая организация работ, при которой комплексная система не только обеспечивает инструментальную возможность проведения работ, передачу и хранение информации, но и понимает ее, проводит не только синтаксический, но и семантический контроль первого и второго уровня. Только в этом случае объединение подсистем могло быть проведено на уровне обмена “информацией, а не данными”{115. Выражение “обмен информацией, а не данными” много лет использовалось практиками как утверждение о более высокой степени анализа сообщения, сохранении его семантической начинки. Конечно, без сколько-нибудь конструктивного определения информации придумать что-нибудь более вразумительное было просто невозможно. Мы рассматриваем этот вопрос в части III.}.
Соответственно, особое внимание было уделено созданию информационной базы, обеспечивающей отделение информации, необходимой для функционирования подсистем, вырабатываемой в них и подчиняющейся требованиям информационного замыкания от полного информационного потока, подлежащего обработке.
Здесь речь идет об отличении информации о том “как надо было делать и как фактически делается” от информации, образующей поток сведений, ради порождения и преобразования которого и существуют подсистемы автоматизации. Сложность анализа заключается в том, что один и тот же битовый набор в одном контексте используется как ингредиент замкнутой системы, а в другом - как информация в составе обрабатываемого потока.
Принятые проектные решения показали в опытной эксплуатации правильность выбора исходных принципов организации функционирования и общей идеологии построения как самой системы, так и ИСУ. Это позволило разработчикам поставить и решить задачу создания комплекса Текрам как основу для объектов аналогичного уровня и технологического назначения, с возможностями адаптации управления к структуре информационных потоков различных объектов автоматизации.
Особое внимание пришлось обратить на вопросы синхронизации функционирования отдельных подсистем, их операционной поддержки, т.е. на вопросы системного функционирования интегрированного комплекса.
Основным выводом из результатов опытного функционирования разработанного комплекса подсистем, явился вывод о необходимости создания параллельно с набором выделенных подсистем еще и управляющей системы комплексирования, берущей на себя все системные функции, подобно операционной системе компьютера. Можно утверждать, что в известном смысле различие между такими операционными системами минимально.
Здесь уже на инженерном уровне становится очевидным положение теории о том, что, если мы хотим создать действительно управляющую систему, то должны в качестве датчиков использовать подсистемы автоматизации, поставляющие информацию в процессе создания информационно - первичных документов, а в качестве исполнительных механизмов - подсистемы, влияющие на объемы и динамику информационных потоков объекта управления.
Итак, опыт разработчиков, накопленный при техническом проектировании и эксплуатации комплекса, свидетельствовал о необходимости выделения операционной основы комплексной автоматизации в самостоятельный объект. На этапе рабочего проектирования такая основа была создана и получила название Специализированной Распределенной Производственной Операционной Системы (СРПОС) для комплекса Текрам.
Основная версия Текрам обеспечивала функционально полную автоматизацию ряда работ с выполнением их пользователями в режиме безбумажной технологии на удаленных рабочих местах:
Спроектированная СРПОС выполняла целый ряд функций, которые можно разделить на функции организации ведения собственно работ и информационной базы на рабочих местах пользователей Текрам (т.н. внешние функции) и функции поддержки работоспособности самого комплекса (т.н. внутренние функции).
СРПОС была реализована таким образом, чтобы внешние функции выполнялись с участием пользователей с применением различных форм диалога (человек включен в состав подсистем как необходимый исполнительный элемент), а внутренние функции выполнялись с минимальным участием пользователей, вплоть до автоматического функционирования системы в пределах сгенерированной конфигурации технических средств и требуемых возможностей при условии обеспечения управляемости всех процедур от программного администратора Текрама (человек исключен из управления – фактический “управитель” план и портфель заказов).
К внешним функциям СРПОС было отнесено обеспечение функционирования рабочих мест Текрама, предоставление средств создания новых подсистем автоматизации. В СРПОС предусматривалась возможность создания новых или изменения назначения сгенерированных ранее рабочих мест, что обеспечивало высокую адаптивность и расширяемость Текрама.
Для организации взаимодействия пользователя с разработанной системой интегрированной автоматизации была выработана концепция, согласно которой набор разрешенных синтаксических и семантических конструкций входных языков пользователей формируется на основе подробного анализа их профессионального тезауруса. Учитывая тот факт, что указанный тезаурус не является стабильным множеством дескрипторов, были предусмотрены и средства расширения пользовательских языков СРПОС.
Описываемая система была снабжена средствами, позволяющими осуществить расширение ее возможностей как при участии разработчиков, так и силами пользователей. Расширения функций СРПОС обеспечивалось за счет встраивания механизма создания, ведения и выполнения программ (текстовых сообщений) пользователей на входных языках системы, что позволяло пользователям, не являющимся профессиональными программистами, создавать подсистемы автоматизации своей деятельности.
Для ведения диалога в состав СРПОС был включен универсальный интерпретатор входных языков пользователей, который использовал расширяемый набор таблиц дескрипторов. Каждая таблица интерпретатора содержала определенный набор дескрипторов, описывающих в своей совокупности профессиональный тезаурус разработчиков заданных документов, классификаторов, словарей или иных подмножеств данных. Предусматривались средства расширения набора таблиц интерпретатора и дескрипторов.
Используя дескрипторы входных языков, пользователи могли вести диалог в командном и программном режимах. Командный режим обеспечивал ввод и немедленное исполнение введенных команд языка с одновременной проверкой синтаксиса и семантики. Программный режим позволял описать повторяющиеся проектировочные процедуры в виде программы специального вида, хранить эти программы в БД и исполнять их по запросам. Проектировочные программы подразделялись на рабочие и библиотечные:
Как отмечалось выше, функции всех рабочих мест были реализованы с применением единого универсального интерпретатора входных языков пользователей. Такая универсальность обеспечивалась благодаря наличию программного механизма трехуровневой настройки ядра СРПОС.
На этапе генерации системы при установлении взаимосвязей всех подсистем выполнялась статическая настройка.
Индивидуальная настройка выполнялась на этапе регистрации указанного пользователем рабочего места путем выбора разрешенного состояния ядра.
Наконец, динамическая настройка выполнялась в процессе работы пользователя при выполнении инициирующих действий, таких как изменение режимов работы, переход к работе с новым документом и др.
Ясно, что таким образом поддерживалась на организационном уровне эффективная настройка комплекса на необходимое сочетание терминальных средств и видов работ.
Новые подсистемы, разрабатываемые в составе СРПОС, автоматически интегрировались с имеющимися программными комплексами. Эта возможность обеспечивалась, в том числе и тем, что информационное взаимодействие подсистем в СРПОС достигалось не за счет общепринятых программ обмена данными, входящими в состав программных комплексов, а за счет программного обеспечения ядра системы, которое остается неизменным при подключении к комплексу любых новых подсистем.
Внутренние функции СРПОС можно представить в виде основных классов задач:
Подчеркнем, что как прообраз системы с ИСУ, Текрам отнюдь не был ориентирован на решение полной задачи автоматического управления. Тем не менее, на его основе были получены (как бы “автоматически”, просто за счет соблюдения “незамыкаемости” его подсистем) все необходимые решения для создания ИСУ объектами класса “общественного института”.
Опыт эксплуатации Текрам показал правильность сформулированных выше положений прикладной теории ИСУ. Можно утверждать, что архитектура организации информационных потоков, предлагаемая прикладной теорией ИСУ позволяет системе находится в постоянной готовности к восприятию любых нововведений, обусловленных текущими потребностями объекта автоматизации или внешними относительно него организационно - распорядительными актами.
Текрам существовал как система, подлинного объема которой не мог оценить ни один пользователь. Для каждого из них он представлялся лишь технологическим изменением повседневной организации работ – вчера пишем на бумаге, сегодня на экране и только то, что является новым, рамки компьютер и сам рисовать умеет. Аналогично - “вчера ничего не делал и этого никто не заметил – сегодня компьютер учел мое реальное, а не высиженное рабочее время с немыслимой точностью”. Все такие психологические проблемы требовали решения и постепенно решались. Был преодолен критический стартовый порог начального объема необходимой информации – Текрам находился в рабочей эксплуатации.
“Смертельным” обстоятельством для Текрама стала его остановка по обстоятельствам “перестроечного характера”. Системы такого уровня останавливать “в получении информационного обеспечения работ из внешнего мира невозможно” – они незамедлительно заканчивают цикл своего существования.
В заключение “повести о Текраме”, среди множества его особенностей отметим еще одну – уникальную, как выяснилось в процессе эксплуатации, приспособляемость к изменениям проблемной среды, способность к самосовершенствованию{116. Как показал опыт, приспособиться нельзя только при прекращении потребности в системе (при прекращении процесса информационного обмена), так как это произошло с Текрамом при перестройке – не смена экономической формации страшна, а развал экономики. И это равно плохо для всех интеллектуальных систем всех уровней, и даже для таких, как Текрам, только приближающихся к интеллектуальности.}. Но сделаем это уже применительно к обобщенному понятию ИСУ, просто используя опыт эксперимента по созданию системы Текрам.
8.5. Самосовершенствование ИСУ
Для обеспечения постоянного совершенствования ИСУ, которое в прикладной теории ИСУ понимается как проблема направленного изменения внутренней структуры системы, необходимо предусмотреть наличие некоторого специального аппарата. Учитывая тот факт, что наше понимание ИСУ предполагает ее организацию как автоматической, а не автоматизированной системы, единственным приемлемым вариантом здесь может явиться создание некоторого программного испытательного стенда, дополняющего собой стенд, рассмотренный в разделе 7.3.
Представляется необходимым для ИСУ, пользуясь упомянутыми выше свойствами организации объекта, разработать систему имитаторов (демонов), управляемых по темпу и объему порождаемой информации от некоторых независимых генераторов, имитирующих собой различные режимы функционирования рабочих мест. Высокая степень организации системы, обладающей интеллектуальными функциями, позволяет построить демонов, генерирующих синтаксически достоверную и семантически правдоподобную информацию.
Таким образом, мы приходим к постановке переборной задачи, имеющей на входе всевозможные сочетания темпов поступления и семантического содержания информации от достаточно произвольного числа демонов, а на выходе - зоны устойчивости, оцениваемые по минимуму изменения динамики информационных потоков внутри объекта. В известной степени эти зоны эквивалентны рассмотренному выше понятию гомеокинетического плато.
Решение указанной задачи может быть возможно только полным, или, в лучшем случае, направленным перебором. Нашим преимуществом, дающим надежду на успех, является временное масштабирование, позволяющее моделировать полностью предполагаемые изменения входных величин, т.е. заниматься исследованиями информационно-динамических свойств объекта.
Реализация таких демонов вместе с изменяющим характер их деятельности генератором является реальной задачей и может быть выполнена следующим образом.
Стандартная и автоматически поддерживаемая структура программного обеспечения рабочего места требует явного выделения программ для реализации обмена информацией с пользователем и программ обработки информации. В случае функционирования системы в реальном окружении запуск программного комплекса обслуживания рабочего места инициируется действиями пользователя, а программы обмена информацией настраиваются на терминальный ввод - вывод. Имитация активности пользователя - демона возможна путем запуска в фоновом режиме программного комплекса с измененными программами обмена информацией. Таким образом, пользователь – демон с точки зрения компьютера и операционной системы является не отдельной активной задачей, а всего лишь набором программ.
Унифицированное построение обрабатывающих подпрограмм рабочего места, например, на базе таблиц интерпретации команд, позволит строить демонов практически с той же степенью унификации. Имея доступ к системным таблицам, демоны могут быть избавлены от необходимости генерировать входную информацию на уровне случайных последовательностей символов, создавая случайным образом сразу целые команды или даже группы команд. Чем выше сложность программного обеспечения рабочего места, тем проще может быть устроен соответствующий демон при сохранении уровня правдоподобия результирующей информации.
Моделирование течения времени требует, чтобы демоны перед запуском получали задание на разработку некоторого количества документов, а после его выполнения сообщали об этом факте и освобождали машину. При этом самим демонам не требуется оперировать понятием продолжительности и темпа работы, это за них делает единственный центральный супердемон - распределитель работ и синхронизатор времени. Задаваясь некоторым временным интервалом и набором темпов для различных видов работ, супердемон активизирует демонов, указывает им требуемые объемы работ и считает очередной временной интервал завершенным, когда закончены работы всех подчиненных ему исполнителей.
Такая организация работ позволяет максимально уплотнить внутреннее время системы, получить хорошо управляемый ансамбль демонов и выделить моменты, в которых наиболее удобно производить оценку информации. Алгоритм функционирования супердемона может быть задан в различных формах в зависимости от того, требуется ли однократная оценка конкретного варианта соотношения параметров внешнего мира или решения поисковой задачи в некоторой области изменения параметров с заданными вероятностями распределения внутри области.
Вообще говоря, нет никаких ограничений на совместную работу в рамках одной информационной системы как реальных исполнителей, так и демонов, создающих смешанную реально - модельную среду существования системы комплексной автоматизации. Демон специального вида может обеспечить синхронизацию работы всего ансамбля с течением физического времени, хотя это и не является абсолютно необходимым для совместной работы.
Результатом такого симбиоза является прогнозирование состояния системы в соответствии с предполагаемым планом работ, перераспределение загрузки рабочих мест и множество других превентивных решений, составляющих сущность управления, показ собственных интеллектуальных возможностей автоматической системы и изучение роста этих возможностей по мере ее развития.
Ясно, что можно и нужно использовать механизм организации демонов и для проведения других исследований по совершенствованию системы. Например, можно рассмотреть вопрос о поиске причин наиболее часто встречающихся ошибок, об анализе входной или выходной информации рабочих мест и ее влияния на вид функции расстановки и многое другое. Основным направлением исследований здесь должен быть поиск возможностей получения заранее непрогнозируемых сообщений о возможностях, состоянии и перспективах работы системы{117. Приблизительно такой же подход, но для управления “кибернетического уровня с интеллектуализацией”, был выдвинут в 1986 году в Иллинойском университете (США) для создания прогностических систем управления АЭС. Кибернетический уровень прогнозирования требовал задания экспертного знания и исключительно больших вычислительных мощностей, что естественно для объекта с непрерывным технологическим циклом.// //В нашем случае, мы имеем “системное удобство” взаимного обеспечения рабочих мест информацией и “организационное удобство” периодической свободы вычислительных мощностей в социальной системе, живущей в ритме своей системообразующей частицы (человека). Эти факторы дают нам возможность обходиться реально необходимыми для технологического процесса мощностями, не привлекая дополнительных ресурсов.}.
Остается еще раз отметить здесь замечательный факт, наблюдавшийся и экспериментально, в реальной функционирующей системе – для функционирования механизма саморазвития{118. Задача “саморазвития” изначально не ставилась. Возможность ее постановки и решения выяснилась “по ходу дела”, просто системный охват источников и потоков информации предоставил эти и другие аналогичные (системные) возможности.} системы решающей оказывается динамика потоков информации.
Завершая этот краткий обзор реальных прикладных систем обладающих некоторой “интеллектуальностью”, отметим их свойства, наиболее важные для дальнейшего изложения.
| Site of Information
Technologies Designed by inftech@webservis.ru. |
|