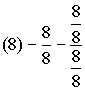Глава 11. Собственная структура информации
11.1. Проблемы разработки
инструментария
11.2. Топология вложенных многомерных
конусов
11.3. Закон рекурсии структур,
метаструктур и процессов
11.4. К вопросу об элементарной ячейке
11.5. Некоторые количественные оценки
элементной базы
Глава 11. Собственная структура информации
Инструмент должен соответствовать технологии изготовления, его точность не может быть ниже требований процесса. Так что же нам нужно для адекватного исследования открытых систем и их атрибута – интеллекта?
Искать и исследовать собственную структуру информации, внутреннее устройство ее как самостоятельной сущности, можно только при восприятии совокупности взаимодействующих информационных процессов, при рассмотрении работы некоторой “информационной машины”. Значит, нам придется попутно построить и саму эту машину. Но мы не имеем права “выдумать” это устройство, необходимо найти ту “схему”, ту “элементную базу” и систему команд, которую уже изобрела Природа. Иначе речь не может идти о Природном явлении, Природной аксиоматике и открытых системах.
При этом совсем не надо подробно и в деталях исследовать устройство и работу нейронов, наоборот, исключительно важно сосредоточиться только на ключевых моментах, на минимуме тех свойств “элементной базы”, которые обеспечивают представление некоторых универсальных сущностей – структур, достаточных для существования и воспроизведения любого информационного процесса. Задача определения того, что такое эти “минимально-достаточные” структуры, является важнейшим аспектом нашего поиска.
11.1. Проблемы разработки инструментария
Первичной проблемой всех разработок, связанных с сигнальным подходом к обработке информации всегда было “разрешение” технической элементной базы, количество уровней квантования, причем как для восприятия внешних сигналов, так и для внутреннего представления информации.
Известно, что возможности аналогового представления ограничены тепловыми шумами на уровне 12-14 бит. В цифровом представлении инженерная практика уже достигла 128 битового представления и технически можно получить больше, но как этими возможностями распорядиться?
К настоящему времени проблемой для разработчиков микропроцессоров стала целесообразность дальнейшего увеличения разрядных сеток. Представляется, что дальнейшее “раздувание изнутри” архитектур компьютеров (т.е. фактически модификация машины фон Неймана) создает не меньше проблем, чем позволяет разрешить.
Возникает вопрос – можно и нужно ли строить механизм, “измеряющий” то, что существенно мельче деления “природной” шкалы? Речь идет о том, а “сколько же действительно надо” Природе, в аналоговом или цифровом виде она работает, и как соотносятся разрешающая способность элементной базы и “соотношение неопределенности-2”
Аналогичные вопросы полезно изначально обсудить и для понятия количественной оценки и “упаковки” информации, и для оценки ее помехозащищенности. Здесь мы не пытаемся дать исчерпывающего ответа на эти вопросы. Пока наша задача – первичный анализ ситуации и выработка разумных предположений, оценка технических перспектив на базе имеющейся Природной данности, т.е. оценка “технических характеристик” нейронов и подходов к осознанию механизмов их функционирования, как механизмов, на основе которых построена Природная “информационная машина”.
Начнем с достаточно известного факта из экспериментальной нейрофизиологии. Установлено, что “языковая зона” занимает в коре головного мозга строго определенный участок – 50-60 тыс. нейронов объемом около 0,25 см3. При работе активизируется вся эта зона сразу, как у индивидуума, владеющего самым примитивным языком, так и у полиглота с несколькими десятками языков (включая все тонкости индокитайской фонетики, японской каллиграфии и проч.). Тут уже даже по количественным характеристикам (вспомним размер звуковых файлов) уместно уподобить нейрон чему-нибудь посерьезней рабочей станции, а аксон – сверхуплотненному мультиплексору{157. Те, кто возятся с “моделями” нейронов из нескольких сотен (да пусть и более) транзисторов или “моделируют” его в персональном компьютере, не напоминают ли детишек, привязывающих кусок проволоки к вилке велосипеда “чтобы трещало как мотор”? Конечно, самолет можно смоделировать бумажным голубем, но вот что дальше?}.
Далее отметим, что “двухполушарная спецификация”, характерная для элементной базы мозга (т.е. некоторая изначальная ее структурность, по какой-то причине обязательная для работы с информацией) обычно рассматривается как одна из главных причин или обязательных условий существования “информационной машины” или интеллекта (как механизм его возникновения). Из инженерных соображений это вполне очевидно – см. часть I.
Теперь о способе “упаковки” информации. Наиболее информационно-емкий механизм, известный на сегодняшний день – интерферирующие волновые фронты. Они могут переносить и зрительную и слуховую информацию, тот же механизм лежит и в основе голографической памяти. Допустим, что именно они воспринимаются и кодируются, как это и принято иногда считать, в виде электрических импульсов, причем наиболее эффективным “матричным” способом упаковки.
Но, если взять максимальную полосу пропускания нервных волокон, их число, например, в слуховом нерве и предположить, что производится многократная упаковка первичного сигнала, то и тогда получится… Вернее сказать, ничего не получится, не хватает ширины канала. “Электрическая гипотеза” явно не отвечает реальности.
Скорее всего, все наблюдаемые импульсы в нейронах – всего лишь повозки, способ упаковки, а химическая активность – “кучи грязи, да туча пыли на дороге”. Следы это лишь от интеллектуального процесса. Возражение типа того, что у “неинтеллектуальных” кошек и лягушек все так же сделано – не аргумент. То ли там повозки пустыми гоняют, то ли “пассажиров” отправляют прямо в отвал и они ни в какие картины, мелодии и прочие продукты интеллекта не переходят (скорее второе) – к способу упаковки этих самых пассажиров все это отношения не имеет.
Альтернативой может служить предположение, что и передается и обрабатывается нервными волокнами и нейронами непосредственно сам волновой фронт, но не напрямую, как по оптическому волокну, а по цепочке ретрансляторов, от одной группы молекул к следующей и так далее – почти как зарядовый пакет в ПЗС-линейке. Форма же соответствующего ему электрического импульса, наблюдаемая на осциллографе – это всего лишь “последствия”.
Во всяком случае, в элементной базе обеспечена реакция на структурно-сложные объекты практически того же порядка, что и скорость прохождения импульсов – тут уже никакие ссылки на распараллеливание обработки в коре и подкорке не проходят. К тому же обрабатываемые объекты обычно структурно так устроены, что плохо подлежат распараллеливанию по своей природе.
В пользу альтернативной гипотезы есть и еще один факт. Известно, что в экстремальных условиях (при актах смерти и деления) клетка срабатывает как “биологический лазер”. Естественно предположить, что нервные клетки (какие-то структуры внутри волокон) обладают сходным свойством в нормальном состоянии, т.е. способны периодически генерировать электромагнитный волновой фронт (кстати, зная назначение этих структур легче их найти). Механизм питания таких “лазеров” явно электрохимический, отсюда и весьма низкая скорость прохождения импульса по волокну – цепочке ретрансляторов, что и наблюдается в нейрофизиологических экспериментах (время прохождения сигнала от периферии до центральной нервной системы порядка 10-4 сек.).
Все вполне согласуется – на каждой ступени (периферическая, стволовая нервная система, подкорка) затрачивается время на подзарядку механизма накачки лазеров, но, с другой стороны, обработка образа в коре и выработка реакции на него, включающая, возможно, миллиарды ступеней преобразования, выполняется за время, явно не выходящее за порядок 10-4 сек{158. Вспомните широко известные опыты типа “человек-компьютер”, характеризующие потенциально возможную скорость вычислений, производимых человеком.}. И вообще как-то сомнительно, чтобы Творец, придумав “внутриклеточный лазер”, потом его никак не использовал (вроде как больше и ни за чем такой лазер не нужен – на Инженера это не похоже).
В дополнение к выше сказанному рассмотрим интересный экспериментальный факт. Попробуйте на расстоянии метра от работающего компьютера заняться электросваркой – сеанс работы ПК наверняка будет испорчен из-за сбоев, вызванных электромагнитными помехами. Но с мозгом человека ничего худого не случится.
Сравним напряженности возникающих электрических полей, причем только их статическую компоненту:
При собственном потенциале, равном или превышающем уровень помехи, ПЗС почти гарантировано обеспечивают отказ аппаратуры. Но при потенциале помехи в тысячу раз большем аксонного, ничего плохого в нейроне вроде бы не происходит.
Забудем о том, что основная помеха динамическая, что микросхемы многократно экранированы, а нейрон просто “плавает в воде”, но и тогда уровень помехозащищенности “элементной базы мозга” относительно ПЗС может быть оценен величиной порядка 104. На самом деле, из понятных соображений, он должен быть выше на порядки.
Такой уровень помехозащищенности может обеспечить только один вариант реализации – механизм функционирования нейрона “спрятан” на квантовомеханический уровень. Остается только замереть в удивлении оттого, что кто-то еще всерьез рассуждает об “электрической” природе этого механизма. Если и это неубедительно, предлагаем вспомнить еще одну серию “экспериментов”.
При самых страшных лучевых (радиационных) поражениях, функции нервной системы, а в особенности центральной нервной системы, сохраняются дольше всего, до тех пор, пока не наступает соматическое разрушение нейронов, т.е. разрушение “самой аппаратуры”. Электронные же схемы и данные в них разрушаются полностью при интенсивностях и дозах облучения в десятки, а то и сотни раз меньших.
Следует упомянуть и о том, что квантово-механическая природа механизма нейрона не придумана нами “к случаю”, но уже достаточно давно является предметом тончайших комплексных биофизических исследований{159. Сошлемся, к примеру, на известную с 1987 года теорию “тубулированного скелета нейрона”, разработанную под руководством С.Хамероффа и использованную в качестве одной из базовых гипотез Р.Пенроузом: Stuart Hameroff, Ultimate Computing: Biomolecular Consciousness and NanoTechnology, 1987.}. Поэтому мы намеренно обращаем внимание только на общеизвестные факты и распространенные оценки, исходя из следующих соображений:
И, наконец, укажем, что, в отличие от чисто технических систем, априорная оценка “эквивалентной разрядной сетки”, “эквивалентного машинного слова” не может служить здесь отправным пунктом исследования. Вполне можно предположить (и ниже мы это покажем), что такого рода характеристика суть величина индивидуальная не только для каждого отдельного экземпляра, организма, но и для каждой решаемой задачи, а соотношение неопределенности-2 является ориентиром переменной оценки “реальных потребительских характеристик элементной базы”.
Получается, что ответ на поставленные в начале раздела вопросы надо искать в переходе к аппаратам структурным и квантово-механическим, учитывающим изменения самой структуры информации в процессе ее взаимодействия с воспринимающим ее механизмом. Начинать надо с феноменологического подхода к информации, с перехода от исследования сигнальных обрабатывающих механизмов к поиску законов обработки информации на базе восприятия ее собственных структур, метаструктур и их иерархии.
Все “интуитивно” найденное и положенное нами в основу технической реализации интеллектуальных систем в части I настоящей книги – пока не более чем весьма упрощенное “переоткрытие” фундаментальных решений Природы, “инженерная увертюра” к исследованию, ведущему к созданию науки информодинамики.
11.2. Топология вложенных многомерных конусов
Начнем с краткой предыстории, с публикации [26]{161. Чисто инженерное понимание интеллектуальной системы в теории ИСУ внешне предусматривает ориентацию исключительно на уровень вербально - понятийного обобщения информации, то есть на уровень, хотя и учитывающий контекстную природу информационных потоков, но все же ограничивающий анализ семантики и первого и второго порядка возможностями “алгебры изменяющихся формально-логических отношений”. Поэтому, во избежание критических замечаний об одностороннем понимании интеллекта в теории ИСУ, для случая, когда речь идет об интеллекте гуманоида, мы ссылаемся на [26], где в интересующем нас ключе рассматривались вопросы, связанные с пониманием интеллекта как совокупности сознательного, подсознательного и бессознательного аспектов переработки информации.// // Действительно, интеллект в “гуманоидной” трактовке может включать в себя такие не вполне определимые понятия как ощущение, восприятие, представление, разум, мышление, рассудок и другие, вроде бы дополняющие субъектно-объектную познавательную активность через “накопленный образ”. Или этот самый “образ” только и возможен, если он включает в себя “независимо от нашего желания” все перечисленные понятия?// // В литературе можно встретить разнообразные теории, связанные с определениями интеллекта, пытающимися учесть понятия такого рода. Сравнительный анализ их исходных посылок показывает, что в контексте наших интересов, связанных с поиском следующего шага анализа интеллекта как атрибута сложной системы, перспективным является расширение инженерных построений за счет использования определения интеллекта как совокупности индивидных и межиндивидных связей, коррелированных с тремя основными характеристиками - компонентами: биологическое (бессознательное), психологическое (подсознательное) и социальное (сознательное), причем возможно с необходимостью выделения соответствующих гендерных доминант. Однако можно предположить, что все это тоже подчиняется, вернее, обеспечивает изменение все того же “изменяющегося формально-логического аппарата”.}. Эта работа подводила, в некотором смысле, итог многочисленным исследованиям, использующим “экзотические” модели феномена интеллекта, точнее некоторых аспектов его функционирования. В качестве инструмента моделирования в работе было взято известное цветовое тело, представляющее собой пару сложенных основаниями конусов, внутри которых располагаются некоторые парные представления (сознание-подсознание и др.). Соответствие между этими представлениями устанавливалось через отражение в “зеркале” - поверхности (гиперплоскости), разделяющей конусы. Само же зеркало имело топологию цветового круга, т.е. структуру “подобную видимому спектру”.
Во избежание возможной путаницы и подмены понятий отметим – не потому интеллект моделируется цветовым телом, что человек видит и эмоционально воспринимает множество цветов, но видимый спектр (впрочем, как и “слышимый”) есть следствие действия общего принципа, на базе которого интеллект устроен. То есть, в основе явления явно лежит гармоническая шкала как один из основных системообразующих механизмов.
Тот факт, что “видимый спектр” расположен именно в таком частотном диапазоне – следствие резонанса частотных характеристик материалов, из которых построен человек и среда его обитания. Выбор же именно этого частотного диапазона для “моделирования интеллекта” естественным образом предопределялся “максимальной полосой пропускания информации” носителя этого интеллекта.
Как мы уже знаем, законы гармонических шкал являются системообразующими не только для “интеллекта”, но и для более первоосновного феномена - самоорганизации.
То же самое можно утверждать и в отношении комплементарного представления объекта в “двухконусной топологии с зеркалом посередине”. Коль скоро удастся показать, что подобный механизм срабатывает при очень разных исходных посылках и на самом различном материале, то будет естественно предположить, что имеет место действие некоторого феномена, заключенного не в исследованиях, но в самом предмете.
Обратим внимание еще раз на механизм, основанный на двухконусной топологии, но уже с другой, инструментально-топологической стороны.
Известно, что в недавнем прошлом (по исторической шкале) человек воспринимал окружающий мир в обратной перспективе. Можно считать достаточно хорошо доказанным, что такое восприятие было “выдавлено” по мере “математизации сознания” парадигмой “правильной”, т.е. математической перспективы.
Но мы здесь утверждаем, что “выдавлено” не наружу, а внутрь, на уровень “скрытых утилит” (скажем не в подсознание, а в некий промежуточный уровень или “общую операционную среду”).
Представим теперь себе механизм, в каком-то смысле совмещающий в себе указанные подходы к восприятию. Одна его часть (прогнозирующая, конструктивная) строит “конус достижимости” в будущее, и не из точки t0, а из некоторой t0 - ?t1 (надо же иметь какой-то фактический материал для построения). Другая часть строит такой же конус, но из точки t0 + ?t2 в обратном направлении – “аналитический конус”. Точнее это даже не конусы, а каркасы систем вложенных конусов.
Обратим внимание на следующий момент. Если взять все семейство вложенных конусов, которое удалось построить, и в них отметить те конуса, которые имеют отношение к управляемым координатам и ограничениям, то выделенное подмножество окажется ни чем иным как конусом достижимости Болтянского{162. Здесь мы имеем в виду буквально “чистую механику” работы с данными. Представим каждую координату в виде структуры данных Cache-системы, т.е. в виде В*-дерева (см. часть II). Совокупность В*-деревьев по всем наблюдаемым координатам организованная как супердерево, представляет собой “доступное наблюдению пространство”. В нем можно выделить (отметить) поддерево, листьями которого являются фазовые координаты системы, т.е. представление той части системы, которая подчиняется управлению.// //В этой структуре, в свою очередь, можно выделить поддерево, удовлетворяющее ограничениям на управление. Заметим теперь, что из соображений балансировки В*-деревьев, оптимизации использования аппаратуры (есть и другие причины) в системе присутствует многоуровневый (как минимум двухуровневый) кэш (перемешивание) данных. Последнее выделенное нами дерево приобретает топологию конуса, но само это дерево и есть запись, отображение в структурах данных конуса достижимости системы, определяемого по классической теории управления.// //Получается, что мы копируем буквально, один к одному и топологию процесса управления – каждой траектории системы будет соответствовать траектория “навигации в структуре данных” и наоборот. Однако отметим крайне важный и не столь очевидный факт -–только топология и только на уровне целое-к-целому. Т.е. расширению (или сужению) конуса достижимости будет соответствовать свой конус представлений, но говорить о соотнесении метрик или даже наведении какой-то “псевдометрики” в представлениях вообще недопустимо!// //Но и никакой особой сложности, скрытого смысла здесь нет. Траектория в фазовом пространстве – ясно, что это такое просто по определению. Траектория в конусе представления – это трасса алгоритма, создающего (и, в общем случае, изменяющего) обратную связь (функционал главной обратной связи), обеспечивающую соответствующую траекторию в фазовом пространстве. Говорить о какой-то общности или соотношении метрик этих пространств просто нелепо. И тем замечательнее факт абсолютного топологического подобия представлений.}.
Очевидно, что некоторые из одноименных линий будут пересекаться (т.е. скрещиваться в некотором объеме, определяемом квантовым соотношением неопределенности) – это пересечение 1.
Другие линии будут скрещиваться в большем объеме, определяемом соотношением неопределенности-2, т.е. неразличимостью на уровне модели из-за ограничений представления или “угла зрения”. Это, соответственно, пересечение 2.
Совокупность этих пересечений – не гиперплоскость, а скорее некоторая достаточно пухлая лепешка – и есть та “истинная метрическая сетка” в которой функционирует механизм в целом на отрезке deltat3, deltat3<<deltat1, deltat3<<deltat2. {163. Если читатель сочтет, что это будет полезно, то можно дать “грубо физический” пример конусной топологии. Представим себе некоторую удаленную от нас плоскость или лучше объем пространства (диапазон резкости), на котором мы фокусируем свой взгляд и в который мы можем попасть, вообще говоря, только в момент t0+deltat2. Это аналитический конус. С другой стороны, смысловую интерпретацию этого объема пространства мы вообще можем дать только исходя из накопленного опыта, имеющейся a priori информации, текущих соглашений и ограничений на восприятие информации и тому подобного, т.е. исходя из смысловых и ситуационных оценок, возможных контекстов и т.п., сделанных (накопленных) в момент t0-deltat1. Это конус достижимости – все, что мы можем понять и воспринять в этом “пространственном срезе” существующем на отрезке deltat3.}
Таким образом, мы имеем процесс “измерения своего состояния” как бы в двух перспективах – прямой и обратной. А теперь посмотрим, как в эту топологию замечательно укладывается архитектура интеллектуальной базы, предложенная в части I.
Предположим, что интеллектуальная система строит в своей базе сразу две структуры (параллельно во времени и пространстве памяти) – “прогностическое дерево”, т.е. то, “как представляет (мыслит) себе свое положение в обстановке” и второе “аналитическое дерево”, т.е. то, “как видит” (реально воспринимает). В некоторый момент времени вся актуальная воспринимаемая информация будет исчерпана и процесс остановится.
Набор совпадающих одноименных листьев этих деревьев и есть описание состояния системы на этот момент, которое она вынуждена принять как “истинное”, так как это максимум того, что можно извлечь из “текущего опыта” и “предыдущего знания”. Таким образом, то “поле памяти”, в котором расположен указанный набор листьев и есть “зеркало”, точнее его мгновенное (“замороженное”) состояние. Мы получили уже понятную нам топологию “конуса с зеркалом”, но с одним очень существенным дополнением.
Реально статики конусов не бывает (она только здесь, в описании или “мысленном эксперименте”) – система существенно динамическая. Даже если в “воспринимаемой картинке” ничего не меняется, то система может “шевелить” прогностическое дерево (“качать” половинку конуса), например, с целью поиска “лучшего варианта” или “рассматривания подробностей”{164. Ниже мы придем неизбежно к выводу: не “может”, а только этим и занимается, поскольку сам процесс поиска и есть первопричина существования системы – любой!}.
Топология конусов позволяет человеку (субъекту в процессе субъектно-объектного общения) до некоторой степени видеть будущее, как водитель видит (представляет с учетом всех ему известных факторов) дорожную обстановку, в которой он будет.
В “физическом” прогнозировании многое связано с различными скоростями перемещения масс, сигналов, дальнобойностью и разрешением сенсоров. Однако следует заметить, что и чисто информационных координат (компонентов) состояния все это касается в той же или большей мере. Так, например, скорость езды (в ближайшем “будущем”) может ограничиваться не только возможностями автомобиля, но и знаком “ограничение скорости” и знанием типа “за поворотом яма”.
Отметим, что на всех уровнях: чисто абстрактной самоидентификации (цветовой конус), сенсорной самоидентификации (перспективный конус, т.е. пара конусов прямой и обратной перспективы), представления в базе данных (встречные конечные деревья) и на уровне элементной базы (волновые фронты в нервных волокнах и нейронах) действует, похоже, один и тот же механизм.
Здесь мы обращаем внимание читателя на следующее обстоятельство – мы ничего не конструировали, даже реконструкцией это назвать нельзя, мы просто проследили как на всех уровнях представления информации и в самых разных по природе системах проявляется единая топология организации данных, и не только данных, но и процессов их обработки.
Действительно, посмотрим еще раз.
Напомним, что именно механизм В*-деревьев, минимальный из известных, достаточен для представления любых (произвольных в самом общем смысле) данных. Очень похоже, что Творец (Природа, если хотите) ничего “лишнего” не создавал, но пользовался одним единственным универсальным и минимально-достаточным представлением.
Но при этом речь идет только о представлении, о топологии данных, какую-либо “скрытую семантику” надо полностью исключить.
“Априорная семантика” присутствует лишь в “собственно данных”, т.е. в значениях первичных сигналов и в “словаре”, в наборе терминалов, которые “стали константами, обеспечивающими жизнеспособность системы”.
“Семантика как таковая”, т.е. метрика и как способ измерения, и как набор масштабов и коэффициентов, появляется только в процессе интерпретации, в процессе взаимодействия потоков данных “от среды” и “от системы”.
11.3. Закон рекурсии структур, метаструктур и процессов
Можно достаточно обоснованно предположить, что в основе рассмотренных выше архитектур лежит принцип структурной рекурсии – использование на всех уровнях одной и той же самоподобной структуры.
Но если на сенсомоторном уровне (в силу естественной причины – первого или второго соотношения неопределенности) происходит обмен рекурсии на рекурренцию, то на информационном уровне все происходит несколько по другому. До тех пор, пока задача не будет разрешена или признана “условно неразрешимой” (решение недостижимо или бессмысленно по какому-либо ресурсу), т.е. пока не будет исследовано “достаточно хорошо” все пространство состояний, заключающее в себе задачу вместе со всеми окружающими контекстами, мы не можем остановить рекурсию ни “вглубь” (увеличение разрешения) ни “вширь” (размещение новых контекстов), так как критерия просто нет ни внутри, ни снаружи.
Более того, опасно даже сколько-нибудь менять механизм рекурсии - система, скорее всего, просто разрушиться. Системообразующие механизмы обязаны быть рекурсивными в самом строгом смысле (возможно привлечения других механизмов типа демонов, но на правах утилит “по вызову”).
Разрешимы ли такие задачи? Кто хочет проверить, может самостоятельно написать формулу, например, для оценки размера стека, необходимого для сортировки такого рода структур данных – рекурсивных деревьев.
Остается признать, что разрешимыми вообще в общем случае оказываются лишь задачи некоторые, принадлежащие множеству меры ноль, а именно задачи, не только метрические по своей природе, но еще и укладывающиеся в конечную разрядную сетку.
Что же делать с остальными задачами? Ведь именно они и представляют интерес, ради них вообще все это и существует: и объект исследования – интеллект, и само исследование.
Разумно предположить, что некоторый критерий для остановки рекурсии все же существует. При этом он по своей природе независим от:
Единственным доступным нам в этой ситуации является критерий устойчивости структур (здесь можно вспомнить гл. 5). Возможно, он вообще единственный. А именно, начиная с некоторого шага увеличение “разрешения” уже ничего не меняет, увеличение окружающего контекста приводит к распаду структур – “выходу за пределы задачи”. В качестве “псевдогладкого идентификатора” естественным образом напрашивается оценка “второй производной пространства состояний”. Но с тремя очень существенными оговорками.
Во-первых, пространство состояний – не в строгом смысле ТАУ, но в максимально расширенной трактовке, как полный контекст.
Во-вторых, (что, в общем, следует из первого) – производная в обобщенном смысле, поскольку априори мы не имеем права “пространство состояний” считать метрическим.
В-третьих, это текущая оценка динамики некоторого процесса. Как уже упоминалось выше, до достижения решения задачи мы не можем говорить об измерении каких-то величин, тем более о вычислении производных в строгом смысле, поскольку отсутствует априорная оценка “малости”. И, кроме того, система – открытая, контекст “пространства состояний” изменяется во времени.
То есть любое текущее значение производной в этом смысле не более чем частная оценка одного процесса относительно другого, но не производная в классическом смысле.
Что же в таком случае является “решением задачи”? Во-первых, некоторый набор структур данных, устойчивых в смысле вышеуказанной оценки второй производной. Но как уже отмечено, эта оценка имеет смысл только в совокупности с тем набором данных, по которому производилось вычисление оценок производных. В свою очередь этот набор данных имеет адекватную интерпретацию только в совокупности с полным конкретным описанием контекста окружения системы, т.е. с тем, что она знает к данному моменту и с текущим состоянием окружения, которое она наблюдает.
В целом оказывается, что метаструктура решения любой задачи состоит из трех уровней некоторых структур данных. И не только метаструктура конечного состояния, некоторого “статического описания” решения, но и структура самого процесса построения этого решения. Обратим внимание на следующие два обстоятельства.
В таких условиях, для того, чтобы сохранить хотя бы не гарантию, но надежду на сходимость процесса, остается только одна возможность – метаструктура данных должна быть единой, самоподобной как “внутрь”, вплоть до представления элементарных сигналов, так и “наружу” - до представления сколь угодно сложных образов (абстракций, решений и т.п.). В противном случае, и это очевидно, даже если удастся организовать процесс построения решения так, чтобы он не разрушился сам по себе, затраты только на механизм адресации, построения и поддержания структур данных будут расти быстрее счетной последовательности – опять достаточно вспомнить только оценку стека.
Решающим оказывается следующее обстоятельство. И в биологических, и в техногенных системах и для построения абстрактных моделей данных оказываются достаточными структуры, аналогичные B*-деревьям. Нам просто ничего придумывать не надо, надо только использовать рекурсивно тот же самый механизм представления данных и как модель организации любого уровня данных, и как метамодель организации иерархии уровней представления, и как метамодель процесса обработки данных.
В целом сказанное эквивалентно предположению о существовании некоторого закона рекурсии структур, метаструктур и процессов. Процессов это касается в том смысле, что процессы самоорганизации не могут не быть рекурсивными.
Здесь полезно рассмотреть одну интересную особенность. Использование гармонических шкал сильно “облегчает жизнь” тем, что если при переходе на следующий уровень разрешения задача существенно не изменилась, то это означает конец процесса, так как последующее дробление шкалы либо ничего не даст (гармоники из “третьего ряда” уже точно не влияют), либо (возможно через несколько шагов) мы выходим на другой уровень организации объекта.
Из существования общего закона рекурсии структур и метаструктур получается интереснейший вывод: каждая проблемная область имеет не более трех уровней метаструктур над структурой “элементной базы”. Назовем этот вывод “правилом тройки”.
Если же происходит “насильственное расширение рекурсии” вглубь или вширь, система получает достаточный объем новых данных об окружающем мире, либо нового контекста, т.е. априорных знаний в виде “новой теории”, то происходит распад проблемной области и организация новых.
В действительности в организации систем наблюдается целая совокупность законов (правил): помимо триадной организации каждого уровня представления данных наблюдается закон самоподобия уровней (правило структурной рекурсии) и самоподобие организации системы как целого (правило общесистемной рекурсии). Эти законы (правила) самоорганизации систем мы совокупно рассмотрим в гл. 12. А пока продолжим анализ феноменологии живых систем.
Сказанное выше позволяет нам несколько иначе рассмотреть уровни организации сложных систем, нежели это было сделано у К.Боулдинга, и придать им новый смысл и порядок в соответствии с результатами проведенного нами анализа феноменов информации и самоорганизации.
Для этого из процесса эволюции выделим некоторые этапы, перед перечислением которых укажем: мы берем “большие этапы”, те, на которых сформировались структурно-полные системы различных уровней. Отметим их характерные особенности.
1. Внутри каждого из сформировавшихся этапов дальнейшее развитие идет только “вширь” – за счет разнообразия структур (подвидов) одного порядка. Чем “ниже” уровень – тем “меньше различия по разумности” и больше разнообразия.
2. На каждой следующем этапе информационная система предыдущего этапа проявляется уже как целостная периферийная система, в том числе и морфологически целостная, т.е. выделяется адекватный функциональному назначению “аппаратный уровень”. В частности, у позвоночных наблюдаются четыре “большие этапа” – соответственно разделам организации нервной системы.
Рассмотрим рис. 11.1. Итак:
1. В первый раз обратная связь замкнулась на прединформационном уровне у одноклеточных (на рисунке не рассматривается), т.е. их выходные реакции на том же уровне, что и входные – физические, физико-химические.
2. Структурно-полный уровень организации первичных сигналов сложился у насекомых, а высший уровень организации у них – внешний, как, например, у пчел. Здесь мы наблюдаем метауровень как коллективное существо. Это последний уровень, на котором допустимо говорить о существовании какой-то полной системы изоморфизмов входных и выходных сигналов единичной особи. Для следующих уровней такое сказать уже нельзя, больше того изоморфизм сигнала и “того, что циркулирует в контуре обратной связи ОС2” существует только для отдельной особи, экземпляра.
В целом, для совокупности особей это “циркулирующее” структурно, по своей организации, более сложно, чем совокупность сигналов. Строго говоря, здесь уже заканчивается сигнальный уровень представления, мы можем именовать этот уровень сигнальной системой только условно, для привязки к традиционной терминологии. Справедливо считать, что именно здесь и появляется процесс (феномен, явление) структурно более сложный, чем совокупность сигналов. Здесь появляется другой, информационный уровень организации или собственно информация как явление, самый первый уровень ее организации, который мы обозначим как И1.
В дальнейшем термин “сигнальная система” употребляется для привязки к традиционной терминологии и обозначения того, что это представление используется для внешней, между отдельными особями, коммуникации. Точно так же становится условностью обозначение более высоких уровней организации как контура обратной связи, это уже не функциональная зависимость, но некоторая свертка, не представимая, в общем случае, конечным алгоритмом.
3. У позвоночных этот уровень, т.е. совокупность периферических нервных клеток и уровня, обозначенного И1, уже внутри. Он, представляет собой функционально и морфологически полную внешнюю нервную систему. Их (позвоночных) “внешняя сигнальная система” вторая – И2.
4. Соответственно у млекопитающих, вплоть до приматов третья – И3.
5. “Сигнальная система человека” – самый примитивный из появившихся устойчивых языков – “четвертая сигнальная система” (что нам приходится констатировать вопреки утверждениям биологов).
Это на самом деле очень важно учитывать при анализе, особенно при сравнении приматов и человека. У тех и других имеется структурно-полный информационный уровень и метауровень, но метауровень разный. У приматов это система пирамидальных структур, может быть и весьма богатых (кстати и у птиц, на предыдущем уровне, наблюдаются очень высокие структуры – псевдоречь), но это метауровень по существу структурно неполный.
На рис 11.1 И4 обозначает выходное представление некоторой физической структуры (коры), функционально это высший уровень организации нервной системы и у высших, и у человека, но организованный существенно различным образом.
При переполнении верхней структуры дальнейшее ее расширение путем механической надстройки еще одного “аппаратного уровня” почему-то не произошло. Произошла реорганизация этого уровня, изменение способа его функционирования. Причина и механизм такой реструктуризации окажутся, в дальнейшем, ключевым моментом.
У человека сформировался другой уровень базового языка и базовых образов, нежели у приматов. Можно некоторое их найти соответствие и сделать словари, но “образ мыслей” – разный. Для собак и обезьян –“ближе к нам”, для дельфинов – дальше, но говорить об изоморфизме нельзя{165. Поведение дельфинов, “более близкое в некотором смысле” к человеку, можно объяснить наличием сонара, сенсора, поставляющего мозгу образы гораздо более богатые и целостные, чем даже объемное изображение. Наземным обитателям таковые недоступны физически, только человек способен “восстановить из проекций” и “домыслить” нечто подобное, но уже “через верх”, через осознание и обдумывание образа, т.е. из-за сложности, длительности процесса “реконструкции образа” и неизбежных потерь информации на разных уровнях этого процесса, человек может в каком-то смысле быть “тупее” дельфина.}. Как устроен этот уровень у человека, т.е. И4 – вопрос не тривиальный и заслуживает отдельного рассмотрения, здесь же отметим следующее.
Для приматов “слово” и “образ слова” (“знак”) одно и тоже, для нас (по крайней мере, для большинства) – нет. Это можно наблюдать по тому эффекту, что у человека в коре строго специализированные “речевая” и “зрительная” зоны, у приматов же должны быть морфологические или функциональные отличия, так как при активной работе “речевого центра” образуется другой характер взаимодействия с остальной корой. Человек “слышит слова”, но “учитывает образы”.
Язык 4 (см. схему ниже) это не поток слов, а поток образов, достроенных с помощью контекстного анализа, то есть это четвертая сигнальная система – иначе неизбежна путаница в анализе. То же самое и зрение: образ видимый и образ воспринимаемый сознанием разные.
Биологи и другие специалисты это и так знают, однако неточность (принятые ими только три “сигнальные системы”) им пока не очень мешает{166. После работ И.П.Павлова, т.е. двух сигнальных систем достаточных для управления на уровне примитивных рефлексов, всё остальное многообразие поведения все дружно решили упаковать в одну “третью” сигнальную систему – начиная от философов и до исследователей ИИ. Действительность, однако, сложнее, но и понятнее в этой сложности.}. Но непонимание того, что на вход речевого анализатора, например, для управления компьютером, поступает сигнал четвертого уровня, т.е. из среды, имеющей над физическим уровнем (собственно сигнальным) структурно-полную организацию, ведет к созданию неустойчиво работающих конструкций, это попытка обработки того контекста, который изначально не был предусмотрен в системе.
Иллюстрируем сказанное выше дополнительным схематическим построением:
Насекомые: сигнал > свертка 1 > “язык 1”; (между сигналом и языком полный изоморфизм, это коллективное существо).
Позвоночные: сигнал > свертка 1 > информация > “язык 1” > свертка 2 > “язык 2”.
Приматы: сигнал > свертка 1 > информация > “язык 1” > свертка 2 > “язык 2” > свертка 3 (граница интеллекта) > “язык 3”.
Человек: сигнал > свертка 1 > информация > “язык 1” > свертка 2 > “язык 2” > свертка 3 (граница интеллекта) > “язык 3” > свертка 4 > “язык 4”.
Не правда ли, замечательная путаница из “языков” и “сигнальных систем”? Но заметьте, не мы эту путаницу придумали – она сложилась из вольного употребления самих этих слов, языком именуется и живой язык (т.е. даже шире, чем язык, существующий на данном отрезке времени, чем язык популяции) и некоторая совокупность сообщений на этом языке; сигнальной системой именуется, по-видимому, совокупность из живого языка и интерпретатора – субъекта, т.е. сущность другого порядка сложности, чем последовательность сигналов, даже более сложная, чем сам “язык”.
Ясно, что под сигнальной системой на самом деле надо подразумевать систему контекстно-зависимого (КЗ в широком смысле, включая умолчания) субъектно-объектного взаимодействия. Оставим в стороне терминологические тонкости и отметим здесь только следующее. Из последовательности преобразований “сигналов” в “языки” только свертка 1 имеет эквивалент в виде конечного алгоритма, остальные свертки – процессы контекстного анализа.
11.4. К вопросу об элементарной ячейке
Теперь, с учетом сказанного в предыдущих разделах, сконструируем (следуя рис 11.1, т.е. тому способу устройства систем, который мы подсмотрели в Природе) минимальную метаструктуру данных, достаточную для описания открытых систем.
Структура, соответствующая
“млекопитающим” (еще раз заметим –
классификация условная) содержит три больших
раздела – “внешнюю нервную систему”,
“стволовую” и “центральную”. Центральная
нервная система – функционально-полная, т.е.
внутри, в своем представлении, должна содержать
три уровня, “полно представлять
систему-как-целое”, что и изображено на рисунке.
Обозначим это внутреннее представление ЦНС как
уровни ![]() ,
, ![]() ,
, ![]() , каждый из которых также содержит
три “подуровня”, обозначенных кружками.
, каждый из которых также содержит
три “подуровня”, обозначенных кружками.
Будем считать, что внутри каждого
уровня (уже ЦНС) различаются только два состояния
каждого из подуровней (обозначенных кружками
внутри прямоугольников) – “заторможенное” (0) и
“возбужденное” (1). Таким образом, каждый из
уровней представляется восемью различными
состояниями, то есть состояние уровня ![]() представляется
трехуровневым бинарным деревом. Состояния
подуровней внутри
представляется
трехуровневым бинарным деревом. Состояния
подуровней внутри ![]() “с точки зрения
“с точки зрения ![]() ”
– только различимы, т.е. состояние “
”
– только различимы, т.е. состояние “![]() с учетом
с учетом ![]() ” представляется уже
четырехуровневым деревом 1-2-4-8.
” представляется уже
четырехуровневым деревом 1-2-4-8.
При этом для нижнего уровня, листьев
этого дерева, возможно потребуется циклический
сдвиг на одну позицию, поскольку состояния ![]() “различимы”, но не
имеют “естественной нумерации”. Т.е.
потребуется “подбалансировка” дерева
(механизм, аналогичный B*-деревьям в Cache’).
“различимы”, но не
имеют “естественной нумерации”. Т.е.
потребуется “подбалансировка” дерева
(механизм, аналогичный B*-деревьям в Cache’).
Наконец, чтобы учесть внутреннее
состояние ![]() , мы
должны сопоставить каждому листу дерева 1-2-4-8
некоторую структуру данных, вмещающую восемь
различимых и разных состояний, некоторый
“восьмиместный зарядовый пакет”. Для дерева
1-2-4-8 (с добавкой “собственно данных”, состояний
, мы
должны сопоставить каждому листу дерева 1-2-4-8
некоторую структуру данных, вмещающую восемь
различимых и разных состояний, некоторый
“восьмиместный зарядовый пакет”. Для дерева
1-2-4-8 (с добавкой “собственно данных”, состояний ![]() ), содержащего
“входные данные”, потребуется уже полная
балансировка, поскольку для представления
), содержащего
“входные данные”, потребуется уже полная
балансировка, поскольку для представления ![]() состояния внутри
состояния внутри ![]() уже не различимы, есть
только последовательность сигналов, изменяющая
состояния
уже не различимы, есть
только последовательность сигналов, изменяющая
состояния ![]() и через
его выход состояния
и через
его выход состояния ![]() .
.
Итак, мы получили не что иное, как
“естественную метамодель организации данных”,
просто “сложили минимальное представление”
наиболее простым из возможных способов.
Раскрывая внутренние состояния подуровней ![]() путем “надстройки
вверх” метадерева по тому же закону 1-2-4-8 и
“увеличивая разрешение представления внешних
сигналов” путем расширения B*-деревьев
“собственно данных” кратного восьми, мы можем
автоматически, используя только принцип
самоподобия (т.е. чистую рекурсию), строить сколь
угодно сложные модели данных.
путем “надстройки
вверх” метадерева по тому же закону 1-2-4-8 и
“увеличивая разрешение представления внешних
сигналов” путем расширения B*-деревьев
“собственно данных” кратного восьми, мы можем
автоматически, используя только принцип
самоподобия (т.е. чистую рекурсию), строить сколь
угодно сложные модели данных.
Напомним, контекст окружения самого нижнего уровня, собственно данные, мы не имеем права считать имеющим какой-то априорный порядок, для нас это просто поток данных, априори неизвестного размера. Поэтому “расширение вниз” мы должны производить не “надстройкой вниз” структуры B*-деревьев, а только увеличивая размер массива данных.
Попутно заметим, что благодаря работе механизма балансировки B*-деревьев система (полученное представление) становится устойчивой к сбоям и даже выходу из строя отдельных компонентов “элементной базы”.
Но главный, ключевой момент построения нашей “информационной машины” заключается даже не в этом. Вспомним, что любое “адресное представление”, любая модель данных, в конечном счете, прекращает свое существование исключительно потому, что нарушается именно механизм адресации, происходит переполнение описания (адресного поля) и модели и физической памяти.
То есть в итоге требуется создание нового описания, новой модели и подключение отдельного механизма порождения этой новой модели и реорганизации физической памяти. В общем виде такой механизм реорганизации реализуем только для B*-деревьев – напомним, что для любых других представлений (модели Кодда, алгебраических матриц, графов, сетей и т.п.) требуется внешнее глобальное описание размера, числа элементов структуры уже априорно заданное, т.е. конечно-вычислимое описание структуры “больше которой не может быть”.
Фактически это неизбежно. Если придерживаться адресной концепции, нумерации “ячеек памяти” при которой неизбежен “конфликт с конечной вычислимостью”, то мы получим представление, которое не только “нельзя вычислять”, но невозможно даже “понумеровать элементы представления”{167. Впрочем, все сказанное изложено в конструктивной формулировке теоремы Геделя, суть которой сводится к тому, что, начиная с некоторого уровня сложности, любая модель становится сколь угодно сложнее самого моделируемого объекта.}.
В нашем же случае механизм адресации (а, значит, и затраты на него) вообще не нужен, достаточно “самоподобно коммутировать самоподобные элементы”. Благодаря тому, что мы идем на затраты – выделение “ячеек” для запоминания “пустых элементов”, мы избавляемся от затрат в итоге катастрофических – на организацию адресации как таковой{168. Подробнее см., например, В.Кирстен, От ANS MUMPS к ISO М. Перевод с нем. СПб, изд. АОЗТ “СП.АРМ”, 1995.}, на построение того механизма, который неизбежно должен сам себя разрушить.
Теперь заметим, что “ниже” уровня И3
(конкретно подуровня ![]() ) имеется еще два функционально и
аппаратно полных подуровня - “стволовая нервная
система” и “периферическая нервная система”. В
соответствии с построением метамодели данных, мы
должны считать их соответственно совокупностью
“узлов” (некоторым множеством, не имеющим
априорного числа элементов и “упорядочения”,
“нумерации”) и “потоком значений внешних,
физических сигналов” (также априори не
нумерованным).
) имеется еще два функционально и
аппаратно полных подуровня - “стволовая нервная
система” и “периферическая нервная система”. В
соответствии с построением метамодели данных, мы
должны считать их соответственно совокупностью
“узлов” (некоторым множеством, не имеющим
априорного числа элементов и “упорядочения”,
“нумерации”) и “потоком значений внешних,
физических сигналов” (также априори не
нумерованным).
То есть к элементам “собственно данных”, лежащим “ниже” структуры метаданных (контекста, дерева 1-2-4-8), мы должны присоединить некоторую структуру, но уже отличную (даже и по способу хранения и обработки). Это уже должно быть B*-дерево по определению структуры в стандарте MSM-ANSI. Другую, более сложную структуру, обладающую “собственными свойствами”, мы не имеем права даже предполагать, как уже говорилось выше, таковая неизбежно требует адресации, а, значит, неизбежно саморазрушится из-за переполнения.
Таким образом, конструирование модели метаданных привело нас к структуре бинарного дерева 1-2-4-8 и присоединенной к листьям этого дерева системе B*-деревьев. “Меньшая” структура не будет обладать универсальностью, возможностью моделировать произвольные структуры данных. “Большая, более богатая” неизбежно заставит придумывать способ адресации, т.е. вводить априорное (искусственное и ничем объективно не заданное) упорядочение, шкалирование сигналов внешнего Мира.
Обозначим эту структуру 1-2-4-8 как ![]() , а присоединенную к
ней “структуру упорядочения сигналов”, т.е.
систему B*-деревьев назовем структурой Z. Заметим,
что структуру Z мы в некотором смысле можем
считать “спрятанной” в листья базового дерева
, а присоединенную к
ней “структуру упорядочения сигналов”, т.е.
систему B*-деревьев назовем структурой Z. Заметим,
что структуру Z мы в некотором смысле можем
считать “спрятанной” в листья базового дерева ![]() .
.
Элементарное внутреннее представление для систем рассмотренного выше уровня уже не бит, а состояние четырехуровневого бинарного дерева – если, конечно, принять здесь самое простое из возможных – бинарное представление состояний. В соответствии с этим “элементарной ячейкой”, аналогичной ячейке, например, регистра, может быть только структура, как минимум целиком вмещающая указанное дерево. Элементом памяти для размещения таких деревьев должна быть как минимум структура, вмещающая листья этого дерева, как один целостный элемент данных, но не в математическом, а в “микросхемном” смысле{169. Отметим, что “элементарное внутреннее представление” и “ячейка памяти” это не обязательно одно и тоже.}.
Это имеет и косвенное, но общеизвестное подтверждение – мгновенная или подсознательная память человека устроена “по восьмеркам”{170. Напомним, что во всех без исключения психофизиологических исследованиях фигурирует один и тот же факт – человек подсознательно воспринимает и классифицирует образы “группами по восемь” вне зависимости от того, есть ли это элементарные сигналы или образы очень сложные как, например, в опытах по “соревнованию с компьютером” в скорости счета или запоминанию больших текстов или больших массивов неструктурированной (неосмысленной) информации. Не будем рассуждать о смысле скоростного запоминания и последующего цитирования телефонной книги, но факт: такие опыты состоялись во множестве и одна из главных выявленных закономерностей – механизм памяти работает “группами по восемь”. Другой вопрос, что на самом деле работает целая совокупность механизмов, и разделить их, идентифицировать работу каждого в отдельности, исходя из самих этих экспериментов практически невозможно.}.
Как уже упоминалось выше, нервное волокно гораздо более богатая структура, чем провод для передачи телеграфного сигнала. Подтверждение тому – гигантское количество экспериментального материала в биофизике.
Из предположения квантовой природы передачи сигналов в нервных клетках запоминающей ячейкой должен быть шестиместный зарядовый пакет, “в динамике” – 6 узлов волнового фронта, такой своеобразный оптоэлектронный преобразователь. Действительно, у насекомых распространены (у многих явно просматриваются) шестиугольные фасеточные структуры. Базовая структура из шестиугольных фасеточных структур 6 – (6+6) – (6+6+6+6) имеет вид дерева 1-2-4.
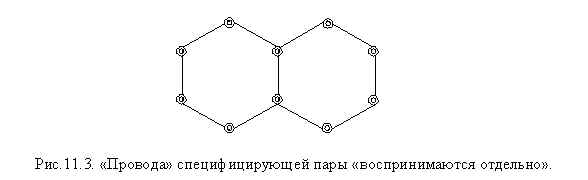
Разумно предположить, что для устройства более сложных структур природа ничего лишнего не изобретала, а воспользовалась уже имеющимися решениями. Тогда у млекопитающих, по видимому, произошло скручивание проводов в пару, т.е. S1=8 – (8+8) – (8+8+8+8) (рис. 11.2.),
S1=
Рис. 11.2. “Провода” специфицирующей пары, т.е. узлы фронтов неразличимы или не используются – требуется “конструктивная доработка”, чтобы устойчиво различались.
а, начиная с некоторого уровня, возникла отдельная спецификация “спаренных волноводов” S2 = (8)- (8+8)-(8+8+8+8)-(8+8+8+8+8+8+8+8) плюс, соответственно, дерево 1-2-4-8.
У человека произошла спецификация “совместной пары” S3 = (8+8)-(8+8+8+8)-(8+8+8+8+8+8+8+8)-(8+8+8+8+8+8+8+8+8+8+8+8+8+8+8+8) плюс, соответственно, дерево 2-4-8-16.
Мы рассмотрели “раскладку проводов” или узлов фронтов, т.е. “реконструировали” способ, с помощью которого можно “спрятать” внутри бинарного дерева восьмиместное представление. Причем реконструкция выполнена наиболее простым и естественным способом как “с позиции наблюдаемого”, на основе шестиугольных фасеточных структур (на самом деле и клеточных структур, и структур белковых молекул), так и с позиции геометрии, волоконной оптики и ряда новейших исследований.
Остался только “лишний элемент”, специфицирующая пара (рис 11.3), как мы сейчас выясним, ключевой элемент для формирования аппаратной базы коры мозга человека.
Посмотрим с позиции нашей реконструкции, как должен выглядеть элемент представления следующего уровня, “эквивалент элементарного сигнала для И4”. Дальнейшая “чисто аппаратная надстройка” того, что изображено на рис.11.1 невозможна, структура заполнена, содержит три функционально полных уровня, три полных уровня ЦНС и каждый из них состоит из трех подуровней.
Элементарный же сигнал, “элемент
состояния И4 должен содержать уже парное
представление выхода И3, т.е. ![]() “предыдущее”, то, что
было раньше запомнено и
“предыдущее”, то, что
было раньше запомнено и ![]() “текущее”, то, что вызвано последним
сигналом, последним изменением состояния среды.
“текущее”, то, что вызвано последним
сигналом, последним изменением состояния среды.
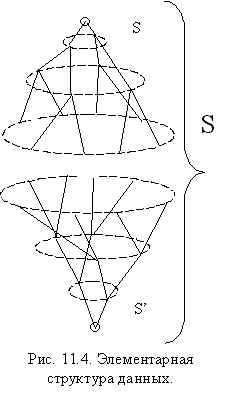
Такая конструкция может быть представлена как пара бинарных четырехуровневых деревьев “свернутых в конусы” - рис. 11.4. Оставим пока на дальнейшее вопрос о том, как присоединяется и формируется конструкция из двух структур Z. Здесь отметим только следующее.
1. Фактически на рис. 11.4 изображен
четырехмерный конус, совпадение его с
рассмотренным выше топологическим
представлением данных очевидно, но отметим
важный факт – если базовое дерево, представление
![]() было “наиболее
естественным” для уровня И3 и
“минимальным”, то представление в виде рис. 11.4,
парной структуры S,S’ вообще единственное,
которое возможно разместить и обрабатывать в
некоторой физической среде, в трехмерном
представлении. Причем сделать это можно только
используя некоторую “пометку”, отличающую S от
S’ и обеспечивающую их совместную “обработку” в
одном физическом элементе, т.е., например, уже
упомянутую выше “специфицирующую пару”.
было “наиболее
естественным” для уровня И3 и
“минимальным”, то представление в виде рис. 11.4,
парной структуры S,S’ вообще единственное,
которое возможно разместить и обрабатывать в
некоторой физической среде, в трехмерном
представлении. Причем сделать это можно только
используя некоторую “пометку”, отличающую S от
S’ и обеспечивающую их совместную “обработку” в
одном физическом элементе, т.е., например, уже
упомянутую выше “специфицирующую пару”.
2. Структура S оказывается существенно динамической, так как должен непрерывно работать и механизм согласования половинок S,S’ и механизм подключения и взаимосогласования соответствующих им структур типа Z. Но этим мы займемся в гл. 13.
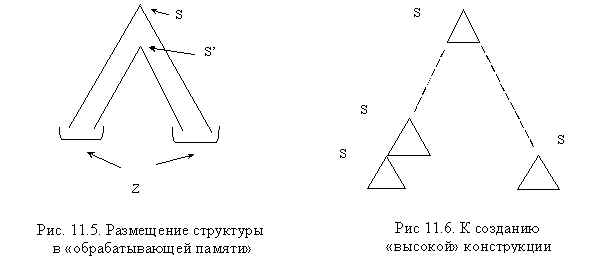
Если разместить элементарную структуру данных S (память, “то, что сформировано при обучении”) и S’ (“то, что наблюдается”, “задача”) в некоторой адресной памяти, то потребуется специальный механизм адресации для идентификации и совместной обработки S и S’ – рис. 11.4.
 При размещении
структуры S в некоторой “обрабатывающей
волоконно-оптической памяти” структура S’
является просто “запускающим импульсом”, а
“совмещение половинок”, их “относительный
поворот” достигаются путем обработки сигнала
специфицирующей пары – рис. 11.5.
При размещении
структуры S в некоторой “обрабатывающей
волоконно-оптической памяти” структура S’
является просто “запускающим импульсом”, а
“совмещение половинок”, их “относительный
поворот” достигаются путем обработки сигнала
специфицирующей пары – рис. 11.5.
Но то же самое справедливо и для сколь угодно “высокой конструкции”, построенной из элементов S, т.е. никакой механизм управления адресацией становится просто не нужен, система работает автоматически – рис. 11.6.
Напомним про инвариантность представления. На самом деле не существенно, когда произошла спецификация проводов – на переходе к млекопитающим, приматам или человеку. Просто человек “научился (захотел, был вынужден) активно их использовать”, т.е. поддерживать две информационные структуры сразу, но за это расплатиться необходимостью использования и непрерывной обработки чудовищных потоков информации и потерять за эмоциональность и контекстность свободу непосредственного восприятия Природы, по-видимому, доступную на предыдущем шаге развития.
Это значит, что “появилась аппаратура для дуального представления Мира” (восприятия, “двухпалатного” сознания).
11.5. Некоторые количественные оценки элементной базы
Таким представляется сегодня элемент “канального преобразователя”. Сколько состояний у такого “микропроцессора” сказать без дополнительных исследований достаточно проблематично. Однако можно с уверенностью сказать, что в нем (нейроне) со стороны каждого входа не менее одной метаструктуры типа S для представления принимаемого состояния и одной ответной S’ – для внутреннего представления (предыдущего состояния).
Попробуем оценить “эквивалентную информационную емкость” нейрона, исходя из самых простых предположений и общепринятых численных оценок. Например, возьмем оценку числа входов и других параметров нейрона из работы [33]. Самый простой сервисный нейрон, выполняющий функции “канала связи”, имеет два входа, т.е. должен “обслуживать” (отображать и передавать) две структуры типа S.
Пусть его “внутренняя память” запоминает только состояния самого нижнего уровня структуры S и каждый из проводов передает только два состояния сигнала. Т.е. описание состояния входа должно содержать 8х8=64 однобитовые “ячейки” (узла дерева), каждая из которых имеет два состояния. И таких “полей памяти” для структуры S надо два – для S и S’, т.е. в сумме 128 однобитовых “ячеек”.
Напомним теперь, что мы строим “безадресный механизм”, восемь состояний должны занимать восемь бинарных “ячеек”, мы не имеем права кодировать их{171. А, например, применяя трехбитовый регистр (т.е. позиционную восьмеричную систему записи “состояний как чисел”) мы вынуждены кодировать эти состояния, значение каждой “однобитовой ячейки” определяется ее позицией в регистре, т.е. принятой системой исчисления и принятым разбиением на регистры. Но разбиение на регистры это уже и есть система адресации.}. Для каждого отдельного узла дерева мы должны выделять отдельную структуру памяти, для структуры S, для каждого отдельного состояния составляющих ее половинок, соответственно 128-битовый регистр, 128 ячеек. Для восприятия двух входов нейрона соответственно два регистра по 128.
Считая “байты” (в кавычках, потому что это не байты в восьмеричном смысле, а группы по восемь однобитовых ячеек) независимыми, поскольку они не связаны никакой позиционной системой счисления, и считая, что они реализуются как независимые физические структуры, получим оценку “эквивалентного адресуемого поля” 256 Кбайт.
Что и говорить, мы очень неэкономно распорядились “однобитовыми ячейками”, однако не будем спешить с выводами, пока это модель простейшего “транспортного нейрона”.
Будем считать, что для “высокого нейрона” использован тот же механизм запоминания состояний. Ориентируясь на оценки общепринятые [например, 33 и др.], считая, что “высокий нейрон” имеет ~102 рабочих и ~104 обучающих входов, и каждый вход различает ~102, т.е. около 64 разных пороговых состояний (что как раз соответствует “модели канала”, т.е. числу состояний структуры S), получим оценку “оперативной памяти” ~2,56 Гбайт и “долговременной” ~2,56х104 Гбайт. Но если предположить, что каждая “однобитовая ячейка” реализована как состояние валентной связи в некоторых молекулярных структурах, например, “тубулиновых микротрубочках С.Хамероффа”, то оценка совсем не представляется безумной с точки зрения возможностей ее физической реализации.
А теперь обратим внимание на следующий факт. Сложная структура из двух уровней структур типа S, содержащая только две нижние структуры S имеет вид, изображенный на рис. 11.7.

Т.е. для “пустых” узлов верхней структуры S, а значит и соответствующих им “нижних структур не надо резервировать место, их можно вообще не строить, им не надо присваивать имя, можно вообще “о них забыть”. Физически это место может быть отдано другим структурам, принадлежащим другой метаструктуре. Это и есть безадресная организация или, иначе говоря, механизм самоадресации данных.
Чем более сложные, т.е. высокие структуры реализуются, тем больше экономия оттого, что не надо даже думать о “предке без потомков”, “имя без данных” просто не существует по умолчанию, т.е. не требуется никаких специальных механизмов именования, резервирования и т.п. О том, как упаковываются высокие структуры для хранения на уровне “собственно данных”, т.е. в то, что мы называли выше B*-деревьями, организованными в Z структуры, мы поговорим отдельно в следующих разделах.
Впрочем, читатель возможно уже и сам об этом догадывается, в частности и о реализуемости механизма такого свойства в “многослойной голографической памяти” или чем-то подобном.
Отметим еще раз интереснейшую особенность – при размере оперативной памяти от двух до десяти гигабайт рассмотренный здесь “существенно неэкономный механизм” и самый экономный из известных способов управления адресами, применяемый в системе Cache’ для адресной архитектуры становятся эквивалентными по расходу элементарных однобитовых ячеек. Для более сложных структур любой способ адресации будет уже безнадежно проигрывать.
Чтобы пояснить это, в общем-то не сразу очевидное утверждение, сделаем небольшой отступ. Традиционно объясняют “преимущества” фон Неймановской архитектуры нехитрым примером. Восемью битами можно адресовать 256 слов (байт), 16 битами – 256 Кбайт и т.д. Т.е. длина адресной части команды логарифмически зависит от размера адресуемого поля.
На самом деле забывают (почему?) о том, что использование адресов требует имен, каталогов имен, иерархической системы описания адресного пространства, а, значит, памяти для размещения всего этого. О том, что требуется механизм для создания, использования и модификации этой системы описаний, а, значит, и ресурс для работы этого механизма (т.е. память и время) забывают тем более.
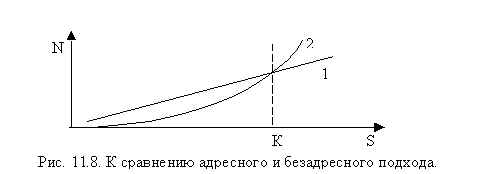
А речь здесь идет именно об этом, о затратах на создание и поддержание совокупности этих механизмов, которые только и делают адресную архитектуру работоспособной. До некоторых пор, в “начальный период развития компьютерной техники” мы находились в начале некоторой затратной кривой, описывающей зависимость совокупных затрат на управление адресным пространством от размера адресуемого поля. В настоящее время мы приближаемся к дальнему концу графика, к критической точке, где затраты на поддержание “каталогов над каталогами”, иерархии описаний должны превысить объем самой полезной информации, того, для чего эти каталоги создаются. Все это можно изобразить на графике рис.11.8.
На нем:
N – количество однобайтовых ячеек, используемых для представления;
S – сложность модели данных, оценивая, например, в байтах;
1 – график для безадресной памяти;
2 – график для машины фон Неймана.
Для машины фон Неймана N взято с учетом расхода на описание всей совокупности структур данных БД, механизмов интерпретации и необходимого совокупного “свободного пространства” для работы всех механизмов БД, т.е. это полный объем памяти компьютерной системы.
К – критическая точка, лежащая в зависимости от принятой модели данных в диапазоне от 2 до 10 Гбайт.
Похожие оценки происходят из очень сложных и туманных вычислений, с многочисленными оговорками их авторов. В простейшем случае ищется (экспериментально оценивается) просто некоторый размер необходимой памяти того, что мы здесь называем “информационной машиной”. Но вообще-то необходимо учесть то обстоятельство, что существуют не только различные скорости работы уровней механизмов памяти компьютера, который и используют в качестве “расчетной модели”, но существует и собственная динамика информационных процессов (внешняя динамика, которую компьютер только моделирует).
Рядом исследователей в этой связи рассматривалось понятие “точки вспышки разума” в смысле количественной оценки аппаратных затрат и их “динамических характеристик”, после чего может произойти нечто нетривиальное. Например, по Р.Пенроузу, у червя с его 302 нейронами таких “моментов сознания” может происходить не более двух в секунду – на большее “аппаратного обеспечения” не хватает.
Однако в целом “количественные оценки динамики информационных процессов” ровно ничего не поясняют, кроме того факта, что динамика эта есть в Природе, но она слабо связана (а может и не связана) со скоростными соотношениями работы уровней памяти в компьютере, не очень подходящем инструменте используемом для ее моделирования.
Не будем заниматься оценкой “правильности” точки К на графике, скорее всего эта величина существенно переменная, зависящая от модели данных, примененного программного обеспечения. Здесь важно другое, достаточно близкое совпадение ее оценок в разных, независимых исследованиях и ее совпадение с приведенной здесь “оценкой памяти” нейрона уже вообще ничего не имеющей общего с оценками физических энтропийных моделей, по смыслу от любых энтропийных подходов независимой.
Иначе говоря, там где Природа безнадежно проиграла на конструкции нейрона, там же она и абсолютно выиграла на возможности строить из этих нейронов сколь угодно большие конструкции. И не просто строить “сколь угодно сложные” конструкции, “модели данных”, но и делать это, не используя вообще никаких специальных формализмов моделирования, а только один принцип самоподобия, чистую рекурсию.
Завершая этот раздел невозможно обойти вниманием следующее обстоятельство.
Если изложенная выше модель “безадресной памяти” покажется читателю слишком сложной, ознакомьтесь с упомянутыми вычислениями и туманными интерпретациями оценок, так или иначе численно совпадающих с критической точкой К, после чего станет ясен весь юмор ситуации. А заодно станет понятнее, есть ли смысл в попытках описать и понять интеллект, негэнтропийные системы средствами теории передачи информации, т.е. средствами, сделанными для энтропийных систем и, разумеется, пригодными только и исключительно для них.
Полезно, по-видимому, дать еще одно пояснение. Логарифмическая зависимость длины адреса от размера адресного поля не зависит от самого размера памяти и с этой позиции приведенный график кажется нелепой выдумкой. По крайней мере, возникает желание получить “доказательство” или “точное значение” положения точки К на графике.
Но в том то и дело, что “доказательства в строгом смысле” не существует. Дело не в том, что каждому элементу можно сопоставить некоторое число, адрес, а в том, как этими адресами пользоваться. ПК 1999 года на базе Pentium III по мощности соответствует всем компьютерам космических комплексов СССР и США на 1969 год, однако посмотрим как и на что эта мощь расходуется.
Попробуйте рассчитать на этом ПК, например, вывод на орбиту спутника – если Вы не специалист по орбитальной баллистике, то все ПО Вам не поможет.
Точно так же бесполезно поручать компьютеру расставить запятые в некотором “среднем” тексте. Так же и все графические пакеты очень мало помогут не умеющему читать чертежи.
Наконец, вспомните, много ли Вы знаете индивидуумов, знающих в точности назначение всех кнопок в той или иной сколько-нибудь сложной программе?
Все это и отображено на графике рис. 11.7. Это и означает, что вся совокупность прикладного ПО, по размеру превосходящая 8 гигабайт стандартного HDD, “сама умеет” только помочь некоторому “среднестатистическому пользователю” сформулировать и решить свою прикладную задачу. Т.е. фактически большая часть памяти и мощности тратится на управление ресурсом, на то, чтобы этим ресурсом можно было пользоваться.
Сделаем прямой практический вывод – прогноз будущих изменений в машинах и операционных системах.
Становится все более ясно, что начиная с объема оперативной памяти более 10 Гбайт эффективность всех известных подходов, всей суммы информационных технологий, базирующихся на адресном представлении, т.е. совокупности {ОС – операционная оболочка – прикладная система} резко перестает расти. А относительная эффективность, “коэффициент полезного действия” от увеличения мощности машины станет резко падать.
Выживут лишь две “ветви генеалогического дерева”. Во-первых, это матричные процессоры типа “колумбийской машины”{172. О “колумбийском процессоре” см. далее по тексту книги.}, т.е. те, топология данных, модель данных в которых адекватна реализуемому вычислительному процессу, например моделям механики сплошных сред, моделям взрывов, потоковых процессов и т.п.
Во-вторых это будут “машины управляемые данными”, хотя и базирующиеся на “адресной аппаратной базе”, но использующие существенное развитие идей подходов, перечисленных в восьмой главе, реализующие прямое управление ресурсом, адресным полем от динамической модели данных.
Остальные ОС и операционные оболочки просто “вымрут как динозавры”, останутся как реликты для студентов, для изучения истории науки об информации, той самой computer science, от которой сейчас старательно открещивается информатика.
| Site of Information
Technologies Designed by inftech@webservis.ru. |
|