14.1. Концепция вертикальной машины
14.2. Структура команд
14.3. Программирование и запуск
14.4. “Перед прочтением уничтожить”
14.5. Что с ней делать?
14.6. Имитация вертикальной машины в
адресной среде
Глава 14. Вертикальная машина
14.1. Концепция вертикальной машины
Эту главу целесообразно начать с упоминания об открытии, свидетельствующем в пользу высказанной нами гипотезы о квантово-волновом механизме устройства и работы нейрона и всего мозга – технической реализации физической среды, которая может “обрабатывать” волновой фронт в процессе его прохождения.
В конце 1998 года (т.е. когда уже были опубликованы наши “Избранные лекции” [11]) в Массачусетском технологическом институте были завершены работы по созданию принципиально нового оптического волокна – “омигайд”{237. Информация получена при прослушивании радиопередачи о новостях науки в Америке. За незнанием точных характеристик этого оптоволокна, пока укажем, что это не единственная разработка. Известно, например, оптоволокно компании Lucent Technologies – многомодовое канальное решение OptiSPEED Plus. Это означает, что промышленность начала XXI века уже решила или сейчас заканчивает решение проблем создания нужной нам технологии. Во всяком случае, характеристики оптоволокна, которые мы рассматриваем, являются достижимыми, а не фантастическими.}. Необычная структура волокна – своего рода “рулет”, скатанный из нескольких слоев материалов разной оптической плотности, обеспечивает совершенно необычные свойства.
Во-первых, такое волокно является практически “сверхпроводником”, потери чисто статистические на уровне отдельных квантов и очень низкие (в известном нам информационном сообщении конкретная цифра не приводится, косвенно из него следует величина меньше 10-10). При этом свойство сохраняется при изгибе волокна, соединении и разветвлении волокон. Т.е. на таких волокнах вполне реально строить как “одноквантовые” (разумеется с последовательной передачей несколько раз подряд для надежной компенсации статистических потерь) каналы, так и сложные системы.
Во-вторых, “омигайд” – система сверхширокополосная, в отличие от традиционного волокна свойства, в том числе и проводимость, уровень потерь, сохраняются во всем диапазоне частот от “черного провала” до нижнего ультрафиолета включительно{238. А это прямо означает, что на базе такой структуры возможно строить процессоры с многоступенчатым преобразованием типа “волновой фронт – состояние – и обратно”, строить напрямую, без специального механизма подкачки энергии, так как на каждой ступени преобразования будет ступенчато падать энергия (т.е. частота) кванта. Так как этот вывод уводит нас в новые области исследований, здесь мы оставляем его без комментария.}.
Собственно говоря, соединение двух волокон такого типа уже и есть процессор вполне определенного типа – интерференционный коррелятор, работающий с “матрицами” – волновыми фронтами. И более того, один и тот же решающий элемент может работать и как “чисто аналоговый” и как “чисто цифровой” и во всех промежуточных режимах – в зависимости от того, как установлены пороги по входу и выходу.
Остается только добавить общеизвестный уже факт – структура аксонного волокна на гистологическом срезе в точности та же самая, что и “омигайд”. У “простых” нейронов меньше слоев и “витков” на срезе, у “высоких” нейронов – больше.
Можно с уверенностью утверждать, что в структуре ствола “высокого” нейрона будет классифицировано в точности семь слоев (может быть это уже установлено, но мы просто не имеем возможности следить за всеми результатами еще и в нейрофизиологии).
Несложно подсчитать и некоторые числовые параметры, косвенно подтверждающие гипотезу. Предположим, что реальный нейрон работает на частоте “черного провала”, (т.е. самый нижний уровень – “память собственно данных”), соответственно f ? 1011 гц, что соответствует энергии кванта Е ? 3,9х10-3 эв, а это как раз где-то около разности энергий состояний валентных пар в некоторых белковых молекулах.
С другой стороны, виртуальная машина, построенная в десятислойной однородной среде по рассмотренной раньше схеме и при таком такте памяти должна иметь генеральную тактовую частоту не более 101 гц (если соединить все 1011 нейронов в одну общую решающую виртуальную структуру, то, если нижние работают на 1011 гц, то вся структура будет работать на 10 гц), но и меньшая частота по крайней мере нецелесообразна, т.к. придется вводить специальные “механизмы замедления”. Т.е. имеем генеральную тактовую частоту, соответствующую ?-ритму!
Впрочем, проверить и уточнить экспериментально эти и другие параметры несложно, тем более, когда известно, что и где искать{239. На самом деле фактов, подтверждающих квантово-волновой механизм нейрона гигантское количество, просто они никем всерьез не рассматривались и до сих пор относятся к курьезам, вроде НЛО, вызывания духов и т.п. Так зафиксированы сотни случаев, когда человек воспринимал и запоминал зрительные образы с дискретностью времени меньше 10-3 сек. Существуют школы, где учеников тренируют выполнять захват древка стрелы, выпущенной из боевого лука за заданное место (наконечник, середину, оперение) с точностью до нескольких сантиметров или перехватывать револьверные пули. При скорости стрелы или пули около 250 м/сек это означает выполнение движения за время менее 0,001 сек или моторно-двигательную реакцию в цепочке глаз-мозг-рука менее 0,0001 сек. И предварительный отбор в эти школы проходят отнюдь не уникумы, но достаточно большой процент.
В “электрохимическую теорию” нейрона эти факты вообще никак не уложить. Электрохимическим может быть лишь механизм энергопитания.
“Тактовую частоту” каналов и процессоров можно получить исходя из простейшей прикидки. Если вся цепочка реакции срабатывает за 10-4 сек и процесс обработки проходит три уровня нервной системы (ПНС, СНС, ЦНС) и четыре уровня внутри ЦНС, причем туда-и-обратно, то, исходя из оценок по классическим критериям ТАУ, опять получаем порядок 1011 гц.
Напомним, каждый из семи уровней мы должны рассматривать как систему с жесткой обратной связью, хотя и с переменным управляемым коэффициентом. Чтобы не иметь проблем с устойчивостью, каждый последующий (вложенный) контур ОС должен иметь постоянную времени, по крайней мере, на порядок меньше, т.е. 104х107=1011 гц.}.
Но если это так, то мозг, его структурная схема прямо копируют ту информационную машину, которую мы построили в процессе мысленного эксперимента. Для того, чтобы реализовать копию ее “в металле”, точнее “в омигайде”, требуется только уточнить некоторые конкретные моменты. Приведем наиболее принципиальные.
14.2. Структура команд
Система команд такой машины состоит из следующих типов.
Одна команда копирования (из памяти в обработку и наоборот), имеющая два основных варианта: “расширенное копирование”, с дополнением данных от дополняющей структуры и “суженное копирование”, с усечением данных. Вариантов конкретного выполнения множество, от “полного усечения”, запоминания “только структуры” или выделения ее для “чисто логического” анализа, до “полного расширения”, когда чисто логическая структура достраивается данными “снизу” по умолчанию.
Варианты задаются самой задачей в процессе исполнения установкой порогов “по входам”.
Одна команда сравнения или согласования структур (запомненной, взятой из памяти – суммы всего предыдущего опыта жизни, и текущей, которая является “задачей”). Варианты выполнения: “нижний” – сравнение “только данных”; “верхний” – сравнение “только связей” или “только структур”; “полный”.
Варианты задаются порогами по входам, находящимся выше слоя “собственно данных”.
Две метакоманды интерпретации результата, аналогичные функциям гиперуровня грамматики qWord: соединение двух или более структур и их надстройка; декомпозиция структуры, перекодирование ее как двух разных “полупустых” структур.
И, наконец, одна команда принудительного гашения – точный аналог “самого верхнего тормозящего сигнала” в высоком нейроне (большой пирамиде). По способу устройства машины должны запускаться все структуры данных сразу (вся зона “имеющая отношение к задаче”), если некоторые элементы (нейроны, большие пирамиды) при первом же (или некотором) запуске дают “точное решение”, то все остальные структуры надо просто “погасить”, как не имеющие отношения к делу – они будут только мешать.
Таким образом, имеем всего шесть базовых команд. Однако отметим, что возможно формирование практически неограниченного априори множества “сложных макрокоманд” путем настройки связей на четырех верхних уровнях (запоминания порогов “сервисных нейронов” этих уровней), это будет определять уже “сложную специализацию”, конкретную настройку каждого отдельного экземпляра машины.
Дисциплина распределения памяти. Данные статичны относительно поля памяти, “привязаны” к основанию “высоких нейронов” (микропроцессоров). Выделяются зоны, привязанные к функциям (речевая, зрительная и т.п.), общая решающая зона, по-видимому, также распределяется по характеру задач, но уже не “аппаратно”, а по типу данных и порядку их поступления в процессе обучения (программирования).
Для повышения эффективности логическая зона делится на большие отсеки, половины ориентированные на выполнение команд “верхнего” и “нижнего” варианта и “декомпозиции” и “слияния” (т.е. “образная” и “логическая”, “синтетическая” и “аналитическая” половины).
Но закрепление не жесткое, в случае необходимости положение зон может меняться (например, при выходе из строя части “общего поля”). Полностью динамическими являются лишь связи на четырех верхних уровнях, через “транспортные нейроны”.
Дисциплина обслуживания процессов. Представляет собой расширение дисциплины обслуживания CRR, принятой в qWord. Обозначим ее как ACAR (ALL CRACH – ALL RESET). RESET, а не RESTORE по существу, так как данные в памяти “неподвижны”, система “безадресная” и потому уничтожаются и создаются только связи и только на период решения одной задачи, на самых нижних уровнях связей возможно на период решения цепочки однородных задач.
В зависимости от задачи, запускается одна или несколько “специализированных” или “общих” зон целиком и сразу. Задачи повышенного статуса (типа смертельной опасности) запускают весь ресурс сразу.
“Лишние”, не имеющие отношения к делу структуры “гасятся” практически сразу функцией декомпозиции и командой принудительного гашения, остальные постепенно достраиваются и, наконец, образуют структуру – решение (или структуру – противоречие, например, две эквивалентных, что автоматически означает запуск снова, но с другими порогами отсечки по разным уровням входов, т.е. с другими данными, другой “интерпретацией данных”), либо другой гипотезой – другой постановкой задачи.
Таким образом, общая структурная схема одна для всех без исключения задач. “Текст задачи” – та же структура, т.е. различие между “программой” и “данными” не нужно, собственно “программ” как таковых и нет, есть входные задания, описания задач.
Операционная система (монитор ресурса) просто не нужна – ее полностью заменяет дисциплина ACAR{240. А заодно раз и навсегда для любой ситуации кардинально разрешаются и проблема “уборки мусора” (просто выбрасывается все-по-определению) и “проблема семафоров”, проблема синхронизации процессов!!!}. Драйверы нижнего уровня заданы коммутацией и распределением зон, субдрайверы (безусловные низовые рефлексы) на уровне постоянной коммутации нижних связей данных. Более высокие ранги утилит и мониторов – на уровне полупостоянных и постоянных связей данных. Собственно данные имеют только одно “медленное” движение – загружаются в память при обучении и уходят, стираются дообучением.
Для поддержания баланса деревьев данных (т.е. нижних структур) должен непрерывно функционировать процесс фоновой активности с необходимыми потоками внешних данных или данных – умолчаний, так как при разбалансе деревьев основные команды будут работать неправильно. Дополнительно, в результате этого процесса, происходящего во всех структурах, обеспечивается “многомерный”{241. Опять в смысле некоторой эквивалентной “многомерной модели данных” в “привычной” программистам терминологии; сами структуры данных, их физическое размещение, остается трехмерным.} и непрерывный кэш данных (благодаря перемещению и псевдоперемещению связей) и достигается оптимизация “размещения” данных (хотя сами они относительно поля памяти не движутся).
Более или менее близким аналогом программ, обеспечивающих этот процесс поддержания структуры для адресной (например, фон Неймановской) машины можно считать драйверы (безусловные рефлексы, т.е. аналоги аппаратных микропрограмм), субдрайверы и нижние утилиты (безусловные рефлексы поведения), загружаемые в ПЗУ при начальном формировании операционной системы.
Наконец, машина обладает еще одним фундаментальным свойством, которое уже упоминалось выше. Действует она одновременно и как аналоговая, и как цифровая и как все промежуточные гибридные варианты. Более того, в разных актах запуска одной и той же задачи, одни и те же элементы аппаратуры и “блоки” имеют разное соотношение “аналогового” и “цифрового” представлений.
Перейдем к рассмотрению нескольких возможных вариантов “блок-схемы” вертикальной машины.
Весьма интересно сравнить приведенные на рис. 14.1 три “схемы” элемента информационной машины (или самой машины, что то же самое в силу самоподобия структуры) – “абстрактную”, т.е. построенную логически; “оптическую реализацию”; “живой” высокий нейрон (большую пирамиду).
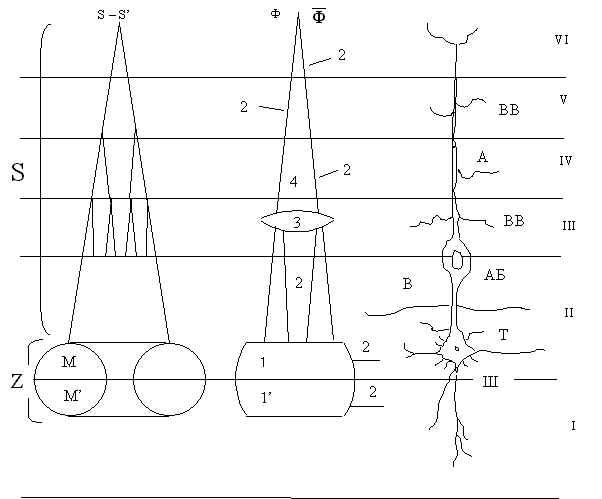
а) абстрактная машина б) оптическая машина в) нейрон
Рис. 14.1. Сравнение “схем” информационных машин
На рис. 14.1 использованы следующие обозначения:
а) абстрактная машина:
Z – зона “зеркала”, трехмерная память для двух трехслойных М-структур данных;
S – структура (метаструктура), S,S’ – “выходы”.
б) оптическая машина:
1, 1’ – трехслойная оптическая (голографическая) память для “запомненной” и “воспринимаемой” структур данных;
2 – пучки “малых” оптических волокон;
3 – “сумматор” волновых фронтов;
4 – “большое волокно” – формирователь структуры – решения;
![]() -
“синфазный” и “парафазный” выходы.
-
“синфазный” и “парафазный” выходы.
с) нейрон:
Т – тело;
Ш – шипиковый механизм;
В – волокна “обучающих” и “рабочих” входов;
АБ – аксонный бугор;
ВВ – волокна “верхних связей”;
А – аксонное волокно.
Дальнейшие подробности, функциональное назначение остальных типов нейронов и других компонентов мозга установить, в принципе, не трудно, даже путем логического анализа, сопоставления логики работы системы в целом и топологии связей элементов.
Возможно даже не потребуется сколько-нибудь значительный объем экспериментов, хотя вся совокупность работ и может оказаться весьма хлопотной, но это уже не имеет принципиального значения.
К тому же в выборе конкретных числовых параметров существует большая свобода – это очевидно из изложенного здесь и имеющегося объема экспериментальных материалов.
Действительно, сопоставим – при абсолютно жестком, одинаковом принципе действия “высокого нейрона” и унитарной общей схеме их соединения, количество входов каждого типа меняется от экземпляра к экземпляру более чем на порядок, то же можно сказать и про соотношение количества входов разного типа (уровня). То есть при абсолютной жесткости принципа устройства наблюдается большая свобода реализации.
Естественно предположить, что в выборе параметров, например порогов, диапазонов их изменения (регулирования) и дискретности регулирования свобода будет еще большая.
Но тогда получается, что все принципиальные вещи относительно конструкции и работы интеллектуальной машины здесь уже сказаны, расписаны и можно прямо приступать к проекту реализации машины – аналога, например, на базе омигайда. Так сказать, браться за отвертку и паяльник. И напротив, - дальнейшие теоретические рассуждения вне конкретного проекта мало что дадут.
14.3. Программирование и запуск
Допустим, что проект реализован, машина построена, остается проблема как ей пользоваться, в частности, как выполнить “программирование” и начальный запуск.
Каждая простая команда “нигде не находится”, она “собирается по вертикали” в процессе ее исполнения из таких компонентов, как правила-умолчания, постоянная и полупостоянная (запоминаемая в состоянии коммутирующих элементов) коммутация; исполняемый в данный момент вариант команды включает в эту сборку еще и значения порогов. Отсюда и принятое нами название – “вертикальная машина”.
Если проводить аналогию с “наиболее близкими” вещами, например, с RISC-процессорами со сверхмалым набором команд, то получается, что каждая элементарная микрокоманда, например, простейшая матрица-сборка, тоже сама “собирается в процессе исполнения”.
Тот кто работал с мультипроцессорными RISC-системами легко может вообразить, в какой кошмар выливается программирование такой аппаратуры. Программирование “напрямую” в такой аппаратуре невозможно даже теоретически, на практике – даже в более простых случаях, там, где элементарные микрокоманды постоянные, применяются устройства – программаторы.
В нашем случае можно сказать абсолютно точно – потребуется целая иерархия устройств и программного обеспечения для того, чтобы совершить акт “сотворения”, создания и запуска первого экземпляра “материнской машины”.
Придется построить комплекс, представляющий собой в функциональном смысле “развертку процесса эволюции” которая и создала прототип{242. Есть еще один способ, на самом деле не такой уж и фантастический. Построить копию “как можно ближе к оригиналу” и скопировать “операционную систему” с “инструментальными оболочками” и “библиотекой опыта” с живого образца. По образу и подобию… О последствиях пока умолчим.} (см. работы А.Колмогорова о моделировании сложных процессов).
В последующие образцы “стартовую генерацию ПО” целесообразно просто копировать. То есть нам придется скопировать не только саму машину – мозг, но и всю технологию его производства в целом. Впрочем, ничего необычного в этом нет – новому устройству должна соответствовать и новая технология.
Но помимо этого придется скопировать и “технологию эксплуатации”, т.е. “интеллектуальную среду”, состоящую из подобных же (существ? машин?) со всеми ее атрибутами, т.е. кодексом правил поведения, общения и т.п. на уровне “не меньше, чем у прототипа”.
Наконец, что делать с проблемой самоидентификации? Известно, что у однояйцовых близнецов таковая существует и очень серьезная. А в нашем случае получится много и абсолютных копий – на уровне неразличимости, независимо от их “профессиональной ориентации”. Что это будет – полисущество? супермуравейник? – пожалуй, ничего, кроме подобного неуклюжего названия, “до того” и не придумаешь.
В целом же оказывается, что проблема “не здесь и не в том”, “расколоть” механизм и принцип действия не так уже и сложно – вопрос в том, что с ним делать{243. Пока целесообразнее всего оставить эту проблему для других исследований и исследователей. Остановить все равно не удастся, да и затраты на первом этапе сравнительно скромные. Только впервые “экономический эффект” считать придется не в денежных единицах и “гуманитарной пользе”, но, может быть, уже даже и не в мегатоннах.
Но если перестать мечтать о “робовладении” и признать себя промежуточной ступенью прогресса, то надо выполнить свою миссию, ради которой Природа пошла на создание экологически вредного вида HS, и спокойно уйти со сцены истории по собственному почину, а не в результате доведения человека Природой и “человладетелями” до состояния Лемовского выгонта.}.
14.4. “Перед прочтением уничтожить…”
Ну а раз остановить все равно не удастся, упомянем еще один момент, представляющий интерес как для теории, так и для экспериментальных и прикладных нужд. Вспомним, что программирование машины начинается еще на этапе монтажа путем копирования структур “материнской” машины к которой подключен вновь создаваемый экземпляр.
Самый нижний уровень (драйверы устройств, нижние утилиты, т.е. основные “безусловные рефлексы”) кодируется на уровне постоянной коммутации. Следующий уровень (субдрайверы, утилиты организации операционной оболочки, т.е. “поведенческие рефлексы”) кодируются еще и настройкой “связных нейронов”, так как они зависят и от “модели” и от конкретного экземпляра, это тонкая, индивидуальная настройка, которая не может быть уже “зашита заранее”.
Для машины И4, “интеллекта”, это еще и критический механизм, который определяет саму возможность дальнейшего, поскольку обеспечивает тонкую балансировку потоков данных в которых только и может возникнуть структура Z , т.е. “зеркало”.
Балансировка должна быть очень точной, буквально с точностью до одной единичной структуры “собственно данных”. В противном случае не будут правильно исполняться основные команды и не сможет не только сформироваться И4, но и правильно не будут функционировать “поведенческие рефлексы” и более сложные программы – “условные рефлексы”.
С другой стороны, система по определению строится для “предельных режимов” на грани разрушения физической структуры и даже для условий, когда такое разрушение происходит (травмы, отравления и т.п. ситуативные воздействия, вызывающие массовую гибель элементов).
Это означает, что после настройки связей второго уровня механизм их изменения должен быть блокирован на самом глубинном уровне, чтобы его повторный запуск был невозможен ни при каких условиях, так как это разрушит основу системы.
Поскольку квантовый механизм памяти реализуется на квантово-молекулярном уровне внутри клетки, то блокировка должна выполняться на уровне генокода путем полного изъятия одного из элементов – только такой ключ дает надежную гарантию. Любая другая система замка неизбежно даст сбой, и, учитывая общее число нейронов всех видов, крах системы будет практически неизбежным и мгновенным.
Теперь – внимание!
Поместим “взрослую” клетку (ее генокод) в естественный инкубатор и вырастим образец “машины”. Первый этап программирования завершится нормально, но второй даже не сможет начаться – клетка то уже “взрослая” и ключ кодировки уже убран.
То есть уровень “поведенческих рефлексов” просто не будет сформирован, не говоря уже о более высоких структурах, для интеллекта не сможет возникнуть даже основа – “фоновый процесс”. Какой бы образец мы ни брали – гения или овечку – получится все равно монстр, мезозойская рептилия.
В точности это самое и продемонстрировала овечка Долли, когда сожрала своих сожительниц по клетке и проделала это не как волк или гиена, а именно так, как и должна поступать рептилия.
Не худо было бы господам клонировщикам этот факт учесть{244. И учтут ведь, только что именно и с каким знаком? Из информодинамики впрямую следует, что из Мира информационного можно натаскать такие вещи, что для нашего Мира физического места во Вселенной-как-целое не останется.}.
Далее было обнаружено, что некоторые параметры, в частности, системное время также “намертво” кодируется в процессе функционирования организма. У знаменитой Долли и двух других овец, клонированных из соматических клеток взрослого животного, обнаружены некоторые структурные нарушения наследственного аппарата.
Теломеры – узелки на кончиках хромосом, которые сокращаются при каждом клеточном делении, у Долли на двадцать процентов короче, чем должно быть при ее трехлетнем возрасте. Это означает, что Долли в определенном смысле является ровесницей своей матери, поскольку возраст ее клеток, оцененный по длине теломер, соответствует девяти годам. Ученые полагают, что этот факт следует принимать во внимание при клонировании тканей и органов для трансплантаций{245. Сообщение появилось 27 мая 1999 г. в английском журнале Nature.}.
Но мы обратим здесь внимание не на технологические проблемы совмещения параметров клонов, а на то, что при рождении организма системный таймер объявляется абсолютным. Это как раз и указывает на то, что системы такого класса являются смертными структурно, а не по причине физического износа носителя (известно огромное количество видов, у которых укорочение теломераз не происходит).
В последнее время открыт и механизм обеспечивающий восстановление длины теломеразы, т.е. он существует в природе. Но если Природа не включила этот механизм восстановления в конструкцию всех видов, начиная с некоторого уровня их сложности то это и означает, что смерть индивида – запрограммирована, значит существует причина для ограничения существования индивида, лежащая вне физиологии и физики.
Возвращаясь к механизму блокировки, можно утверждать, что “вернуть на место” ключ практически невозможно, поскольку это скорее всего не какая-то цепочка молекул, а система связей, причем индивидуальная для каждого отдельного экземпляра и уничтожается она до рождения этого экземпляра.
Так сказать “перед прочтением уничтожить”. Почему именно так?
Согласитесь, что акт творения был – и все встанет на свои места. Да чтобы не в меру любопытные не рукосуйствовали, не лезли, куда не положено. Может быть и так, что для млекопитающих подходит “какой-нибудь” ключ или отмычка. Но в варианте человека мы получим в лучшем случае “психа со всеми свойствами, что бывают и не бывают”. А ведь возможен и не лучший случай. И это если не доказательство, то надежда, что у Природы нет близкой собственной цели ликвидации человека как вида, по крайней мере, таким способом.
Да и вообще Господа, не кажется ли, что уже появилось много различных знаковых признаков и явлений, указывающих на то, что, прежде чем влезать куда-то, не вредно будет задуматься – зачем?
14.5. Что с ней делать?
А пока подумаем, как рационально воспользоваться сведениями об устройстве “интеллектуальной машины”. Начинать надо с поставленного вопроса. Копия, заменитель человека – “ни за чем”, не будем это обсуждать, оставим для любителей подобных споров и праздного любопытства. Все остальное естественно классифицируется в четыре основные группы, имеющие некоторые общие черты и перспективы при использовании для решения их задач вертикальной машины.
1.Распознаватели для радаров, сонаров и т.п., сюда же относятся анализаторы речи, словари-перводчики, системы “технического зрения”, т.е. все, что имеет дело с образами априори заданного конкретного типа и физической природы и преобразованием “образ-образ”, но не с более сложными цепочками и построением логических выводов и решений. Тот факт, что для этих систем используются модели на базе формально-логических выводов, указывает только на то, что для таких отображений существуют эти самые формально-логические модели, но и только. Больше это ничего не означает, не означает и того, что процесс отображения имеет природу формально-логического вывода.
Этот процесс отображения - не теория, но технология.
2.Системы для моделирования математических и логических объектов, т.е. вычислений.
3.Информационные системы, хранилища данных, информации и знания.
4.Системы интеллектуального управления для объектов, где сложность взаимосвязанных объектов и процессов и (или) их скорость слишком велики, чтобы человек мог с этим справиться по своим физиологическим ограничениям.
Для систем типа 1 просто само собой напрашивается копирование структур соответствующих специализированных отделов мозга, например, для “переводчика с голоса” – речевого центра. Тем более, что уже сейчас дешевле и проще сделать “в кристалле” десяток гигабайт, чем пристраивать кабельные соединения и механические дисководы. К тому же технология чипов очень хорошо справляется с изготовлением структур “однородных по слою, но разнородных по слоям”.
Но копирование вовсе не обязательно буквальное, выгоднее и проще согласовать “теоретическую структуру” с возможностями технологии. Тем более, что такой “карманный переводчик” по определению система ограниченная, для общебытового или наоборот, профессионального сленга, так сказать “гибрид Бедекера и тамагочи”.
Для литературного языка, где контекст включает в себя жанр, личность автора, культуру и историческое время “механические переводчики” просто ни за чем не нужны, поскольку не есть ли главная цель и удовольствие от такого чтения – погружение в язык и в этот самый контекст?
Гигантские системы для общения с “мертвыми” или инопланетными цивилизациями скорее всего так и останутся на страницах фантастики не столько потому, что их нельзя сделать в принципе, сколько потому, что это будут системы выдачи “фантастических ляп”, таково проявление в этих случаях “природы цивилизации” - непрерывное смещение контекстов.
Так что снова, что делается, то суть вопрос технологии конструирования, все остальное просто “не надо”.
Что касается систем типа 2, то здесь все зависит от перспектив и направлений развития науки. “Колумбийский суперпроцессор” куда больше пригоден для математического моделирования, чем информационная машина универсального типа, поскольку его топология, топология данных и потоков, моделирующих структур скопированы с топологии “декартова ящика”, в котором и обретаются моделируемые математические сущности.
Когда-нибудь фундаментальная наука и математика в частности, обретут другие структуры и формы, но до этого пока даже фантасты не дошли. Опять, что есть (что будет), то технология, остальное –досужее.
Системы 3 определятся чуть ниже “сами собой” по мере изложения материала.
Про системы типа 4 все, что можно сказать общего уже сказано в разделе про Текрам. Интеллектуальными такие системы быть не могут по определению, поскольку они – распределенные в пространстве, в сети. Правда проблемы, связанные с их объединением, просматриваются на уровне ментагенеза (см. гл. 16), но “глубина прогнозирования” здесь пока слишком велика. Пока можно попытаться обозначить общую концепцию систем такого рода в одном определении. Это концепция “свободно плавающих в сети виртуальных машин”, но при этом “свобода плавания” существенно ограничена функциональной привязкой к объектам обслуживания и условиям баланса потоков обмена.
Это определение страдает всеми ущербностями как, впрочем, и все “строгие определения” систем подобного класса сложности. Опубликованные материалы по другой системе аналогичного класса (Cache’-технология) практически ничего к сказанному в конструктивном смысле не добавляют{246. Секреты реализации не рекламируются и это правильно. Круг фундаментальных принципов крайне ограничен, а применение их сложно и многотрудно, так что если чего и стоит охранять, это то “как сделано”, технологию, а не принципы.
Впрочем, если кто скажет, что секрета нет, это, мол, инженерная реализация интуитивной идеи, согласимся. Но только в том, что технологию можно “делать по науке”, а можно и “просто угадать”. Честь и слава инженерному поиску, когда он успешен.}.
Но в любой такой системе, будь то приложение, разработанное в Cache’ или генерация Текрам для конкретного предприятия, всегда есть центр, совокупность аппаратуры и соответствующая виртуальная машина (эта виртуальная машина может быть “меньше” или “больше” – это существенно – “физического центра”), которая является хранилищем “главного знания” и арбитром “главных решений”.
Т.е. по данному выше определению это система типа 3. Ею мы отдельно и займемся, поскольку получается, что это как раз тот тип системы, которым стоит заниматься.
Но прежде чем приступать к реализации и даже обсуждению таких проектов необходимо зафиксировать следующую ситуацию. Закон самодеструкции самоорганизующихся систем и закон информационной энтропии существуют в Природе и мы не имеем права об этом забывать, “выносить за скобки” этот факт. В прикладном аспекте это означает следующее.
1. Создавая системы, способные к реальному самообучению, самоструктурированию и развитию и технологию эксплуатации таких систем (справедливее даже говорить о “технологии сосуществования” с такими системами), мы должны учесть как один из главных факторов то, что любая конечная негэнтропийная система смертна, имеет ограниченное время существования.
Поэтому выстраивая технологию необходимо обеспечить наследование “собственного опыта системы”, ведь сама постановка вопроса как раз с того и начинается, что система самостоятельно делает в процессе своей жизни нечто нетривиальное и значимое.
2. Закон информационной энтропии говорит нам, что существует множество ненулевой меры ситуаций, когда информационные структуры системы могут одномоментно саморазрушиться от априори непредсказуемого воздействия, т.е. система просто “сойдет с ума”. Естественно задать вопросы – кто будет контролировать такие ситуации и нести ответственность?
Можно, конечно, надеяться на возможность создания и надежность некоторого блока, реализующего “законы робототехники”, только одно дело фантастические романы, и совсем другое – реальная жизнь. В любом случае мы очевидно и напрямую сталкиваемся с проблемами не только выходящими за рамки нашего исследования, но едва ли не за пределы рационального.
Учитывая сказанное, мы не будем здесь обсуждать подобные аспекты, а ниже обсудим только весьма узкий класс систем “более актуальных” в настоящее время, тех, которые до некоторой степени могут иметь “способность к самообучению”, но одновременно программируемы и диагностируемы (наблюдаемы) как традиционные компьютерные системы.
14.6. Имитация вертикальной машины в адресной среде
Рассмотрим концепцию надстройки информационной машины в адресной среде, т.е. в архитектуре традиционного компьютера на базе идеи виртуальной машины, составляющей основную идею qWord. Почему именно qWord? Просто это единственная известная нам (может и вообще единственная) система такого свойства, имеющая и достаточно простую идею и прозрачную реализацию настолько, чтобы на ее базе попытаться объяснить хоть что-то вразумительное. Все остальное достаточно сложно, оснащено дополнительными идеями и условностями и поэтому как исходный материал для концепции представляется просто безнадежным.
Но предупреждаем сразу!
При всей очевидной простоте идеи, даже примитивности, изложить ее в обозримом объеме материала, так, чтобы была ясна концепция в целом весьма сложно.
Приходится только надеяться на заинтересованность читателя и то, что он имеет определенное представление об устройстве и qWord и базовой М-системы (ныне называемой Cache’). Чтобы не редактировать ранее написанный текст сохраним прежнее название в этом разделе как синоним.
Идею или принцип устройства qWord можно изобразить в виде рис. 14.2.
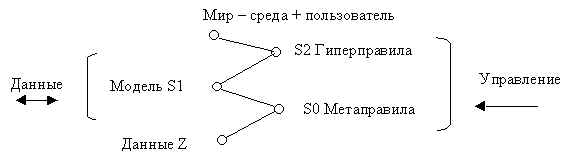
Рис.14.2 Устройство qWord.
Данные Z – совокупность (библиотека, банк данных) структур в М-системе.
S0 метаправила, библиотека программ, порождающих связи между структурами Z; заметим – между структурами, т.е. это “каталог библиотеки”.
S1 – структура модели данных, состояние связей, организующих структуры данных Z в “наблюдаемую модель” в каждом акте обращения к БД путем настройки параметров процедур из S0 и параметров связи между этими процедурами.
S2 – набор структур – гиперправил, обеспечивающих выбор вида модели в зависимости от конкретного акта обращения к БД и параметров обращения.
Рисунок в целом – “мнемоника действия W-грамматики”.
Общение с прикладной системой, созданной в среде qWord, происходит путем навигации в модели (или моделях) S1, которая де-факто является виртуальной, т.е. в каждом акте общения срабатывает конкретная настройка одной из множества моделей, при этом сами структуры данных Z не изменяются, т.е. не перемещаются в памяти ни сами данные, ни связи на уровне Z.
Сама же модель “собирается” согласно гиперправилам S2 в соответствии с запросом, либо “наследуется” по умолчанию от предыдущего сеанса.
Структура Z реализуется в М-системе{247. Строго по определению системы и языка М (В.Кирстен. “От ANS MUMPS к ISO M-технологии”, Изд. СП.АРМ, СПб, 1995).} и, в общем случае, представляет собой некоторое построение (рис. 14.3).
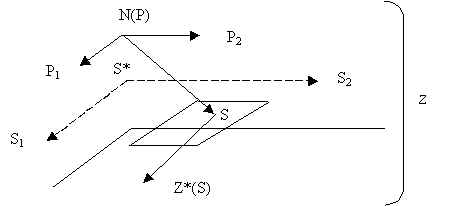
Рис. 14.3. Устройство структуры Z.
Z* (S) – двумерное поле “собственно данных”, физических записей;
S*(S1,S2) – ключ (в общем случае двумерный);
N(P) – имена (обобщенные, зависящие от параметров).
Имя с параметрами задает значение ключа из поля S – поля значений ключей, а данные адресуются уже значениями ключа.
Более сложные структуры надстраиваются по той же схеме.
Обратим внимание, что поле значений ключей – виртуальное, заданы лишь его границы, предельные значения. Количество полей S’ в S* определяется количеством имен N(P), а “позиция” S’ в S* - значением параметров (Р) имени, т.е. способом составления этого имени, но само значение ключа при каждом обращении к данным вычисляется интерпретатором М-системы.
Сам список имен, словарь системы – поле не виртуальное, а реальное, “частичная виртуальность” словаря, т.е. свобода, дающая возможность надстраивать более сложные структуры, задается параметризацией. Таким образом имеется трехслойная, трехуровневая структура, содержащая два уровня данных разного ранга “склеенных” виртуальным (процедурным) слоем, обеспечивающим установление текущего соответствия между данными посредством интерпретации.
Тем самым имеем функционально-полную метаструктуру в определении по ТСС, так (в том же самом виде) как она “самопроизвольно возникает” в любой организованной системе. Структуры S0 (метаправила) и S1 (“модель”) устроены точно так же, поскольку реализованы тоже в М-системе.
Каждая из них представляет собой процедуру (возможно сложную, “собранную” в процессе выполнения), которая “сверху” получает задание (имя с параметризацией, некоторый набор данных) и генерирует “вниз” также набор данных (имен с параметрами).
Эта цепочка интерпретации “заканчивается внизу”, на уровне “собственно данных” и обеспечивает их подстановку в наблюдаемую (в данном сеансе) модель данных. Т.е. прикладная система в qWord представляет собой функционально-полную систему класса И3 (в терминологии ТСС), содержащую три уровня метаструктур стандартного трехслойного типа{248. Вполне заслуженно такие структуры назвать структурами М-типа. Тем самым постановить, что эти структуры являются не только условностью формализма М-языка по определению, например, публикации В.Кирстена, но являются объективно общезначимыми логическими структурами, реалиями самой природы, феномена информации!}.
Отметим важный момент: S0 и S1 – структуры полностью виртуальные в отличие от базовой – Z.
Для каждого акта обращения к БД интерпретируется только один набор параметров S0, т.е. только одна точка в многомерном пространстве интерпретации данных и только одна точка – состояние модели S1 для всего сеанса (или части сеанса).
В целом виртуальной оказывается не только модель данных, но и реализация этой модели. Надо отметить, что эта виртуальность никак не сказывается на утилитарных, прикладных свойствах продукта, выполненного в qWord, если рассматривать его как традиционную, привычную информационную систему баз данных, хотя бы и очень динамичную, способную к существованию в “вечнозеленом” режиме, в режиме непрерывного изменения даже самой модели данных.
Это происходит потому, что и механизм qWord и базовые М-структуры реализованы по строгой логике порождающих грамматик, что гарантирует неразличимость на уровне представления (внешнего) вычисляемых и запоминаемых значений, если это различие не оговорено и не отмечено специально.
То есть основные качества продукта: возможность работы на чисто логическом уровне модели, избавляющая пользователя от необходимости “держать в голове” всю иерархию, механику организации БД и возможность менять или строить модель данных “по ходу работы” совершенно не зависят от “виртуальности реализации” модели.
Но все попытки сделать систему “умнее”, например, реализовать свойство “самоструктурирования”, только привели к убеждению, что “двигаться некуда”, невозможно ее дальнейшее принципиальное усовершенствование.
С другой стороны появилось интуитивное убеждение, что “собственно данные” как бы и ни при чем, структура прикладной ИС определяется только связями.
И в целом, в общем так оно и есть:
Иначе говоря, оставив модель данных виртуальной по идее, надо сделать ее реализацию реальной, т.е. декларативной структурой, или, с другой точки зрения, дать возможность системе “помнить и ощущать самое себя и запоминать свой жизненный опыт” – а иначе “учиться”, “самоорганизовываться” просто не на чем.
Т.е., помимо структур S1 (модели) и S0 (привязки модели к данным), надо создать и поддерживать декларативные М структуры, подобные Z, которые и будут “памятью системы о себе самой”, ее жизненным опытом и материалом для самообучения. Но, что существенно, по иерархии не “над”, а “сбоку”, а, значит, соответственно надо организовать и работу этих структур.
Каждое имя (модели и/или компонента) снабжается набором параметров (имен), являющихся ключами. Значения ключей – значения параметров.
Значения “собственно данных” этого уровня – значения входных параметров для следующего уровня S0. Сам уровень S0 должен быть устроен по тому же принципу.
Далее, аналогично устройству Z (базовой М-структуры), должен быть реализован работающий скрытно, по умолчанию, механизм балансировки (симметризации) деревьев, т.е. структур, запоминающих опыт, “историю жизни”.
Совершенно новый механизм, которого ни в М-системе, ни в qWord явно и автономно нет – механизм “вертикальной навигации”. Механизм этот должен реализовывать следующие задачи (работы):
Разумеется, для этого надо разработать подходящий интерфейс и главная проблема здесь – представление как самих структур, так и их иерархии.
Если говорить о реализации, то, очевидно, что основная проблема и трудность как раз в выработке этого представления, в выборе способов как “изобразить” многомерную модель данных, “модель интерпретации модели данных”, чтобы от этого была реальная польза для пользователя прикладной системы. Можно быть абсолютно уверенным, что работа по разработке такого интерфейса потребует не меньше усилий и затрат, чем потребовалось для реализации концепции, скажем, WINDOWS.
Здесь мы должны приостановить ход рассуждений, чтобы снова задать ключевой вопрос “зачем?” Какую реальную пользу можно извлечь из очень немалых затрат?
На уровне очевидности можно усмотреть только один аспект. Если мы имеем дело с распределенной информационной системой, обслуживающей достаточно сложную, “богатую” модель объекта (или совокупность объектов), то наличие декларативного представления модели, ее интерпретации и их истории позволит вести текущий анализ распределения общего поля данных и связей между его (поля) частями.
А это прямо означает, что можно резко повысить надежность системы и сократить трафик перемещения массивов данных. Из законов структур напрямую следует, что в установившемся режиме около 50% данных оказываются распределенными, привязанными к локализованным подсистемам, общий трафик обменов при этом составит в среднем 1/8 от общего объема данных, т.е. 12,5%. Для сравнения – в сетевой модели данных средний трафик должен составлять более 50%{249. Наверняка в реализации Cache’ как раз эта “многомерная модель” и реализована, но, повторяем, как – неизвестно. Надо заметить, что в эффективности (экономичности) как раз и скрыта главная опасность. Снижать пропускную способность физических каналов до теоретического уровня нельзя, это может привести к разрушению системы. Среднее значение трафика вовсе не гарантирует от возникновения, хотя и редкого, критических потоков того же уровня, что и в полносвязной сети (типа все-со-всеми).}. В остальных же аспектах и в обозримой перспективе польза от этой модели в основном познавательная.
Реализация всей структуры информационной системы класса И3 в декларативном, т.е. в реальном, а не виртуальном виде, создает основу для дальнейшей надстройки “вертикальной машины”.
Пути и средства достаточно хорошо известны, изучены и освоены, остается только разрешить сакраментальные вопросы – “зачем и как этим пользоваться?”.
Надеяться на то, что можно построить информационные системы, работающие в основном за счет “самообучения в процессе” вполне возможно и реально, но это будет уже совсем другая технология информационных систем.
Наличие “дублирующей информационной вертикали” – это возможность прямого программирования системы, т.е. использования знакомых и как-то освоенных технологий. В случае отказа от “процедурной вертикали” надо создавать технологию (в большом, в смысле целого) “выращивания, воспитания и обучения” информационных систем. Кому, когда и зачем это понадобится? Но это вопрос не этой книги.
Дело опять в согласовании структур, которые вместе именуются “сумма технологий”. Повторим снова наше заклинание: что есть, то технология, остальное будет после, когда придет время.
Опять, между реалиями жизни и инженерной реализацией проекта системы, для “фундаментальной аксиоматической теории” не остается места, сам проект, его реализация – он сам для себя и “фундаментальная теория” тоже.
| Site of Information
Technologies Designed by inftech@webservis.ru. |
|