Телемедицина и информационные технологии доступа к БД
Проблема эффективного использования современных достижений медицинских знаний, исходя из их сложности, является актуальной в глобальном масштабе. Это направление науки, объединяющее современные технические знания и научные достижения в медицине, предназначено для широкомасштабного и оперативного удовлетворения медицинских потребностей общества на высоком уровне.
В настоящее время достижения электронной техники уже широко используются в медицине. Но в основном это использование носит локальный характер и преимущественно касается диагностики в стационарных условиях на пациенте.
Так, например, широко известны рентгенологические аппараты, приборы электрокардиологического, ультразвукового и энцефолографического исследования и др.
Бурно развивается и применение технических терапевтических средств, таких как излучатели тепловых, световых и ультразвуковых волн и массажёров. В хирургии всё шире используют лазерные скальпели, автоматические агрегаты поддержки функционирования отдельных органов и т.п.
Однако, наряду с огромными достижениями медицины и высокой квалификацией врачей, ощущается разительная нехватка высококвалифицированного персонала как внутри некоторых районов мегаполисов и, тем более, в отдалённых от больших городов селениях и других населённых объектов, таких как вахтовые посёлки, суда морского флота, экспедиции, арктические и антарктические станции и т.п. Это же касается даже целых развивающихся стран.
Эта проблема как раз и может решаться ТЕЛЕМЕДИЦИНОЙ. Под телемедициной понимается совокупность средств обеспечения на дальних расстояниях, в том числе в глобальном масштабе, медицинской информацией любого объекта, снабжённого компьютерной техникой.
Для решения этой задачи все технические средства имеются.
Дальняя связь (телесвязь) обеспечена современными спутниковыми системами радиосвязи, наземными каналами оптоэлектронной и проводной связи на достаточно высоком техническом уровне.
Сбор, обработка, хранение данных и отображение информации также обеспечивается современными компьютерными системами.
В качестве приёмо-передающей системы может служить глобальная международная информационная сеть INTERNET.
Однако медицинскому аспекту решения информационных проблем пока уделяется недостаточно внимания.
Наличие технических средств является недостаточным фактором для решения поставленной задачи.
Нерешённость задачи проявляется в отсутствии необходимых баз хранения медицинских знаний на уровне программного обеспечения. Для создания приемлемых баз данных требуется провести классификацию информационных проблем с точки зрения потребностей медицины.
Так, например, могут быть поставлены следующие задачи:
Такой список можно продолжить и далее.
Очевидно, что для более корректной и оптимальной классификации необходимо активное участие специалистов медиков общей медицины и узких специализаций.
Для решения таких широких по объему задач и сложных по сути отдельных направлений медицины, с точки зрения базы хранения и представления информации, можно воспользоваться постреляционной СУБД – Cache, которая имеет все необходимые средства для решения поставленных задач. В этой системе имеется:
Этот список можно продолжить и далее.
В основе концепции Cache лежит принцип многомерного представления данных. Сегодня на рынке доступен ряд коммерческих серверов многомерных БД. Некоторые продукты (такие, как Cache) хранят данные в истинно многомерных БД, другие выгружают данные из реляционных БД в статические многомерные модели, третьи обращаются к реляционным данным, используя виртуальное многомерное представление, с которым и работает пользователь. К статической или виртуальной многомерной модели можно отнести продукты фирм Oracle, Informix, Sybase, Computer Associates, Microsoft и др., которые предлагают покупателям системы, позволяющие хранить многомерные структуры данных, однако их ядра подобны имеющимся у реляционных БД.
Таким образом, данные в БД - Cache хранятся в многомерных массивах данных (в структурах, аналогичных тем, которые существуют в реальном мире), вместо множества двумерных таблиц, как в реляционных БД. И пользователь работает напрямую с многомерной моделью (доступ, изменение или поиск данных), что увеличивает производительность системы по отношению к реляционным базам в несколько раз.
С целью дальнейшего повышения производительности обработки транзакций, в БД Cache реализована концепция «разреженных массивов». Пространство базы данных занято лишь реальными данными - пустые данные не занимают места вообще. Эта действительно «лаконичная» технология базы данных повышает производительность и масштабируемость, сокращая число операций чтения/записи.
Быстрый доступ к данным при многомерной модели делает ее естественной для обработки транзакций, которая требует частого изменения маленьких кусочков БД. Так как Cache состоит из n-мерных массивов, то для приложения становится просто найти, заблокировать и изменить только те данные, которые требуются для транзакции. Внутренние механизмы обработки данных приложения не тратят время для доступа к многочисленным таблицам или блокировки целых страниц данных при поиске нужной информации. Таким образом, индивидуальные транзакции работают быстрее, и большее число транзакций может быть запущено параллельно.
Унифицированная структура данных позволяет осуществлять доступ к постреляционной базе данных Cache через объекты, SQL или напрямую без необходимости применения какого-либо "перевода" или "отображения". При обработке многомерных массивов постреляционной СУБД, называемых глобалями и являющихся единицами хранения данных, используется встроенный язык Cache Script для описания прямого доступа к последним. А язык запросов Cache SQL вместе со словарем данных позволяет создавать реляционные таблицы для сохранения данных.
Нет необходимости говорить, насколько широкое распространение получила в последнее время идеология объектов. Термин «объект» означает комбинацию данных и программ, представляющих некоторую сущность реального мира. Данные состоят из компонентов произвольного типа, называемых атрибутами. Каждая программа называется методом. Пользователи не могут увидеть, что у объекта внутри, но могут им пользоваться, обращаясь к его программной части. Это немногим отличается от обычного вызова процедуры, когда пользователи обращаются к ней, подставляя значения входных параметров и получая результаты в виде выходных параметров.
Практика показывает, что наиболее распространенная сегодня реляционная технология мало пригодна для работы со сложными объектами. Бартельс, пионер в области объектно-ориентированного программирования в Германии, в нескольких обзорных статьях приводит чрезвычайно удачное сравнение: «едва ли кому-нибудь придет в голову идея разобрать свой автомобиль (как пример сложного объекта), прежде чем поместить его в гараж (база данных), на отдельные детали (записи, поля), разложить их там, а на следующее утро в обратном порядке снова собрать свою машину».
Объектно-ориентированный подход – это возможность работать со сложноструктурированными данными и попытка преодолеть ограничения, связанные с использованием реляционной технологии СУБД. Реляционные БД вынуждают пользователей представлять иерархические данные в терминах кортежей многих отношений. А для выборки данных, разбросанных таким образом по многим отношениям, реляционная БД должна выполнять дорогостоящие операции соединения. Иерархические данные в объектно-ориентированных языках естественным образом представляются благодаря тому, что значение атрибута объекта, в свою очередь, может быть объектом.
Объектная надстройка Cache по существу является макроуровнем языка Cache Script. Такие свойства объектов, как наследование (в том числе множественное), полиморфизм и инкапсуляция реализуются Cache на собственных средствах, а словарь классов объектов позволяет создавать информационные системы различной степени сложности. Глобали БД хранят информацию о значениях свойств и параметрах, характеризующих их поведение, а сами методы работы с данными реализуются на языках Cache Script, Cache SQL и Cache ScriptObject, причем последний включает команды манипулирования объектами. Кроме того, Cache взаимодействует с широким набором различных инструментов разработки и разнообразными языками. Для объектов это включает доступ при помощи ActiveX (COM), Java, C++, и Web.
Принимая во внимание достоинства объектно-ориентированного подхода, не следует упускать из виду то, что реляционная технология обладает важными преимуществами, – теоретическая обоснованность и подкрепленность стандартами.
Часто можно услышать что, большинство объектно-ориентированных БД страдает от недостатка средств запросов. Обычно не предусматриваются вложенные подзапросы, операции над множествами (объединение, пересечение, разность), функции агрегирования и группировки и т.д. - средства, полностью поддерживаемые в реляционных БД. Другими словами, эти продукты позволяют создать гибкую схему базы данных и наполнить ее объектами, но они не предоставляют достаточно мощных средств извлечения объектов из базы данных для совместного с другими пользователями доступа к ним некоторым контролируемым образом.
Нужно отметить что, эти утверждения никак не касаются системы Cache. Используя архитектуру унифицированных данных, объекты Cache автоматически становятся доступными через реляционные таблицы. А это дает возможность использования целого ряда средств разработки запросов, составления отчетов, которые являются результатом популярности реляционных баз данных. Таким образом, система может осуществлять как реляционный, так и объектный доступ к базам данных.
Высокопроизводительный драйвер для использования со стандартом ODBC (Open Database Connectivity), дает возможность Cache иметь два принципиальных преимущества:
Особое внимание в системе Cache нужно уделить продукту WebLink, который позволяет присоединить мощную Cache базу к World Wide Web. В основе WWW лежит принцип распределенной гипермедийной информации. Технология WWW может сочетать в одном документе разнообразные формы представления информации – тексты, звук, графику и т.п. Документы, построенные на основе этих форм, будут доступны по всей глобальной сети Internet. А так как большая часть информации представлена в виде тех или иных БД, то такие формы позволяют строить интерфейсы между WWW и БД.
WebLink позволяет, в среде Internet, подключиться к Cache базе тысячам пользователям. Многие БД не рассчитаны на такое мощное информационное давление и могут быть разрушены. БД, построенные в Cache и использующие Cache WebLink, способны работать с любыми потоками информации. Даже, если техническое обеспечение сравнительно слабо, эта система будет работать полноценно, обслуживая параллельно большое количество пользователей.
Существует, в общем, два класса механизма доступа к БД:
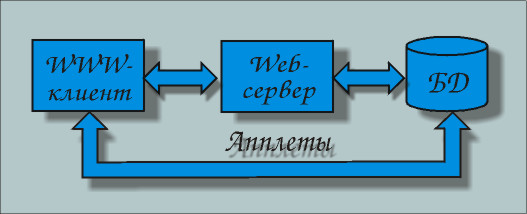
Для обеспечения доступа к базам данных на стороне Web-клиента (рис. 1) используются языки Java, JavaScript, VBScript и др. Одно из важных свойств этих языков – это мобильность, которая заключается в том, что написанный код может использоваться на любой платформе.
Написанные программы (апплеты), на основе этих языков, компилируются в мобильные коды и соответствующие ссылки на определённые коды этих программ ставятся в HTML-документе. Броузер, работающий с таким документом (со ссылками на апплеты) запрашивает у Web-сервера все мобильные коды. Коды могут начать выполняться сразу после размещения в компьютере клиента или быть активизированы с помощью специальных команд. Такие апплеты могут быть специализированы для работы с БД.
Рис.1
Ещё одно важно свойство этих языков – это то, что их код является частью HTML документа. Следовательно, для включения нового апплета в вашу Web-систему нужно перекомпоновать HTML-документ, а не Web-сервер.
К одному из важнейших недостатков Java, JavaScript и VBScript технологий нужно отнести невысокое быстродействие выполнения кода. Т.к. апплет не является откомпилированной программой, то его исполнение проходит через интерпретатор.
Рассмотрим общий механизм стандартного доступа к БД на стороне сервера: используются внешние по отношению к серверу Web-программы, взаимодействие которых происходит через специфицированный протокол CGI (Common Gateway Interface) или API (Application Program Interface) или FastCGI.
Общая схема реализации доступа к базе данных с использованием CGI выглядит следующим образом (рис.2): клиент, находясь на странице содержащую одну или несколько форм, предназначенных для запроса из базы данных - данных или ввода данных, заполняет их и отправляет заполненную форму на Web-сервер. Получив заполненную форму, сервер запускает соответствующую внешнюю программу, передавая ей параметры и получая результаты на основе протокола CGI. Внешняя программа преобразовывает этот запрос на язык понятный серверу БД, взаимодействует с ним и после получения результатов запроса формирует соответствующую HTML-страницу и передает ее Web-серверу, завершая свою работу. Web-сервер передает сформированную HTML-страницу клиенту, и на этом процедура доступа к базе данных завершается.
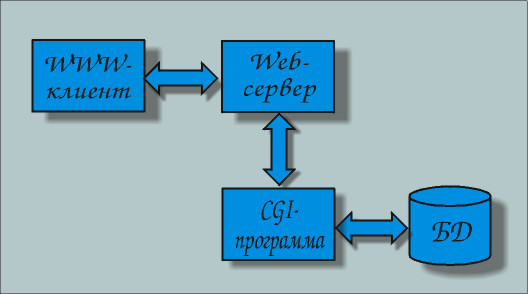
Рис.2
При применении спецификации CGI для обмена данными с внешними программами можно выделить следующие преимущества: возможность работать на любом сервере, не привязанность к конкретному языку программирования, порождение отдельных процессов при запуске CGI-программы и др.
Так же есть и недостатки: так как на сервере для каждого запроса порождается новый процесс, который по окончанию работы завершается, то это приводит к невысокому быстродействию CGI-программы и снижает эффективность работы сервера.
Некоторые недостатки спецификации CGI были оптимизированы в спецификациях API. API запускается, как динамическая библиотека на Web-сервере и выполняет обработку каждого вызова сервера по отдельной структуре памяти, что значительно проще, чем создание отдельного процесса для каждого клиентского запроса. Работа через API происходит на много быстрей чем через CGI. Это объясняется тем, что API, выполняясь в основном процессе сервера, постоянно находится в состоянии ожидания запросов, поэтому время на запуск программы и порождения нового процесса не требуется.
Несмотря на достоинства спецификации API она обладает и рядом существенных недостатков: нет возможности работать на любом сервере, привязанность к конкретному языку программирования, неизолированность процесса и др.
Наилучшие свойства двух рассмотренных спецификаций были интегрированы в интерфейс FastCGI. Приложения FastCGI, как и CGI запускаются отдельными процессами. Но отличие заключается в том, что процессы FastCGI являются постоянно работающими и после выполнения запроса не завершаются, а ожидают новых запросов. В данной спецификации можно выделить следующие достоинства: непривязанность к конкретному языку программирования, изолированность процесса, высокое быстродействие - за счёт постоянно функционирующих процессов и др.
WebLink осуществляет доступ к БД на стороне сервера.
Применение CGI позволяет иметь на стороне клиента только сравнительно простые программы просмотра, что приводит к снижению эффективности работы динамических Web-страниц (эта технология позволяет поставлять пользователям информацию, исходя из их нужд). Для преодоления этого препятствия можно использовать WebLink. Он представляет собой высокоэффективную альтернативу CGI благодаря использованию встроенного API Microsoft Information Server (ISAPI). Связь между Web-сервером и Cache-базой осуществляется через множество параллельно существующих TCP/IP соединений (рис. 3). Будучи привязанными к одной или нескольким Cache-базам, эти соединения предоставляют набор доступных каналов, которые могут быть быстро использованы при непредсказуемом уровне загрузки Web-сервера. Как было показано выше, в стандартной модели взаимодействия, пользовательский броузер общается с процессом на другом конце соединения через Web-сервер, обычно через какую-либо разновидность CGI-протокола. WebLink же использует фоновый процесс на Cache-сервере для приёма поступающих запросов и запуска серверных процессов, обрабатывающих эти запросы. Параметры запросов, приходящие от броузера разбираются и делаются доступными для Cache-программ через локальный массив. Вызываемая Cache-программа анализирует этот массив, генерирует выходной HTML-документ и выводит его на текущее устройство.

Рис.3
Производительность WebLink-а существенно увеличивается при использовании уникального продукта фирмы InterSystems – Протокола Распределённого Кэша. Уникальный протокол кэширования Cache повышает производительность и масштабируемость за счет значительного сокращения сетевого трафика. Полезные данные кэшируются локально на клиенте, что ведет к более быстрой транзакции. И так как клиенты посылают через сеть только отдельные запросы, любая данная сеть может обслужить значительно больше клиентов.
Возвращаясь к WebLink-у, отметим, что он может работать на любой платформе, такой как Windows и Unix, и в любом стандартном броузере, таком как Netscape Navigator и Internet Explorer. Он использует популярный протокол передачи данных – TCP/IP, обладающий высокой производительностью и не требующий конкретных аппаратных средств. А масштабируемая plug-and-play архитектура этого продукта даёт возможность работать с ней, как маленьким, так и большим, многогигабайтным базам данных.
Для осуществления доступа к БД Cache из WWW можно использовать любые механизмы доступа к БД – Java, CGI, API, FastCGI или WebLink.
Таким образом, в настоящее время становится ясно, что задача создания эффективно действующей телемедицины является вполне реальной.
Это утверждение можно считать корректным и, как было показано выше, практически имеется электронная база в виде современных компьютеров, средства дальней связи, в виде спутниковой связи и наземных проводных устройств, и соответствующие информационные технологии, также имеются.
Наиболее важными и актуальными задачами является классификация медицинских знаний, в приемлемой для программирования форме, и создание системы управления базами медицинских данных, а также общая координация процесса решения поставленной задачи.
| Site of Information
Technologies Designed by inftech@webservis.ru. |
|