Каталог >> Базы Данных >> Data Mining >> Осколки знаний |
Осколки знаний
В.А.
ДюкДвижущей силой современного информационного общества являются знания – интеллектуально-информационный ресурс (ИИР). Развитие ИИР обеспечивает ускоренный рост научного потенциала и совершенствование производства посредством оперативного получения и тиражирования полезных научно-технических решений на все множество потенциальных потребителей. Общество, базирующееся на информационной экономике, избегает большинства социально-экономических и экологических проблем, и в потенциале предполагает экспоненциальное развитие по всем основным параметрам ("знания порождают знания").
Выделяют три стратегии получения знаний – приобретение знаний, извлечение знаний и обнаружение знаний в базах данных:
Под приобретением
(acquisition) знаний понимают способ автоматизированного наполнения базы знаний посредством диалога эксперта и специальной программы.Извлечением
(elicitation) знаний называют процедуру взаимодействия инженера по знаниям с источником знаний (экспертом, специальной литературой и др.) без использований вычислительной техники.Термином “обнаружение знаний в базах данных
” (knowledge discovery in databases – KDD) сегодня обозначают процесс получения из “сырых” данных новой, потенциально полезной информации о предметной области. Этот процесс включает несколько этапов (рис. 1). Сюда относится накопление сырых данных, отбор, подготовка, преобразование данных, поиск закономерностей в данных, оценка, обобщение и структурирование найденных закономерностей.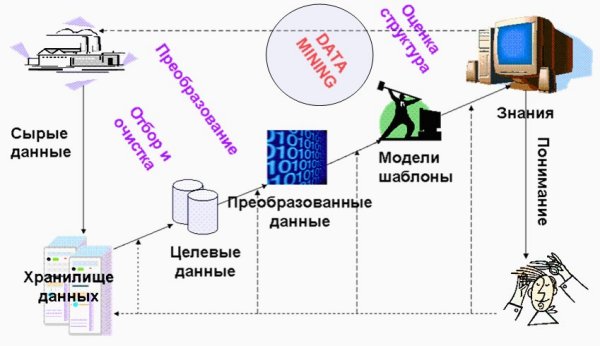
Рисунок
1. Процесс обнаружения знаний в БДСтратегия
KDD все более выдвигается на первую роль. Это во многом обусловлено быстрым развитием разнообразных хранилищ данных (data warehouse) – собраний данных, отличающихся предметной ориентированностью, интегрированностью, поддержкой хронологии, неизменяемостью, и предназначенных для последующей аналитической обработки.Специфика современных требований к обработке данных с целью обнаружения знаний следующая:
Основные аналитические инструменты, удовлетворяющие перечисленным требованиям, сегодня относят к области технологий
Data Mining (раскопки данных). В основу этих технологий положена концепция шаблонов (паттернов) и зависимостей, отражающих многоаспектные взаимоотношения в данных. Поиск паттернов производится автоматическими методами, не ограниченными рамками априорных предположений о структуре выборки и виде распределений значений анализируемых показателей.Важное положение
Data Mining – нетривиальность разыскиваемых паттернов. Это означает, что они должны отражать неочевидные, неожиданные (unexpected) регулярности в данных, составляющие так называемые скрытые знания (hidden knowledge). Многие специалисты осознали, что для выявления закономерностей в реальных жизненных явлениях нужен особенный аналитический инструментарий, соответствующий их системной сложности. В свою очередь, к обществу пришло понимание, что “сырые” данные содержат глубинный пласт знаний, при грамотной раскопке которого могут быть обнаружены настоящие самородки.Системы
Data Mining применяются по двум основным направлениям: 1) как массовый продукт для бизнес-приложений; 2) как инструменты для проведения уникальных исследований (генетика, химия, медицина и пр.). Количество инсталляций массовых продуктов, судя по имеющимся сведениям, достигает десятков тысяч. Лидеры Data Mining связывают будущее этих систем с использованием их в качестве интеллектуальных приложений, встроенных в корпоративные хранилища данных (см. например Дюк В.А., Самойленко А.П. Data Mining: учебный курс – СПб: “Питер”, 2001. – 368 с.).Термин
Data Mining, появившийся в 1978 г., оказался удачным и приобрел высокую популярность в современной трактовке примерно с первой половины 90-х годов. Поэтому вполне понятным оказалось стремление разработчиков аналитических приложений, реализующих самые различные методы и подходы, отнести себя к данной категории. Вместе с тем, это не всегда обоснованно.Например, методы традиционной математической статистики, составляющие основу статистических пакетов, полезны главным образом для проверки заранее сформулированных гипотез (
verification-driven data mining) и для “грубого” разведочного анализа, составляющего основу оперативной аналитической обработки данных (online analytical processing, OLAP). Главная причина ограниченной эффективности большинства процедур для выявления взаимосвязей в данных, входящих в состав статистических пакетов, – концепция усреднения по выборке, приводящая к операциям над несуществующими величинами (например, средняя температура пациентов по больнице, средняя высота дома на улице, состоящей из дворцов и лачуг и т.п.). Так называемые “многомерные методы” типа дискриминантного, факторного и других подобных видов анализа приходят к конечному результату через операции над фиктивными векторами средних значений, а также ковариационными и корреляционными матрицами. Поэтому, их результаты нередко неточны, грешат подгонкой и отсутствием смысла.Программные продукты, реализующие нейросетевой подход, также нередко относят к категории
Data Mining. Основной недостаток классической нейросетевой парадигмы заключается в том, что нейронная сеть представляет собой “серый” ящик. Во-первых, топология нейросетей здесь задается исходя из эвристических соображений. И, во-вторых, в натренированных нейросетях со сложной топологией веса сотен и тысяч межнейронных связей не поддаются анализу и интерпретации человеком.Подход, связанный с разработкой так называемых самоорганизующихся (растущих или эволюционирующих) булевых нейросетей, структура которых поддается расшифровке в виде логических высказываний, соответствует целям и задачам
Data Mining, но страдает недостатками, в целом присущими эволюционным алгоритмам (они будут охарактеризованы ниже).Идея систем рассуждений на основе аналогичных случаев
(case based reasoning – CBR) на первый взгляд крайне проста. Для того чтобы сделать прогноз на будущее или выбрать правильное решение, эти системы находят в прошлом близкие аналоги наличной ситуации и выбирают тот же ответ, который был для них правильным. Поэтому этот метод еще называют методом “ближайшего соседа” (nearest neighbour). В последнее время распространение получил также термин “memory based reasoning”, который акцентирует внимание, что решение принимается на основании всей информации, накопленной в памяти.Системы CBR показывают неплохие формальные результаты в самых разнообразных задачах. Главным их минусом считают то, что они вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт, — в выборе решения они основываются на всем массиве доступных исторических данных, поэтому невозможно сказать, на основе каких конкретно факторов CBR системы строят свои ответы. Другой, более серьезный минус заключается в произволе, который допускают системы CBR при выборе меры “близости”. От этой меры самым решительным образом зависит объем множества прецедентов, которые нужно хранить в памяти для достижения удовлетворительной классификации или прогноза. Кроме того, безосновательным выглядит распространение общей меры близости на выборку данных в целом.
В наибольшей мере требованиям
Data Mining удовлетворяют методы поиска логических закономерностей в данных. Их результаты, чаще всего выражаются в виде IF-THEN1 и WHEN-ALSO правил. С помощью таких правил решаются задачи прогнозирования, классификации, распознавания образов, сегментации БД, извлечения из данных “скрытых” знаний, интерпретации данных, установления ассоциаций в БД и др. Логические методы работают в условиях разнородной информации. Их результаты эффективны и прозрачны для восприятия.Кратко охарактеризуем подходы, которые применяются для поиска логических правил в данных. При этом сконцентрируем внимание на проблемах, требующих своего решения. Для иллюстрации возникающих проблем воспользуемся двумя тестовыми задачами.
Тесты
ТЕСТ 1 – “Умение решать простейшие задачи”
Для поиска логических закономерностей предлагается таблица данных, содержащая 100 объектов (строк) и 2 количественных признака (столбца) Х1, Х2. Таблица разделена ровно пополам на два класса объектов. Распределение объектов на плоскости двух признаков Х1 и Х2 приведено на рис. 2. Объекты 1-класса обозначены крестиком, а объекты второго класса – ноликом.
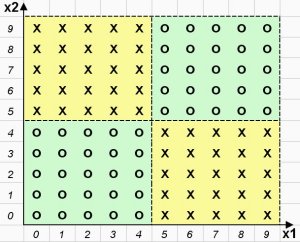
Рисунок
2. Распределение объектов на плоскости анализируемых признаковРешение представленной тестовой задачи очевидно. Каждый класс описывается двумя логическими правилами (всего 4 правила):
IF (X1 >
4) и (X2 < 5) THEN Класс 1 – крестикиIF (X1 <
5) и (X2 > 4) THEN Класс 1 – крестикиIF (X1 <
5) и (X2 < 5) THEN Класс 2 – ноликиIF (X1 >
4) и (X2 > 4) THEN Класс 2 – ноликиКак мы увидим, этот простейший тест окажется “неподъемным” для многих известных коммерческих алгоритмов поиска логических закономерностей в данных.
ТЕСТ 2 – “Умение находить наиболее полные и точные правила”
Принцип формирования этого и подобных тестов следующий.
Матрица объект-признак размера
N? p (N – число объектов, р – количество признаков) заполняется нулями и единицами (или любыми другими символами) со случайным равномерным распределением. В этой матрице выбираются участки строк различной длины (комбинации значений признаков), каждый из которых дублируется в матрице определенное число раз строго по вертикали. Тем самым создаются подгруппы объектов, для которых известно логическое правило, описывающее их полностью со 100 % точностью. Наборы подгрупп объединяются в классы, подлежащие распознаванию. Для большей чистоты эксперимента столбцы и строки общей матрицы переупорядочиваются случайным образом. Ставится задача найти в матрице данных введенные известные правила.В конкретном тесте 2 таблица данных имеет следующие характеристики: количество объектов 400 (из них 100 объектов принадлежит 1 классу и 100 – второму, 200 объектов – случайным образом распределенные значения), 100 бинарных признаков, принимающих значения А или В
. Требуется найти 4 известных логических правила, по 2 правила на каждый класс. Эти правила представляют собой комбинации от 7 до 15 элементарных логических событий. Фрагмент таблицы данных приведен на рис. 3.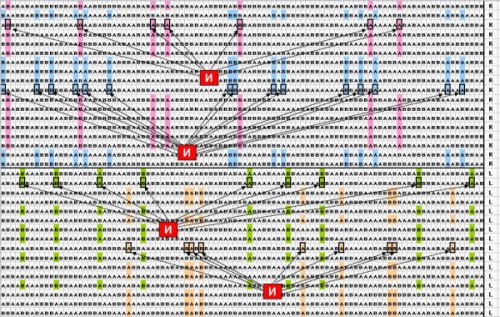
Рисунок
3. Небольшой фрагмент бинарных тестовых данныхЗадача теста 2 далеко не самая трудная из встречающихся на практике. 100 бинарных признаков появляются в анализе, например, когда мы имеем дело всего с 10 исходными количественными признаками, которые при поиске логических закономерностей разбиваются на 10 интервалов каждый. Реальные задачи нередко содержат сотни и даже тысячи количественных, порядковых и категориальных признаков
, а логические закономерности могут представлять собой комбинации из десятков и сотен элементарных событий. Если какая-либо система “не умеет” находить правила неограниченной сложности, покрывающие максимально возможные количества объектов собственного класса, то аналитик рискует утонуть в море “обрывков” логических правил.Ниже мы остановимся на наиболее рекламируемых подходах в
Data Mining, предъявим соответствующим алгоритмам тестовые задачи, и, если потребуется, вскроем причины их неудовлетворительного функционирования.Деревья решений
Деревья решений (
decision trees) являются самым распространенным в настоящее время подходом к выявлению и изображению логических закономерностей в данных. Видные представители этого подхода – процедуры CHAID (chi square automatic interaction detection), CART (classification and regression trees) и ID3 (Interactive Dichotomizer – интерактивный дихотомайзер). Рассмотрим более подробно процесс построения деревьев решений на примере системы ID3.В основе системы ID3 лежит алгоритм CLS. Этот алгоритм циклически разбивает обучающие примеры (записи БД) на классы в соответствии с переменной (полем), имеющей наибольшую классифицирующую силу. Каждое подмножество примеров, выделяемое такой переменной, вновь разбивается на классы с использованием следующей переменной с наибольшей классифицирующей способностью и т. д. Разбиение заканчивается, когда в подмножестве оказываются объекты лишь одного класса. В ходе процесса образуется дерево решений. Пути движения по этому дереву с верхнего уровня на самые нижние определяют логические правила в виде цепочек конъюнкций.
Подавляющее большинство современных аналитических приложений в классе
Data Mining используют алгоритмы построения деревьев решений. Одними из наиболее известных систем являются See5/С5.0 (RuleQuest, Австралия), Darwin Tree (Thinking Machine Corporation, США), Clementine (Integral Solutions, Великобритания), SIPINA (University of Lyon, Франция), IDIS (Information Discovery, США), KnowledgeSeeker (ANGOSS, Канада), AnswerTree (SPSS). Разработчики таких систем, отличающихся незначительными и несущественными вариациями на тему статистических критериев ветвления и подрезания (pruning) деревьев, не скупятся на рекламирование их “превосходных” аналитических свойств, делая акцент на наглядности и понятности получаемых решений.Вместе с тем, эти аналитические свойства весьма далеки от совершенства. Алгоритмы построения деревьев решений реализуют наивный принцип последовательного поиска “наилучших” признаков и создают лишь иллюзию индуктивного логического вывода. Они в ряде случаев не способны решать даже простейшие задачи и, как правило, “цепляют” только кусочки настоящих логических закономерностей в данных.
Так, тест 1 оказывается “непроходимым” для алгоритмов построения деревьев решений. Признаки Х1 и Х2, рассматриваемые по отдельности, не обладают способностью отделить крестики от ноликов. Поэтому уже на первом шаге определения “наилучшего” признака эти алгоритмы единодушно отказываются от нахождения какого
-либо логического правила.Результат решения теста 2 с помощью системы
AnswerTree v. 2.1 (SPSS) приведен на рис. 4. Распознаваемые классы обозначены буквами L и К, 100 анализируемых признаков обозначены а1,…, а100, каждый признак может принимать два значения – А и В. Тест упрощен – из матрицы данных исключено 200 случайным образом сгенерированных объектов.Как следует из рисунка, система
AnswerTree нашла 7 правил. Они располагаются на концах веток построенного дерева и обведены красным цветом. При этом только два правила можно считать более или менее удовлетворительными по точности и полноте охвата объектов собственного класса. Так, правило № 2IF
(а62=В) и (а72=А) THEN класс Lсо 100 % точностью покрывает 39 из 100 объектов (строк) класса
L. В свою очередь, правило № 7IF
(а62=А) и (а89=А) и (а84=В) и (а91=В) THEN класс Котносит 57 объектов к классу К с одной ошибкой. Таким образом, в целом тест 2 остался нерешенным. Система не сумела найти 4 известных экзаменатору правила, которые покрывают все объекты распознаваемых классов со 100 % точностью. Аналогично с данным тестом не справляются другие системы, реализующие те или иные алгоритмы построения деревьев решений.
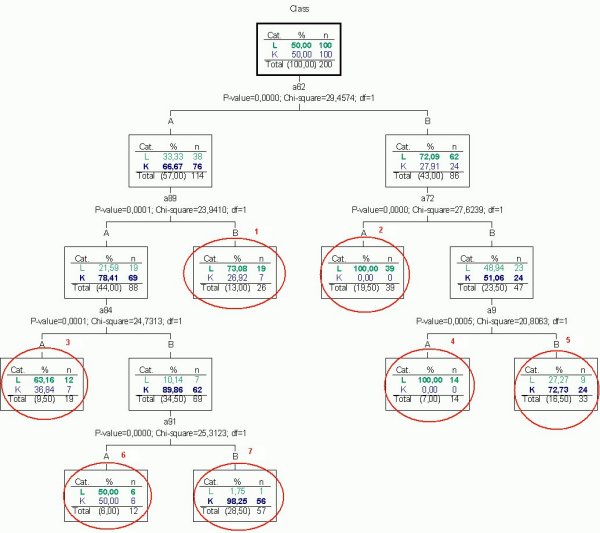
Рисунок
4. Дерево решений, построенное системой AnswerTree по данным теста 2Для справедливости следует отметить, что рассмотренные системы действительно функционируют с рекламируемой разработчиками высокой скоростью, имеют удобный интерфейс, развитые средства манипулирования исходными данными и т.п. Но перечисленные свойства, по-видимому, теряют свою привлекательность, когда мы начинаем вникать в принципиальные ограничения используемого аналитического подхода.
Алгоритмы ограниченного перебора
Алгоритмы ограниченного перебора были предложены в середине 60-х годов М.М. Бонгардом для поиска логических закономерностей в данных. С тех пор они продемонстрировали свою эффективность при решении множества задач из самых различных областей.
Эти алгоритмы вычисляют частоты комбинаций простых логических событий в подгруппах (классах) данных. Примеры простых логических событий: X = C
1; X < C2; X > C3; C4 < X < C5 и др., где X – какой либо параметр (поле), Ci – константы. Ограничением служит длина комбинации простых логических событий (у М. Бонгарда она была равна 3). На основании сравнения вычисленных частот в различных подгруппах данных делается заключение о полезности той или иной комбинации для установления ассоциации в данных, для классификации, прогнозирования и пр.Система WizWhy предприятия WizSoft (http://www.wizsoft.com) является современным представителем подхода, реализующего ограниченный перебор. Хотя разработчики системы не раскрывают специфику алгоритма, положенного в основу работы WizWhy, вывод о наличии здесь ограниченного перебора был сделан по результатам тщательного тестирования системы (изучались результаты, зависимости времени их получения от числа анализируемых параметров и др.). По-видимому, в WizWhy ограниченный перебор используется в модифицированном варианте с применением дополнительного алгоритма “
Apriori”, заранее исключающего из анализа элементарные логические события, встречающиеся с одинаково высокой (низкой) частотой в различных классах.Авторы WizWhy акцентируют внимание на следующих общих свойствах системы:
В качестве достоинств WizWhy дополнительно отмечают такие:
Для убедительности авторы WizWhy противопоставляют свою систему нейросетевому подходу и алгоритмам построения деревьев решений и утверждают, что WizWhy, обладая более высокими характеристиками, вытесняет другие программные продукты с рынка
Data Mining. Стоимость системы около $ 4000, количество пользователей » 30000.Ключевые “смелые” утверждения разработчиков о свойствах системы достаточно легко опровергнуть с помощью наших двух тестов на умение решать простейшие задачи и способность находить наиболее полные и точные логические правила.
Так, система WizWhy “категорически отказывается” находить какое-либо логическое правило в тесте 1. Это связано с неадекватностью утверждения об “Определении наилучшей сегментации числовых переменных”. Здесь совершается классическая ошибка, связанная с непониманием того, что “часть не есть целое”. Разработчики стремятся найти наилучшее разбиение количественных признаков на интервалы, рассматривая каждый признак изолированно от всей системы признаков. А в тесте 1, как уже указывалось, признаки Х1 и Х2 по отдельности не представляют абсолютно никакой ценности для разграничения крестиков и ноликов.
В тесте 2 система WizWhy сумела найти только одно более или менее полное логическое высказывание, которое правильно относит к классу К 52 из 53 покрываемых объектов (записей):
IF (a2 = B)
и (a6 = B) и (a7 = A) и (a34 = B) и (a61 = A) THEN класс = K.Причина очевидной оплошности системы здесь кроется в том, что она способна находить логические правила, содержащие не более 6 элементарных событий. Это, собственно говоря, и есть ограничение “ограниченного перебора” в действии – в рассмотренном тесте требуется найти заданные экзаменатором логические правила, включающие до 15 элементарных событий (
ai = A или B).Также следует отметить, что процесс поиска логических закономерностей сильно растянут во времени. В частности, выдачи результатов решения теста 2 на компьютере
Intel Pentium III 733 МГц пришлось ожидать более 3 часов. Кроме того, система WizWhy помимо одного ценного правила, которое было приведено выше, выдала “в нагрузку” несколько тысяч правил, обладающих существенно более низкими точностью и полнотой.Эволюционные алгоритмы
Многие исследователи видят путь развития аналитических методов в разработке эволюционных алгоритмов. Среди них наиболее популярными являются генетические алгоритмы
, пытающиеся моделировать механизмы наследственности, изменчивости и отбора в живой природе.Первый шаг при построении генетических алгоритмов
– создание исходного набора комбинаций элементарных логических высказываний, которые именуют хромосомами. Все множество таких комбинаций называют популяцией хромосом. Далее для реализации концепции отбора вводится способ сопоставления различных хромосом. Популяция обрабатывается с помощью процедур репродукции, изменчивости (мутаций), генетической композиции. Наиболее важные среди этих процедур: случайные мутации в индивидуальных хромосомах, переходы (“кроссинговер”) и рекомбинация генетического материала, содержащегося в индивидуальных родительских хромосомах (аналогично гетеросексуальной репродукции), и миграции генов. В ходе работы процедур на каждой стадии эволюции получаются популяции со все более совершенными индивидуумами.Генетические алгоритмы привлекательны тем, что их удобно распараллеливать. Например, можно разбить поколение на несколько групп и работать с каждой из них независимо, обеспечивая время от времени межгрупповой обмен несколькими хромосомами. Существуют также и другие методы распараллеливания генетических алгоритмов.
Вместе с тем, эти алгоритмы на сегодняшний день не лишены серьезных недостатков. В частности, процесс создания исходного набора хромосом, критерии отбора хромосом и используемые процедуры являются эвристическими и далеко не гарантируют нахождения “лучшего” решения. Как и в реальной жизни, эволюцию может “заклинить” на какой-либо непродуктивной ветви. И, наоборот, можно привести примеры, как два неперспективных родителя, которые будут исключены из эволюции генетическим алгоритмом, оказываются способными через несколько итераций произвести высокоэффективного потомка. Это становится особенно заметно при решении высокоразмерных задач со сложными внутренними связями.
Указанные недостатки
не позволяют пока говорить, что генетические алгоритмы составляют сегодня серьезную конкуренцию деревьям решений и алгоритмам ограниченного перебора при решении задач поиска логических закономерностей в данных. Они “капризны” в настройке и трудоемки при решении задач поиска логических закономерностей в данных.Резюме
1. Наиболее популярные аналитические инструменты
Data Mining в ряде случаев оказываются не способны решать даже простейшие задачи.2. Применяющиеся подходы к обнаружению знаний в базах данных выявляют лишь усеченные фрагменты истинных логических закономерностей.
3. Известные системы для поиска логических правил не поддерживают функцию обобщения найденных правил и функцию поиска оптимальной композиции таких правил. Вместе с тем, указанные функции являются весьма существенными для построения баз знаний, требующих умения вводить понятия, метапонятия и семантические отношения на основе множества фрагментов знаний о предметной области.
Таким образом, результаты применения современных аналитических инструментов неполны, обрывочны и представляют собой лишь осколки знаний.
Экспресс-Электроника, 2002, № 6, С. 60-65.
| Site of Information
Technologies Designed by inftech@webservis.ru. |
|