Каталог >> ИИ >> ИНФОРМОДИНАМИЧЕСКИЕ ОСНОВЫ ОРГАНИЗАЦИИ УПРАВЛЕНИЯ ПРЕДПРИЯТИЯМИ И ХОЛДИНГОВЫМИ КОМПАНИЯМИ |
Глава 5. Определение информации
5.1. От бесконтекстности сигнала к контекстной зависимости языка
Итак, в любом разговоре об информации традиционно предлагается ситуация, когда некоторое состояние материи, обязательно воспринимаемое какими-либо человеческими чувствами или физическими приборами как сигнал, через носитель передается в воспринимающую систему. Там оно должно быть алгоритмически оценено, учтены статистические закономерности и шумы. Этим начинается и кончается классический вариант количественной теории информации, гораздо лучше звучащей в ее Шенноновском наименовании как “математическая теория связи”.
Конечно, для корректности восприятия иногда предлагается сравнивать такого рода “информационный” сигнал не только с его возможной копией в приемнике (для выяснения, несет ли он в себе информацию), но и с тем, что имеет получатель в виде опыта своего существования (накоплений в базе), а также априорно учитывать особенности конкретного источника сообщения.
При этом то, что в обыденной жизни называется контекстом восприятия сообщения фактически игнорируется. Считается, что приемник обходится алгоритмической интерпретацией априорно предписанной для всех допустимых сообщений.
Что дает такой подход при создании “информационной науки на базе компьютера”? Он позволяет оставаться на так называемом “твердом фундаменте” математического моделирования языков сообщения, восприятия и обработки сигналов. При этом обеспечивается чисто алгоритмический уровень контакта передающей и приемной систем, а алгоритмический выбор контекста, приписываемого сообщению (достаточно ясно, что все контексты восприятия в приемнике изначально существуют независимо от самих сообщений), принудительно сводит процесс общения до уровня контекстно-независимого языка вычислительного алгоритма.
Для создания автоматической алгоритмической (то есть контекстно-ограниченной) управляющей системы всего этого вполне достаточно. Но для системы, информационно обеспечивающей принятие решений в организационно-сложных объектах – нет.
Информационная наука при указанном выше подходе позиционирует себя на уровне языков бесконтекстных, а именно таких, где свободная контекстная интерпретация сообщений, подменяется их представлением на уровне восприятия заранее заложенного алгоритма. Там, где ничего кроме предписания для трактовки сообщения (алгоритма) нет, нам предлагают искать количество информации, контекст и семантику прямо в сообщении.
Повторяется классическая история начальных времен кибернетического управления, когда утверждалось, что “запрограммировать можно все…, но трудности, возникающие на этом пути, значительно превышают наши возможности”. Беда не в том, что, заменяя кибернетику информатикой, забывают это, а в том, что было написано “значительно”.
Трудности адекватного моделирования систем с собственным контекстно-зависимым языком не “значительно превышают”, а абсолютно непреодолимы на алгоритмическом уровне, на уровне программирования даже на самом мощном из программистских языков, который когда-либо будет придуман для компьютера фон Неймановской архитектуры.
Обратите внимание, хоть речь и не о моделях, а об информации, но “все о том же самом”. В первой части мы показали, что различные подходы старательно пытаются уйти от модельного представления, в частности, ориентируясь на информационные потоки и связи. Обратившись к информации в ее стандартном понимании, мы видим все то же самое – алгоритмическая интерпретация, количественные оценки, предписанный контекст сообщения – стоило ли уходить от модельного подхода?
Возможно, начиная отсюда, читателю станут более понятными наши утверждения о необходимости информационного обеспечения организационного управления некоторой “другой” информацией, учитывающей проблему индивидуальной интерпретации сигналов в приемниках, неважно, будь то человек или иная система, с реакцией через накопленный образ. Оставим бесконтекстное, алгоритмическое понимание информации для computer science (по своему определению эта область использует только контекстно-независимую машину) и обратим внимание на то, что же все-таки передается сигналом, кодовыми посылками любого вида. Этими посылками могут передаваться только результаты измерения или описания некоторым датчиком физических или иных (например, виртуальных) свойств объекта, в пределах возможностей его наблюдения или конструирования этим самым датчиком.
Терминология, ситуация, все построения такого рода не требуют введения отдельного понятия информации – вполне достаточно говорить о сигналах, сообщениях, данных, актуализации данных и т.п. Базы данных и даже базы “знания” в этом случае можно не называть информационными - ничего плохого при этом не случится.
Казалось бы, создавая любое текстовое или, в общем случае, знаковое сообщение, система высокого уровня или человек тоже выступают в роли датчика, – это все равно будет физическая посылка, ничем не отличающаяся от всего предыдущего.
Однако нет. Существует основное отличие всех таких сообщений от сигналов датчиков – они могут быть сделаны только после выработки в “контекстно-зависимой, не алгоритмической машине”, каковой является мозг (И, хоть и в меньшей степени – совокупность “накопленного опыта” и внутренних связей в сложной системе, включающей в себя человека, как составную часть (в социальном институте).), множества вариантов интерпретации входного сообщения и выбора наиболее приемлемого из них. Только после этого на основе проведенного выбора формируется собственно сообщение, причем не важно какую внешнюю форму оно обретет – контекстно-независимую (программную) или контекстно-зависимую.
Внутренняя проблема обязательной контекстной привязки сообщения, обязательность использования контекстно-зависимого языка характерна для сложных объектов живого мира, является их неотъемлемой сущностной характеристикой в такой степени, что с потерей контекстно-зависимого мышления и общения личность распадается (То же мы должны сказать и о социальных институтах), исключается из класса особей своего вида. Все слепые, глухие и т.п. особи являются хоть и ограниченно, но жизнеспособными в социуме, пока могут исповедовать какой-либо язык или его подмножество из класса контекстно-зависимых. Ни один социальный институт не сможет существовать на уровне чисто алгоритмического функционирования.
Владея контекстно-зависимым языком, воспринимая все посылки только как контекстно-зависимые (ибо контекст приписывается человеком всегда и всему – это один из важнейших моментов для наших дальнейших рассуждений) и будучи способным к разработке только контекстно-независимых языков (Ни эсперанто, ни воляпюк исключениями не являются – это заимствования.), человек как-то не задумался об их реальном соотношении, считая, что его язык “по определению” универсален.
В частности и из-за этой способности все наши науки, включая все виды управления, сегодня целиком базируются на моделировании. В идеале общепринятого процесса модельного познания, формализованное представление научного знания должно было бы иметь язык вообще бесконтекстный - просто по сути понятия формализованности. Однако все попытки свести науку к чисто формализованному, бесконтекстному языку регулярно проваливаются.
Только постепенно исследователи начинают понимать, что такой подход хорош для замкнутых кибернетических разработок и абсолютно неприемлем для исследования объектов класса “живого”, с собственным языком контекстно-зависимого уровня.
Обратите внимание: “живые” объекты реальной Природы без контекста как конструкции их языка (конструкции, но не свойства!), без процедуры выбора контекста для каждого пришедшего сообщения, то есть без явления выработки разъяснения (information) “для самих себя”, обеспечивающего согласованный процесс общения, не представимы.
5.2. Проблемы выработки определения информации
Контекстность, будучи конструкцией языка, существует только как никогда не прекращающийся процесс подтверждения правильности понимания и выявления отличий этого понимания в непрерывном контакте взаимодействующих систем с неограниченным развитием предмета обсуждения и уровня его описания.
Для этого нужен механизм порождения на каждом шаге множества возможных контекстов, явление, заключающееся в формировании или наличии и запуске в работу в приемнике некоторой “машины, производящей контексты и обрабатывающей их на предмет текущей приемлемости”. Каждое сообщение, полученное из канала связи на вход такой машины, является стартовой командой для ее запуска в новых условиях, с учетом всего прошлого диалога.
Ясно, что в общем случае это должна быть машина контекстно-зависимая, не опирающаяся на вычислительные, априорно предусмотренные алгоритмические процедуры.
При чисто алгоритмическом подходе к восприятию сигнала, контекста как такового нет. Он заменен предписанной ограниченной машинной интерпретацией некоторых сообщений и восприятием всего остального как “шума”. Следуя традиционному пониманию информации, входной сигнал после машинной алгоритмической обработки можно назвать результатом “измерения некоторого свойства”, полученным от датчиков, “статическим разъяснением”, “сигнальной информацией”.
Иначе говоря, в классическом подходе нам предлагается сообщение, разрешенное к интерпретации без процесса уточнения контекста взаимодействия источника и приемника, то есть односмысловая фактографическая “информация”, полученная после интерпретации входной посылки по заранее предусмотренному алгоритму и пригодная только для ограниченного использования при модельном подходе. По сути, это “нормированная, априорно предусмотренная трактовка для всех возможных сообщений” - псевдосемантика или модель уже не с основными, а алгоритмически предписанными свойствами, априорно соотнесенными не с текущей, но некоторой алгоритмически предусмотренной ситуацией.
Соответственно, в принципе нельзя описать контекстно-независимо ничего, кроме замкнутых систем со всей их замкнутой, предписанной выбранной моделью динамикой. Сегодня во многих случаях сигнально-модельного варианта понимания информации вполне достаточно для построения инженерных подходов “компьютерного толка”. Фактически же все сигнальные построения на контекстно-независимом языке нужно понимать как “алгоритмическое приписывание наиболее вероятного контекста” в процессе обработки сигнала.
Однако такого рода “контекст” может существовать в приемнике не только как фактографический, но и как структурный алгоритм интерпретации сигнала, который в таком случае претендует уже на восприятие его как сообщения. Сигнал, несущий в себе структуру связей (как разъяснение о желаемой отправителем трактовке сообщения) – тоже продукт мира контекстно-независимых языков, мира “алгоритмически предопределенного контекста”.
В классическом подходе к созданию проектируемых баз данных разработчики занимаются именно таким априорным выделением структур некоторой проблемной области для обеспечения “подходящей” трактовки входных сигналов. В каком-то смысле тому, что подразумевается под контекстом в алгоритмической системе, здесь отводится больший простор для существования. Выбор трактовки существует не в единой интерпретации, навсегда заданной алгоритмом, но в интерпретациях, заданных предыдущими сообщениями при наполнении жесткой структуры предопределенных взаимосвязей.
Под влиянием накопленных данных алгоритм функционирования “обрабатывающей машины” – компьютера может вырабатывать другой набор контекстов восприятия входного сигнала. При этом возможный выбор контекста изменяется, но все эти изменения при контекстно-независимом языке всегда существуют только в пределах алгоритмического подхода. По аналогии с предыдущей ситуацией, такой уровень можно называть уровнем явления возникновения сообщения с предписанной “динамикой интерпретации”, с адаптацией, предписанной при проектировании структуры модели.
Строго говоря, в обоих указанных выше случаях при использовании компьютера для обработки входного сигнала и выработки ответной реакции нет и не может быть никакой информации, никакого “разъяснения”.
Содержащиеся (заложенные) в модели или алгоритмическом описании сведения, ни свойством, ни явлением быть не могут. Каждый новый факт интерпретации входного сообщения - это просто “ранее не востребованная, но алгоритмически предусмотренная” запись и не более того в жестких рамках бесконтекстного языка или модели представления.
Фактически это “некро- или псевдоинформация”, выбор алгоритмически заложенного в модель решения, жесткое следование команде, заложенной в сигнал, каким бы завуалированным под семантику способом она не была замаскирована. Тем не менее, для данного случая определим информацию как явление алгоритмического порождения некоторого контекста из возможных, за счет накопленного “опыта” обрабатывающего компьютера.
Такое допущение полезно для обеспечения преемственности, связки между сигнальным и феноменологическим пониманием информации, благодаря чему далее, без разрушения сложившихся стереотипов, становится понятнее явление порождения информации в тех случаях, когда этим занимаются системы с контекстно-зависимым языком.
Именно порождение некоторого множества трактовок входного сообщения (внешне не всегда явно связанных с этим сообщением - далекие и абстрактные аналогии, эвристики, догадки, открытия), на которых базируется выработка решения или ответного сообщения и есть явление порождения информации. Само же ответное сообщение, текст, управление на основе выбранной интерпретации входной посылки, выбранного контекста восприятия, является только сигналом, некоторой производной явления информации.
Здесь мы договариваемся, что под “явлением информации”
, “информацией как явлением или феноменом” и “явлением порождения информации” мы будем понимать строго одно и то же. В принципе, можно говорить отдельно о порождения информации как процедуры порождения множества трактовок восприятия и реакции на входной сигнал, и отдельно – о явлении информации (феномене информации, информации как явлении), как о некотором механизме возникновения и функционирования контекстно-зависимой машины, имеющей более чем интересные собственные свойства.Возможно, в будущем будет признана целесообразной отдельная терминология, но для наших текущих потребностей восприятия информации как некоторой сущности, такое соглашение вполне допустимо.
Из сказанного проистекает другой подход, необходимость в котором возникает, когда мы попадаем в мир организационного управления, где моделирование зачастую противопоказано или просто невозможно. Ведь мы можем только предполагать, что именно должно быть представлено в модели некоторой ситуации, исходя из опыта аналогий, но не более того и без надежды, что неучтенное не было самым главным. Именно поэтому окружающий нас мир построен как множество вложенных контекстно-зависимых процессов, взаимодействие которых
мы часто не успеваем воспринять или выделить его существенные стороны.Поэтому для существования
homo sapiens и социальных институтов необходимость в моделях Природой не предусмотрена (но не для технического уровня деятельности!), все основано на текущем взаимодействии с открытыми системами, для чего и нужен только контекстно-зависимый язык.Вообще процесс познания в полной мере возможен только для видов, существующих с собственным контекстно-зависимым языком, контактирующих с окружающим миром “напрямую”, без модели, работающих с “накоплением образа”.
Здесь обычно выдвигается возражение о том, что образ это и есть модель. Нет, образ, накапливаемый в живой системе, существует только в представлении контекстно-зависимом, в представлении, исключающем использование для его формирования любых механизмов, ниже уровня абстрактной машины Тьюринга.
Процесс же познания “через модель” суть процесс познания и создания объектов кибернетических, объектов “неживого Мира” и порождений человека техногенной цивилизации, процесс познания на уровне рассмотренной выше “псевдоинформации”.
Ясно, что к биологическим и вообще живым системам кибернетический, модельный подход имеет только косвенное отношение при механистическом изучении живых объектов. Строго говоря, это изучение живого, воспринимаемого как мертвое, где уже вполне годятся машины фон Неймановской структуры.
Явление порождения информации, феномен информации обеспечивает существование Природы как открытой системы, как совокупности таких систем и объектов в них, существование которых принципиально невозможно иначе как систем, находящихся в контекстном взаимодействии и не могущих без сущностного разрушения перейти к существованию на языках контекстно-независимых.
Таким образом, мы пришли к необходимости существования в Природе явления порождения “информации живого”, информации, обеспечивающей существование объектов контекстно-зависимого уровня, объектов с целенаправленным поведением, с некоторой свободой выбора решений в окружающем их мире взаимодействующих систем, а значит и с собственным механизмом выработки множества контекстов восприятия входного сообщения.
Ясно, что процесс совместного существования систем обеспечивается не только правилами их конструирования, но и инструментарием - уровнем и возможностями их собственного контекстно-зависимого языка. Явление информации - явление технологическое, требующее (просто по факту своего существования с перечисленными особенностями) наличия в Природе (в каждом ее объекте, существующем на уровне живого) контекстной информационной динамической машины как механизма и принципа порождения информации.
Перейдем от понятийно-пояснительного изложения явления информации к более точным его определениям.
5.3. Информация обыкновенная, сигнальная
Начнем с информации сигнальной, то есть той, которую в принципе можно “инициировать как контекст” восприятия сообщения в приемном алгоритмическом устройстве за счет передачи сигнала по каналу связи от некоторого источника. Следы этой информации как алгоритмической трактовки, выраженной в ответном сообщении, и являются предметом изучения количественной теории информации. Это дает нам право предложить именовать такого рода алгоритмически инициированную информацию информацией обыкновенной (
informatio vulgaris).При изучении явления возникновения информации нас интересует, конечно, не сигнал, объявленный в существующей теории информации “носителем сообщения или информации”. Ничего он в себе кроме изменения некоторой физической величины нести не может. Интересен здесь только механизм и способ выявления из изменений входного сигнала того, что в них заложено - данных для запуска алгоритма выбора интерпретации.
Явление возникновения информации обыкновенной – это явление, сущность которого выражается в возможности порождения на стороне приемника из сигнала, как входной фактографической посылки, некоторого дополнительного синтаксически правильного и семантически значимого построения, обеспечиваемого за счет алгоритмически предусмотренных процедур обработки сигнала.
Для реализации этого явления необходимо наличие в приемнике обыкновенного компьютера или даже конечного автомата – бесконтекстной машины, в которой реализуются упомянутые процедуры выработки “псевдосемантического построения”. Естественно, это построение возникает не само по себе, не самостоятельно, а только в соответствии с предусмотренными разработчиком алгоритмическими возможностями. Именно поэтому в предыдущем разделе мы назвали это информацией фактографической, обыкновенной и предложили считать полученное информацией “условно” – нижним уровнем, вырожденным случаем при построении некоторой иерархии “информаций” различного уровня.
Как пример, здесь можно привести интерпретацию сигналов от удаленных космических источников, чью сущность мы можем представить себе только исходя из принятых физико-математических предположений. Сюда же относится интерпретация сообщений типа “Над всей Испанией безоблачное небо” или интерпретация сообщения Центрального банка об установлении, скажем, стабильного курса рубля.
Для всех сообщений такого рода выбор контекста предписан ранее достигнутыми соглашениями алгоритмического, контекстно-независимого уровня. Для тех же, кто его не знает, семантика (прагматика) после обработки сообщения будет либо искажена, либо вообще не воспринята, то есть возможно и произойдет явление выработки указанного выше построения, но не имеющего, в общем случае, значимой опосредованности в реальном мире.
И вообще все входные сообщения фактографического плана могут быть интерпретированы, независимо от любого уровня их собственного языка, только на уровне языка приемника. Мы никогда не сможем осмысленно воспринять никакой сигнал ни от сверхпримитивного, ни от сверхразвитого разума, если не сможем подобрать хоть какой-нибудь доступный нам контекст интерпретации сообщения
(Вспомните необходимость трактовки поведения животных или НЛО через доступные человеку понятия – иначе их поступки объяснить невозможно, а какую гарантию разумности этих трактовок мы имеем? Да только псевдовероятностную – “так обычно бывает”, спросить не удается, ибо язык не позволяет, а рефлексами все не опишешь. ).В соответствии с принятым определением
informatio vulgaris – алгоритмическое семантическое построение над сигналом и, следовательно, в количественном измерении не нуждается. В этом смысле можно дать еще одно определение такой информации, равноправное с предыдущим. Можно сказать, что это явление, заключающееся в том, что некоторый сигнал, полученный на любом языке, воспринимается как программа (или данные к заранее разработанной программе) для последующего однозначного формирования контекста его восприятия, причем в разных приемниках, в зависимости от заложенного в них алгоритма, выбор контекста может быть различен.Выбор контекста восприятия алгоритмически предопределяет интерпретацию сигнала и возможное ответное сообщение. Также ясно, что
informatio vulgaris и контекст в этом случае не различимы, что мы и должны были получить. Алгоритм порождения контекста “убил” все, что связано с механизмом (явлением) порождения множества контекстов и выбора из них предпочтительного (свободой выбора), не дал возникнуть явлению информации как таковому, заменив его выработкой предписанного контекста восприятия как “псевдоинформации”.Сигнал может существовать и в некотором диапазоне значений – тогда это уже полноценная система управления. Она образуется с момента включения сигнала (и привнесенной им “семантики”), в контур обратной связи в приемнике сообщения. Возникает управляющее действие порожденной таким образом информации и, соответственно, понятие явления порождения информации обыкновенной ни в чем не противоречит существующим модельным подходам к управлению.
Конечно, не надо забывать, что в столь примитивных случаях понятие информации вообще не нужно (что теория автоматического регулирования и подтверждает, прекрасно обходясь в своих базовых основах без понятия информации). Нас же оправдывает только желание выполнить индуктивное построение для всех ситуаций “возникновения машин порождения сущности, не присутствовавшей во входной посылке”, желание “не революционного, а эволюционного перехода науки” от количественной теории к феноменологии.
5.4. Информация объектная, бесконтекстная
Продолжим рассмотрение возможных вариантов “псевдоинформации” и перейдем к рассмотрению бесконтекстных сообщений документографического уровня, имеющих в несущем сигнале некоторые сведения о своей изначальной структуре. Здесь, как и в прошлом случае, сообщение может нести в себе только то, что необходимо для запуска интерпретирующей машины приемника. Все, что возможно при этом получить, “уже заложено алгоритмически” в сообщение и более не уточняется при интерпретации в приемнике.
Такого рода вариант пассивной обработки сигнала предопределяет приемник как “объект”, некоторую пассивную сущность “терпящую познание”, и противоположную активной сущности “субъекта”. Соответственно, информация, вырабатываемая в объекте, может быть названа объектной (
informatio objecta).И здесь, также как и в предыдущем случае нас интересует, конечно, не столько прямой текст входного сообщения, а все то, что впрямую (на языке сообщения) в этот текст не заложено и, кроме того, все, что имеется в этом тексте, прямо и косвенно указывающее на его структурное построение.
Явление возникновения информации объектной – это явление, сущность которого выражается в возможности порождении на стороне приемника из сигнала, воспринимаемого как структурированная посылка, некоторого построения, имеющего синтаксически правильную и семантически интерпретируемую структуру, обеспечиваемого за счет алгоритмически предусмотренных процедур восприятия структурированного сигнала.
Для реализации этого явления необходимо наличие в приемнике компьютера фон Неймановской структуры, в котором реализуются упомянутые выше алгоритмы с некоторым программным добавлением – заранее спроектированной базой данных и системы управления ею (БД и СУБД).
Отличием такой конструкции от предыдущего случая является алгоритмически предусматриваемый выбор контекста интерпретации сообщения из набора предусмотренных случаев, или даже расширение этого набора в процессе существования системы. Но, конечно, последнее тоже реализуется чисто алгоритмическими средствами.
Поэтому и здесь все построения являются построениями программно-автоматными, т.е. построениями, работающими по раз навсегда заданной процедуре выбора “псевдосемантического решения”, хотя и довольно сложным путем, который по существующей традиции относят к адаптивным или “интеллектуализированным” построениям.
Как пример, здесь можно привести любые справочные системы, содержащие структурированные, например, реляционные базы, занимающиеся автоматической обработкой поступающих текстовых сообщений. Фактическая процедура такой обработки всегда без исключений выглядит следующим образом.
Входной текст алгоритмически интерпретируется с целью уложения его в существующую структуру хранения имеющейся базы. Далее этот текст сравнивается с сообщениями, имеющими близкую структуру и терминологию, что эквивалентно механистическому подбору не только похожих сообщений, но и контекста восприятия, задаваемого сравнением сообщения с тем или иным хранимым текстом. В некоторых случаях, например, при задании поискового образа, фактически задается принудительный вариант интерпретации сообщения.
Все это, конечно, в информационном смысле мало отличается от предыдущего случая, и все, что выше сказано о явлении порождения информации практически один к одному (кроме расширения выбора интерпретаций за счет структурных возможностей базы) распространяется и на этот случай, включая и рассуждения об управлении.
Так же как и в прошлом случае можно дать еще одно определение
informatio objecta, равноправное с предыдущим. Можно сказать, что это явление, заключающееся в том, что сигнал рассматривается как некоторая структура из диапазона предписанных структур и воспринимается как программа (или данные к заранее разработанной программе) работы некоторой алгоритмической машины порождения информации (Машины, порождающей множество свободных интерпретаций (интерпретаций не ограниченных глубиной или логикой ассоциации) на основании команды и данных, которыми является входной сигнал.) для последующего автоматического выбора или конструирования контекста восприятия сигнала, причем в разных приемниках и контекст, и выбор могут быть различны.На уровне выбранного контекста формируется решение по интерпретации полученного сообщения, после чего возникают условия для алгоритмической выработки ответного текстового сообщения.
В связи с тем, что какой-то из контекстов по заданным характеристикам (структуре, терминологии, поисковому образу, “эстетичному виду” наконец) всегда будет существовать, интерпретации, в принципе, могут быть подвергнуты любые сообщения. Это определяет переход во всех “информационно-поисковых” системах от понятия сигнального шума (помех) к шуму, определяющемуся выработкой ложного сообщения при неверном определении изначального контекста сообщения, то есть к тому, что можно назвать информационным шумом. Естественно, что это производится при условии оценки шума на уровне внутренних преобразований в базе, а не по выработанному текстовому ответу на входную посылку.
В последнем случае это будет уже не информационный шум, а просто неправильная трактовка входного сообщения, для уточнения которой был бы полезен некоторый цикл общения приемника и передатчика сообщения. Но это уже прерогатива устройств порождения и использования информации следующего уровня сложности. Перейдем к ее рассмотрению.
5.5. Информация субъектная, контекстно-зависимая
Все изменяется, когда во взаимодействии участвует человек с его неизбежной интерпретацией всех сообщений (даже полученных на контекстно-независимом языке) как контекстно-зависимых. В этом случае начинается действие того самого “неисчислительного” механизма, о существовании которого говорили уже достаточно давно [41] и сегодня наиболее близко к которому в биологическом смысле, возможно, подошел английский ученый Р.Пенроуз [35]. Он предложил комплекс согласованных гипотез физики и нейрофизиологии, направленный на выяснение возможностей существования в живом некоторого процесса невычислимости, что можно воспринимать как указание о возможности существования в природе принципиально неалгоритмических процессов.
Эта работа для нас важна, прежде всего, тем, что показывает подлинную область интересов при работе с интересующими нас сложными системами уровня живого. Дело в том, что многие факты, связанные с анализом процедуры обработки сообщений, указывают на то, что при участии человека во взаимодействиях друг с другом или с машинным сигналом, в процесс обработки со стороны человека, включается машина иной структуры, нежели привычный для нас компьютер. Ее собственным языком является язык контекстно-зависимый, то есть и с этой стороны представляется необходимым создание машины заведомо не алгоритмической
, не вычисляющей.В отличие от всех предыдущих случаев, явление порождения информации здесь абсолютно естественно и является неизбежным атрибутом взаимодействия. Процесс общения между системами с контекстно-зависимым языком или такой системы с системой алгоритмической упрощенно выглядит следующим образом.
На вход приемника поступает сообщение на языке передатчика, которое со стороны “живой” системы всегда выглядит как сообщение контекстно-зависимое. Как мы уже говорили, даже запись программы выглядит для человека контекстно-зависимой, ибо независимо от нашей воли, мы всегда оцениваем ее и по авторству, и по смыслу применения, и по источнику поступления, и по многим другим параметрам “не программистского толка”, прежде чем согласимся на ее содержательное прочтение.
Как мы уже говорили, никакое сообщение семантики в себе не содержит, даже если в нем написано, что оно семантическое. Вся семантика возникает только внутри обрабатывающей машины, а входное сообщение (для простоты будем считать, что оно текстовое, но это не является ограничением общности рассмотрения ситуации) для нас существует только на уровне синтаксиса.
В этом смысле интересно было наблюдать работу группы профессиональных программистов, взявшихся построить “семантическую” систему. Было предусмотрено все возможное и невозможное для организации анализа текста на уровне синтаксиса и морфологии, но семантику как таковую из самих сообщениях выделить так и не удалось – все время приходилось привлекать “знание извне”, интерпретацию в привнесенном контексте.
При этом даже небольшое изменение в тексте сообщения обычно вело к требованию дополнительного ввода в машину огромных объемов информации. В пределе явно требовалось заложить сведения “обо всем”, что очень показательно для оценки требований к конструкции информационной машины.
Возвращаясь к обработке сообщения, укажем, что в результате работы “внутренней машины” человека (также как и в рассмотренных выше случаях выработки псевдоинформации) в ней появляется множество вариантов интерпретации текста сообщения, из которых делается выбор, после чего формируется текст ответного сообщения.
Внешне он на том же контекстно-зависимом языке, но, по сути своей, это сообщение на уровне чистого синтаксиса. Вся псевдосемантика (в “машинном” собеседнике) или естественная (в случае контакта с “живым”) появляется только при внутренней обработке. Далее вырабатывается ответное сообщение того же “синтаксического” уровня и цикл общения может продолжаться неограниченно долго.
Будем называть указанный процесс “информацией активной”, ибо мы рассматриваем случай, когда выработке контекста восприятия сообщения сопутствует процесс предопределения выбора интерпретации за счет учета уже полученных сообщений и процесс “переспроса источника сообщения” с целью уточнения правильности восприятия. Такая информация может быть названа по определению понятия субъект – “носитель активности”, субъектной (
informatio subjecta).Теперь, по всей видимости, становится понятным, почему никак раньше не удавалось вразумительно определить информацию – да просто определение приписывали к тому месту “информационного процесса” где ее нет “по определению”, к тому месту, где от явления информации остался только количественный след, что и вело к построению “количественной теории информации” без определения информации как таковой..
Вся информация как явление существует внутри информационной машины и никуда, в общем случае, из нее не уходит. Уходят сигнал, сообщение, “программа запуска” информационной машины собеседника и вот им-то можно приписывать любые количественные характеристики как явлениям измеримым.
Соответственно, вся “информационная негэнтропия” остается “внутренним” атрибутом машины выработки информации и к конкретному выработанному сообщению отношение имеет только косвенное. Отсюда следуют все понятные выводы для творцов “информационно-энергетического баланса”.
Сегодня в любой книге информационно-системного толка, например [29], модно писать что-нибудь вроде “эволюционного ряда” вещество – энергия – информация, или описывать “информацию, создающую в себе поле существования, суммарный поток которого адекватен этой информации, то есть материи, служащей источником поля”.
Конечно, свойство “замкнутости” явления порождения
informatio subjecta принципиально не отрицает существование информационного поля, но если оно и существует, то со свойствами, непривычными для энергетических полей. Именно поэтому можно достаточно обоснованно предположить, что замыкание энергетической энтропии на информационную негэнтропию в количественной теории информации не более чем такой же след сложнейшего явления, как количество информации в сигнале без определения термина информация. Но это сейчас лежит вне рамок нашего изложения материала.Достаточно сложные цепочки рассуждений и выводов работы [15] показывают, что явление информации надо рассматривать как генерацию под влиянием входного сигнала в аппарате внутреннего восприятия (информационной машине) того, “чего там не было заложено”, путем проведения множества построений сравнения полученного сообщения и накопленных в машине сведений. Причем, по ряду причин, можно достаточно уверенно утверждать, что строятся одновременно все возможные сравнения, причем и такие, которые не имеют опосредованности в реальном мире.
Из технических соображений можно показать, что это механизм обеспечения надежности работы такой сложной машины как мозг человека. По многим причинам информационная машина может реализовываться только как машина безадресная (Отсылаем читателя к [15], где приводится и эскизная схема и структура необходимого программного обеспечения и описывается проблема начального запуска такой машины. Заранее предупреждаем – это машина “другого порядка сложности”, нежели известные реализации вычислительных машин, но зато и “другого порядка возможностей”.). Именно этим можно объяснить фантастическую выживаемость мозга при самом тяжелом травматизме вплоть до потери одного полушария без заметного снижения работоспособности, как это, считается, произошло у Пастера.
Итак, когда общение идет на уровне контекстно-зависимого языка, на каждом шаге вырабатывается информации сколь угодно много, с ограничением этого процесса не столько по ресурсам, сколько по допустимому времени реакции, выработки актуального решения. Эта выработка осуществляется исходя из всех “технических возможностей” интерпретации сообщения
(Если кому-то уж очень хочется ставить вопрос о количественном измерении выработанной информации, то все такие оценки должны начинаться с “количества выработанных интерпретаций” в сравнении с “количеством интерпретаций, имеющих реальный смысл”, с тем, что понимается как множество вероятных контекстов. Правда опять возникнет проблема “семантической ценности” выбранного контекста относительно всех выработанных.Но человек и принятие решений в организационном управлении – системы и процедуры алогичные, иначе все сводилось бы к формальной логике и математике. Так стоит ли всем этим заниматься в количественном смысле?).
Из этого множества выбирается наиболее приемлемый вариант, на основании которого вырабатывается ответное сообщение, ответный сигнал. То есть сигнально распространяется не информация, не контекст, а только сам сигнал, текст сообщения.
А сообщения в этом смысле так и остаются управляющими, и здесь нет никаких противоречий с Винеровским подходом к роли информации, эквивалентной сообщению. Но теперь мы можем сказать уже точнее: информация (см. определение выше) это то, на основе чего вырабатывается текст управляющего сообщения для собеседника (приемника, бывшего передатчиком в момент отправки сообщения), самостоятельно принимающего решения о восприятия или не восприятии результатов запущенного ответом цикла работы своей информационной машины.
5.6. Аналитика, управление и интеллект
Фактически явление информации – это явление аналитическое, связанное с выработкой всех возможных интерпретаций полученного сообщения. Соответственно укажем, что задача обеспечения организационного управления это задача обеспечения аналитической работы, а само организационное управление – чистая аналитика в ее классическом понимании
.В случае применения всех предыдущих подходов, порождающих “псевдоинформацию, никакой аналитики не было, и быть не могло. Аналитика и алгоритмы интерпретации несовместимы
.В любой стандартной базе для поиска того, что на самом деле является не информацией, а сведениями, нам требуется все то же самое – формирование поискового образа как эквивалента входного сообщения для заложенного алгоритма его интерпретации. Шаг влево или вправо от точного формирования поискового образа ведет к непредсказуемым последствиям, а ведь чаще всего мы не можем точно сформулировать, что же мы ищем.
Управленец-аналитик для принятия решений ищет непредусмотренное, случайное, заранее неожиданное. Предусмотреть все остальное – дело соответствующих целевых служб. Как известно, постановка аналитического вопроса – уже более половины ответа на него.
Теперь мы имеем все необходимое для иллюстрации процесса возникновения информации в живых системах.
Начнем с рассмотрения рис. 5.1.
Как мы уже выяснили, входной сигнал является не более чем “программой запуска” обрабатывающей машины выработки информации – контекстно-зависимой интерпретации сигнала в мозгу человека. В компьютере с заложенным алгоритмом интерпретации сообщения никакого аналитического сообщения, никакой информации, ничего нового вообще не вырабатывается – существует только процесс актуализации априори предусмотренной алгоритмом трактовки полученного и не более того.
Поэтому все существующие решения по хранению данных в виде, пригодном для их последующего нахождения и использования, для аналитических задач абсолютно непригодны и пригодны не будут, пока мы не решим задачу творения информации по всем входным сообщениям не только в человеке, но и в машине, функционально примерно так, как это приведено на рис. 5.1. И, конечно, обратную задачу – выдачи вразумительного для человека сообщения по результатам этого внутримашинного процесса.
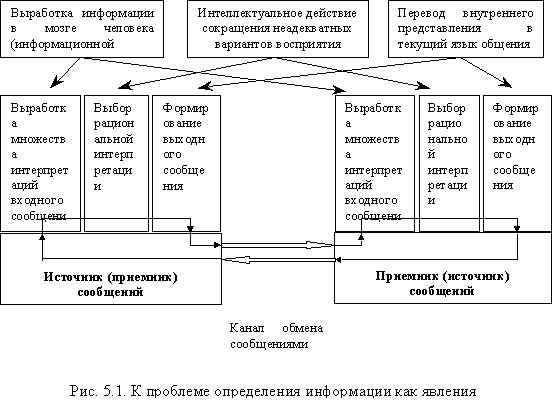
Последнее надо называть интеллектом по определению интеллекта в его общечеловеческом понимании, т.е. безотносительно его технической или биологической реализации. Понятие интеллекта обычно искажают до крайности и используют в основном для повышения рыночной стоимости разработки. Для нас указанный выше факт важен именно потому, что аналитическая информационная машина может быть только интеллектуальной или никакой – не по причине желания назвать ее красиво, но по сути поставленной перед ней задачи
(Для того, чтобы у читателя не сложилось впечатление, что все это имеет отношение только к биологическим системам, а для социального института неприменимо, специально поясняем. Ориентация изложения здесь на биологический вариант информационной машины просто кратчайшим путем ведет к пониманию феноменологический сущности информации. Вариант машины для иллюстрации аналогичного процесса на уровне социального института мы рассмотрим в главе 6, для чего нам и понадобится весь приведенный здесь материал.).Кстати, теперь вполне естественно утверждать, что хранилище информации, отнюдь не то, что объявил Бил Инмон (Хорошо известно, что широкая программистская общественность связывает идею создания и ведения больших баз под именем хранилищ (data warehouse) с именем Билла Инмона. Идея хранилищ по его замыслу состояла, в основном, в следующем.
Во-первых, предлагалось ориентироваться на предметную область, а не на специфику приложений, которые будут работать с этими данными. Это означает, что структура данных в хранилище должна отражать точку зрения корпоративного пользователя на совокупность информации, с которой ему приходится иметь дело. В хранилище следует помещать исчерпывающий набор данных, причем именно тех, которые могут пригодиться в процессе принятия решений.
Во-вторых, хранилище должно содержать интегрированную информацию, полученную на основе данных, поступивших в систему из множества источников. Причем интеграция – это объединение данных с приведением их к единому синтаксическому и семантическому виду. Необходимо проводить проверки на непротиворечивость, целостность данных и т.д.
В-третьих, база данных хранилища (напомним, под хранилищем в этом смысле понимается система баз данных) должна быть оптимизирована для выполнения операций поиска и чтения данных. Данные, пройдя предварительную обработку и попав однажды в хранилище, остаются там на долгие годы, причем внесение каких-либо изменений в данные (кроме дополнения) не предполагается в принципе – данные понимаются как самостоятельная ценность, накапливаемая годами и десятилетиями.
Как ни странно, мы видим здесь классическую концепцию склада. Правда, это рекомендации к созданию “хорошего склада”, с семантикой. Но мы уже знаем, что абстрактной семантики не бывает, как и не бывает семантической ценности информации. Также мы знаем, что “помещать” что-либо в базу может только поток информации, всегда содержащий в себе семантику трактовки конкретных данных, а, следовательно, и законы “помещения или не помещения” информации в хранилище.
Нет в концепции хранилища и понятия, оговаривающего необходимость реструктуризации связей данных в процессе их существования. И поэтому, мы не можем согласиться с утверждением, приводимым в той же статье: хранилище данных – это корпоративная версия истины. Истина (кроме, конечно, заповедей) всегда индивидуальна.
Каким же инструментарием, отвечающим нашим требованиям к ИСУ, мы располагаем на сегодняшний день? Обращаем здесь внимание читателя на давно известный в нашей стране подход к созданию того, что сегодня можно назвать “инструментарием для хранилищ знания”. Этот инструмент нам пришлось создавать еще при начале работ по проекту ТЕКРАМ [6]. Сегодня он существует в профессиональном варианте под названием qWORD [36]. ), и наши программисты с удовольствием повторяют, а, если такой термин вообще приемлем, то суть множество структурно-свободных баз (баз со структуризацией под контекст запроса), способных порождать информацию под воздействием входного сообщения в контексте той или иной задачи его интерпретации.
Вот на такой основе действительно можно непротиворечиво двигаться вперед и в область технических решений, и в область организации управления, и аналитических работ с использованием технических средств сегодняшней (чисто вычислительной) и завтрашней (информационно-динамической) архитектуры.
5.7. Обнаружение явления информации
Для подтверждения правильности наших построений постараемся ответить на вопрос: как же обнаружить явление информации? Исходя из нашей задачи изложения проблемы на достаточно популярном уровне, мы не будем привлекать для этого понятия информационных полей и прочих сложных аппаратов, тем более что их разработка все еще продолжается и возможны различные пояснения, варианты изложения совокупности новых теорий, имеющих прямое отношение к рассматриваемому явлению.
Предмет нашего рассмотрения настолько новый, что мы лишь укажем несколько ситуаций и проблем, которые практически свидетельствуют в пользу информации как явления.
Начнем с того, что жизнь и исследователи периодически осуществляют “проверку” человека на его изоляцию от внешних раздражителей – “каменные мешки” узников, одиночные камеры, специальные устройства изоляции от сигналов внешнего мира всегда ведут к деградации личности. С точки зрения информатики здесь имеет место изоляция личности от входного сигнала – “программы запуска” собственной информационной машины у изолированной личности. Это наводит нас на мысль, что существование биологического объекта, по крайней мере, высокого уровня сложности, невозможно без общения с себе подобными, в смысле необходимости регулярного обеспечения контекстно-зависимого контакта. Строго необходим достаточно частый “запуск” в работу мозга на уровне обработки внешнего сообщения.
В нашем случае это указание о том, что работа по созданию информации необходима человеку, так же как и удовлетворение всех его остальных физиологических потребностей. На справедливое замечание, что такого рода “информационное удовлетворение” может быть обеспечено и без общения с себе подобными – чтением книг, музыкой, размышлениями и так далее, укажем следующие обстоятельства.
Все “изолированные в природе”, так называемые “робинзоны”, деградировали в меньшей степени, чем узники, но деградировали как Айртон у Жюль Верна, но не как Робинзон у Д.Дефо. Колоссальная приспособляемость человека позволяет ему выживать в экстремальных условиях, но деградация, хоть и в меньшей степени, неизбежна и при изоляции в природе - при уменьшении воспринимаемого контекстного разнообразия, которое в максимальной степени возможно только с себе подобными. Известное понятие “одиночества в толпе” и его последствия для индивидуума также дают здесь пищу для размышлений.
Укажем и на ситуацию “маугли”, когда мозг, как машина порождения и анализа сообщений, формировался вне традиционной среды обитания. Никаких положительных сведений о последующем возвращении к разумной жизни в “своем биологическом виде” не существует. Если структура информационной машины, ее приспособленность к выработке контекстов не соответствовали изначально типичному миру биологического объекта некоторого вида, то после определенного периода развития (считается примерно после 3-5 лет), происходят необратимые фиксации самосознания и все контексты, которые мы хотели бы дать этому объекту позже, становятся шумом навсегда.
Чем ниже ступень иерархической лестницы биологического организма, тем проще переносит он проблемы изоляции - меньше проблем с начальным становлением и поддержанием в работе “собственной информационной машины”.
Все сказанное относится и к уровню социального института. Просто пока никто не разрабатывал этого вопроса и соответствующей терминологии, но попробуйте изолировать социальный институт, или занять его псевдоработой, вырастить в одной среде (например, социалистической экономики) и заставить работать в среде другой – все сказанное выше будет иметь место.
Возвращаясь к информационным аспектам, можно посоветовать обратить внимание на следующий факт. На первых двух уровнях сформированной нами выше иерархии информаций вполне можно вообще обойтись без самого этого термина и без общения с кем бы то ни было. Сигнал, сообщение, база, знание, актуализация и прочие аналогичные термины вполне покрывают своими областями определения такое понятие информации, причем покрывают точнее и смысл их применения здесь всегда технически полезнее, чем термина “информация”.
Но далее, для явления выработки множества того, что здесь приходится называть контекстами, научной терминологии нет. Однако с древних времен понятие информации как разъяснения впрямую говорило нам: разъяснение, множественность контекстов и проявление по своему осознанной реакции на сообщение является атрибутом, основной сущностью систем, способных к такому процессу.
Не может быть информации в “неживой” Природе - разъяснять некому, восприятие либо механистическое, либо алгоритмическое, а вот сигналов там может быть сколько угодно. Другое дело - где проходит граница между живой и неживой Природой, но уж систем технических это касается точно.
Можно еще вспомнить и о ментогенезе (Явление постепенной синхронизации работы отдельных “природных информационных машин”, переход от общества индивидуумов к обществу “одинаковомыслия” - процесс, хороший для иллюстрации свойств “природной информационной машины”, но вряд ли полезный для человечества в нашем сегодняшнем понимании пользы.
Ментогенез – это своеобразный Природный процесс организационного управления, заставляющий нас задуматься о том, что не только физикам и медикам надо помнить о последствиях их открытий. Оказывается и “типизация мышления” характерная для подобного варианта организационного управления может обеспечить человечеству множество неприятностей.) [15], но самый “простой” способ экспериментально обнаружить явление информации – построить саму информодинамическую машину. Да, это задача творения “личности нового вида”, со всеми вытекающими последствиями межличностных и межвидовых отношений. И здесь уже мы впрямую встречаемся с проблемами, по сравнению с которыми проблемы клонирования отходят на второй план (во всяком случае, взаимосвязь возможных неприятностей показана в [15]).
Как вывод по этому разделу еще раз укажем – без формирования науки о явлении выработки информации в “природных информационных машинах” во взаимодействии со всем кругом “наук о живом”, глобальное решение никаких перспективных проблем, в том числе и организационного управления просто невозможно.
Конечно, кое-что можно сделать уже и сегодня, чему мы и посвятим последующие главы.
| Site of Information
Technologies Designed by inftech@webservis.ru. |
|